Audio2Face-3D#
Set up a character for animation before adding Audio2Face-3D to your application.
System Requirements#
Remote Execution Requirements#
Windows:
64-bit Windows 10 May 2020 Update or later
- Linux:
64-bit Linux OS with libstdc++ version 6.0.30 or later
Ubuntu 22.04 or later
Fedora 36 or later
Debian 12.0 or later
Local Execution Requirements#
Windows:
64-bit Windows 10 May 2020 Update or later
NVIDIA Ampere-class, Ada-class, or Blackwell-class GPU
Audio2Face-3D local inference feature needs approximately 2.9 - 4.4 GiB VRAM or more depending on model
NVIDIA Ampere: NVIDIA GeForce RTX 30xx, NVIDIA RTX Axxxx, NVIDIA Ax GPU accelerator
NVIDIA Ada: NVIDIA GeForce RTX 40xx, NVIDIA RTX Ada Generation, NVIDIA L4x GPU accelerator
NVIDIA Blackwell: NVIDIA GeForce RTX 50xx
NVIDIA display driver 551.78 or later
Additional recommendations to get the best performance:
Display Hardware-accelerated GPU Scheduling (HWS) enabled via Settings > System > Display > Graphics > Change default graphics settings. See https://devblogs.microsoft.com/directx/hardware-accelerated-gpu-scheduling
NVIDIA Ada-class or Blackwell-class GPU
NVIDIA display driver 555.85 or later
Audio2Face-3D Connection Setting#
Changed in version 2.1: Added settings for NVCF API key, function ID, and function version.
The ACE Unreal plugin’s project settings have an option for setting the default Audio2Face-3D server to connect to: Edit > Project Settings… > Plugins > NVIDIA ACE > Default A2F-3D Server Config. The configuration has multiple fields:
Dest URL: The server address must include scheme (http or https), host (IP address or hostname), and port number. For example,
http://203.0.113.37:52000orhttps://a2x.example.com:52010(both fictional examples). To connect to NVIDIA Cloud Function (NVCF), set the server address tohttps://grpc.nvcf.nvidia.com:443.API Key: If you are not connecting to an NVCF-hosted Audio2Face-3D service, leave this blank. You can get an API key through https://build.nvidia.com/nvidia/audio2face-3d to connect to NVCF-hosted Audio2Face-3D services.
NvCF Function Id: If you are not connecting to an NVCF-hosted Audio2Face-3D service, leave this blank. You can get an NVCF Function ID through https://build.nvidia.com/nvidia/audio2face-3d to connect to NVCF-hosted Audio2Face-3D services. Click Try API and scroll all the way to the bottom of the page find the available NVCF Function IDs.
NvCF Function Version: Optional. Leave this blank unless you need to specify a specific version.
You can change the Audio2Face-3D connection settings at runtime by using
the ACE > Audio2Face-3D > Override Audio2Face-3D Connection Info blueprint
function, or by calling UACEBlueprintLibrary::SetA2XConnectionInfo
from C++.
You can fetch the current Audio2Face-3D connection settings at runtime by
using the ACE > Audio2Face-3D > Get Audio2Face-3D Connection Info
blueprint function, or by calling
UACEBlueprintLibrary::GetA2XConnectionInfo from C++. Current
settings are a combination of the project defaults and the runtime
overrides.
The project settings are stored in your project’s DefaultEngine.ini
file. If your API key is too sensitive to include in a project text
file, consider setting it at runtime using the Override Audio2Face-3D
Connection Info blueprint function.
Import Speech Clips#
Changed in version 2.4: Any loading behavior is now supported. Before version 2.4, only Force Inline loading behavior was supported.
The NVIDIA ACE plugin’s Audio2Face-3D feature supports animating a character from speech stored in Sound Wave assets. Any sample rate is supported as input. The clip is converted at runtime to 16000 Hz mono by the plugin before sending to the Audio2Face-3D service or local inference.
If you don’t already have Sound Wave assets in your project you can import the speech audio clips you want to animate:
Open the Content Drawer and select the folder where you want to import your clips.
Right click in the content pane and select Import to [path]….
Navigate to a supported file (.wav, .ogg, .flac, .aif) and open it.
Verify that a new Sound Wave asset appears in the Content Drawer.
See Unreal documentation for more details about import options.
If you don’t have any speech clips, you can use one of the examples at NVIDIA/Audio2Face-3D-Samples.
Note
Unreal Engine 5.5 has known issues when Loading Behavior Override is set to Force Inline in the Sound Wave asset’s properties. This can lead to crashes when loading a Sound Wave asset with Force Inline set. See UE-232114. Previous releases of the ACE Unreal plugins advised using Force Inline. We now recommend using any other loading behavior besides Force Inline.
In the current Unreal Engine releases, Opus compression is not compatible with Force Inline loading behavior. If Opus compression is desired for a Sound Wave asset, use any other loading behavior besides Force Inline. The ACE Unreal plugin will refuse to read from Opus-compressed Force Inline Sound Wave assets to avoid engine crashes and assertions.
Animating a Character from a Sound Wave Audio Clip#
Changed in version 2.3: Added async version of blueprint node.
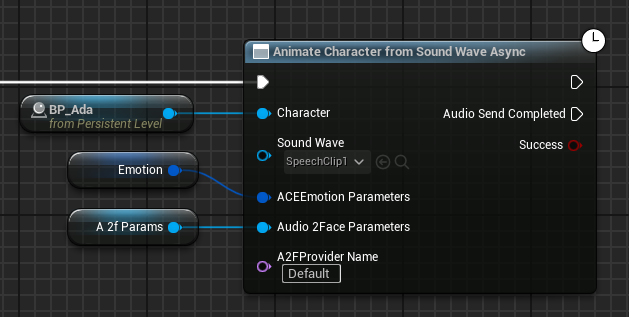
To animate a character from an audio clip stored in a Sound Wave asset,
use the latent blueprint node Animate Character from Sound Wave Async on
the character actor. These instructions describe the blueprint
interface, but you can also call
UACEBlueprintLibrary::AnimateCharacterFromSoundWave from C++.
Depending on your application, there are many ways to determine which character to animate. Some options are:
have a single default character that is animated
automatically animate the character that the player is looking at or the closest character
provide some UI for selecting a character
After you’ve chosen a character Actor, animate it from a Sound Wave asset:
Call the ACE > Audio2Face-3D > Animate Character From Sound Wave Async function.
Provide the actor corresponding to the character you want to animate. If the actor has an ACE Audio Curve Source component attached, this sends the speech clip to NVIDIA Audio2Face-3D.
Provide the speech clip asset as Sound Wave input.
Optionally, provide an Audio2Face-3D Emotion struct as ACEEmotionParameters input.
Optionally, provide an Audio2Face-3D Parameters input.
Optionally, provide an Audio2Face-3D provider name. If no provider name is specified, a default Audio2Face-3D provider will be chosen. See Changing Audio2Face-3D Providers (Optional) for details.
The node indicates whether the audio clip was successfully sent to Audio2Face-3D through the Success return value when the “Audio Send Completed” execution pin activates in a later frame.
Note
This blueprint node is designed to support Sound Wave assets imported into Unreal. Due to Unreal object type inheritance, nothing in Unreal Editor will prevent you from passing in something else that derives from USoundWave, such as a USoundWaveProcedural generated at runtime. This is not expected to work by default. If you have something that derives from USoundWave and holds raw PCM data, you can still pass it in with these limitations:
Raw PCM data will only be read if the
au.ace.rawpcmdata.enableconsole variable is set totrue.Reading from raw PCM data is provided as-is, unsupported.
Your application is responsible for guaranteeing that the raw PCM data held in the object you pass in remains unmodified while Animate Character From Sound Wave Async is running.
Note
There is also a deprecated non-async Animate Character from Sound Wave blueprint node, which is only present for compatibility with earlier plugin versions. It’s recommended that you use the async version to avoid blocking application logic while audio data is sent to Audio2Face-3D.
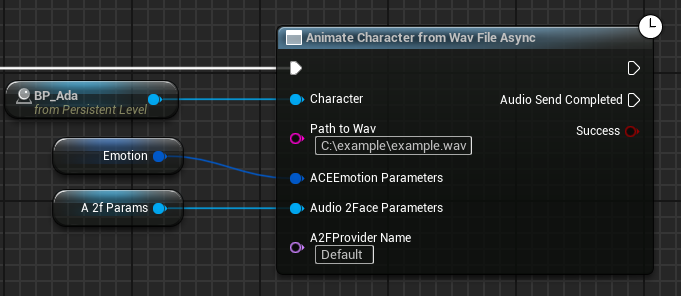
Animating a Character from a Local WAV File (Optional)#
Changed in version 2.3: Added async version of blueprint node.
The plugin supports animating a character from a local WAV file at runtime.
For example, this could be used in an application where you can supply your own audio files for character speech. It’s similar to animating from a Sound Wave asset, but in the case of a WAV file, the audio won’t be stored in an Unreal asset and isn’t baked into the application’s content.
Use the latent blueprint node
Animate Character from Wav File Async on the character actor. You
can also call UACEBlueprintLibrary::AnimateCharacterFromWavFile from
C++.
Note
There is also a deprecated non-async Animate Character from Wav File blueprint node, which is only present for compatibility with earlier plugin versions. It’s recommended that you use the async version to avoid blocking application logic while audio data is sent to Audio2Face-3D.
Animating a Character From Raw Audio Samples (Optional)#
Added in version 2.3.
Changed in version 2.4:
Calling
AnimateFromAudioSamples()multiple times for the same Audio2Face-3D inference session is now properly supported.Added
CancelAnimationGeneration().
If your application needs to feed audio generated at runtime into the ACE Unreal plugin, then providing a Sound Wave asset or WAV file as described above may not be an option. For these cases, the plugin exposes a C++ API. Any audio sample rate is supported and samples may be in PCM16 or float32 format.
Add
"ACERuntime"to thePrivateDependencyModuleNamesin your module’s.Build.csfile.#include "ACERuntimeModule.h"in your source file.Call
FACERuntimeModule::Get().AnimateFromAudioSamples()andFACERuntimeModule::Get().EndAudioSamples()from your code.
The signature of the C++ APIs is:
// Receive animations using audio from a float sample buffer.
// If bEndOfSamples = true, pending audio data will be flushed and any subsequent call to SendAudioSamples will start
// a new session.
// Will block until all samples have been sent into the Audio2Face-3D provider. Returns true if all samples sent
// successfully.
// Safe to call from any thread.
bool AnimateFromAudioSamples(IACEAnimDataConsumer* Consumer, TArrayView<const float> SamplesFloat, int32 NumChannels,
int32 SampleRate, bool bEndOfSamples, TOptional<FAudio2FaceEmotion> EmotionParameters,
UAudio2FaceParameters* Audio2FaceParameters, FName A2FProviderName = FName("Default"));
// Receive animations using audio from an int16 PCM sample buffer.
// If bEndOfSamples = true, pending audio data will be flushed and any subsequent call to SendAudioSamples will start
// a new session.
// Will block until all samples have been sent into the Audio2Face-3D provider. Returns true if all samples sent
// successfully.
// Safe to call from any thread.
bool AnimateFromAudioSamples(IACEAnimDataConsumer* Consumer, TArrayView<const int16> SamplesInt16, int32 NumChannels,
int32 SampleRate, bool bEndOfSamples, TOptional<FAudio2FaceEmotion> EmotionParameters,
UAudio2FaceParameters* Audio2FaceParameters, FName A2FProviderName = FName("Default"));
// Indicate no more samples for the current audio clip. Any subsequent call to AnimateFromAudioSamples will start a
// new session.
// Use this if your last call to SendAudioSamples had bEndOfSamples = false, and now the audio stream has ended.
// Safe to call from any thread.
bool EndAudioSamples(IACEAnimDataConsumer* Consumer);
// Cancel any in-progress animation generation for the given consumer.
// Note that any buffered animation data may continue to briefly play after calling this, but no new animation data will be generated.
// If you still had a session open, then any subsequent calls to AnimateFromAudioSamples() will have no effect until
// after the session is ended with bEndOfSamples=true or EndAudioSamples().
// Safe to call from any thread.
void CancelAnimationGeneration(IACEAnimDataConsumer* Consumer);
Parameter description:
Consumer: The component that will receive the animations. This will typically be a UACEAudioCurveSourceComponent attached to a character.SamplesFloatorSamplesInt16: The buffer containing the audio samples.NumChannels: 1 for mono, 2 for stereo.SampleRate: Samples per second of the source audio buffer.bEndOfSamples: If you have the entire audio clip at once, set this totrue. Otherwise set this tofalseand callAnimateFromAudioSamplesmultiple times as chunks of audio become available.EmotionParameters: Optional overrides from the default inferred emotion behavior.Audio2FaceParameters: Optional overrides for model-specific Audio2Face-3D facial animation behavior.A2FProviderName: The Audio2Face-3D provider to use. You can obtain a list of available providers at runtime withUACEBlueprintLibrary::GetAvailableA2FProviderNames(). See Changing Audio2Face-3D Providers (Optional) for details.
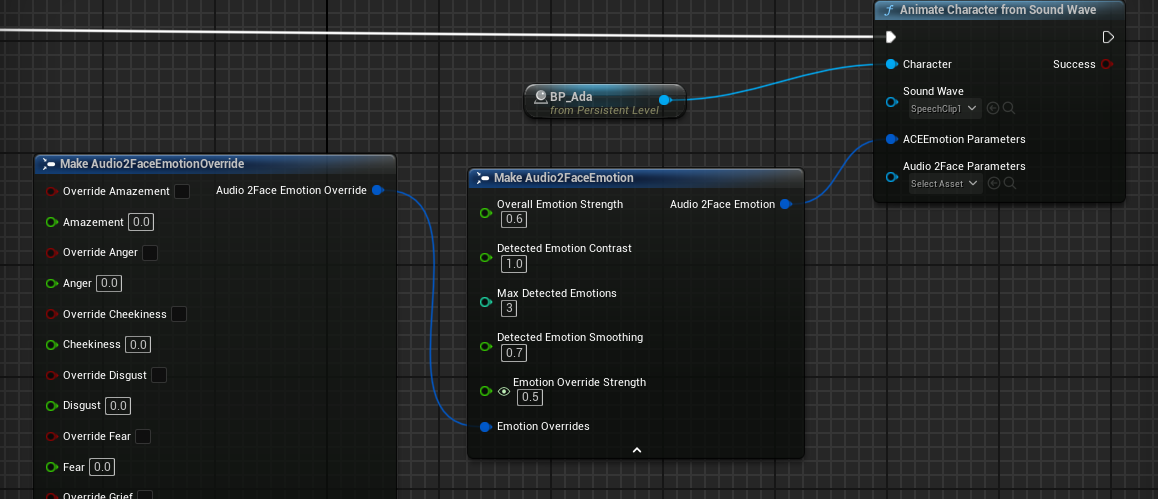
Adjusting Character Emotion (Optional)#
Audio2Face-3D detects emotions from the audio input that affect character animations appropriately. But if your application has information about character emotion, you can also provide this to Audio2Face-3D to blend application-provided emotion overrides with the detected emotion. Functions to animate a character accept an ACEEmotionParameters input of type Audio2FaceEmotion, where individual emotion values can be overridden. Each emotion override value must be between 0.0 and 1.0. Values outside that range are ignored. A value of 0.0 represents a neutral emotion.
The Audio2FaceEmotion struct can change how detected emotions are processed. The following table shows a summary of available options:
Parameter |
Description |
Valid Range |
Default |
|---|---|---|---|
Overall Emotion Strength |
Multiplier applied globally after the mix of emotions is done |
0.0 - 1.0 |
0.6 |
Detected Emotion Contrast |
Increase the spread of detected emotions values by pushing them higher or lower |
0.3 - 3.0 |
1.0 |
Max Detected Emotions |
Firm limit on the quantity of detected emotion values |
1 - 6 |
3 |
Detected Emotion Smoothing |
Coefficient for smoothing detected emotions over time |
0.0 - 1.0 |
0.7 |
Emotion Override Strength |
Blend between detected emotions (0.0) and override emotions (1.0) |
0.0 - 1.0 |
0.5 |
Emotion Overrides |
Individual emotion override values, each in the range 0.0 - 1.0 |
Disabled or 0.0 - 1.0 |
Disabled |
Note
Emotion and face parameter inputs may not have any effect for audio clips less than 0.5 seconds.
Changing Audio2Face-3D Providers (Optional)#
Added in version 2.2.
The base NVIDIA ACE plugin (NV_ACE_Reference.uplugin) supports selecting an Audio2Face-3D provider at runtime. Additional Audio2Face-3D providers may be implemented by other Unreal plugins.
Use the Get Available Audio2Face-3D Provider Names blueprint function to get a list of available providers at runtime. These provider names may be passed as a parameter to any of the Audio2Face-3D functions described in this documentation, to choose which provider you want to use.
The base NVIDIA ACE plugin includes these providers:
“RemoteA2F”: The default Audio2Face-3D provider, available on all supported platforms. Executes Audio2Face-3D remotely by connecting to an NVCF-hosted service or a separately deployed service. Currently incompatible with Animation Stream feature. The “RemoteA2F” provider can’t be used in the same application as Animation Stream.
“LegacyA2F”: An alternate remote Audio2Face-3D provider, available only on Windows. Provides the same functionality as “RemoteA2F” but using an implementation from earlier plugin releases. If you see new issues when upgrading to plugin version 2.3.0 or later, you can try “LegacyA2F” to see if it helps. Contact NVIDIA support to report any issues with “RemoteA2F” that would be fixed by using “LegacyA2F”. This provider is expected to be removed in a future plugin update.
Local Audio2Face-3D Providers (Optional)#
Added in version 2.4.
Optionally, you may install additional Unreal plugins to get access to more Audio2Face-3D providers that execute locally on a supported NVIDIA GPU. You may install additional Audio2Face-3D local execution Unreal plugins following the same instructions as the base NV_ACE_Reference plugin. See Unreal plugin installation instructions. The Audio2Face-3D connection settings will have no effect when using a local execution provider.
Each local execution provider is distributed as its own plugin. You can download multiple plugins and compare to see which gives the best results for your application. Then keep only one plugin for your shipping application.
There are multiple models offered. Each model can process any input language. Use the model which provides the best results for your chosen language. You may find each model has its own strengths in various languages or accents. Generally your shipping application should only need one model installed.
The following models are available, each has two variants: v3.0 diffusion and v2.3 regressive:
Mark — Expressive
Claire — Less expressive. Audio2Face-3D is sound-based, so all three models can speak any language, however Claire’s dataset includes Mandarin giving improved Mandarin performance.
James — Expressive with strong articulation
Diffusion variants offer:
60 FPS animations
Higher quality
Better emotion
Less averaging out of performance results
Better non-verbal performance
Regressive variants offer:
30 FPS animations
Better tested and better understood performance
Provider name |
Description |
Plugin name |
VRAM Usage (approximate) |
|---|---|---|---|
“LocalA2F-Claire” |
Claire v3.0 diffusion model |
NvAudio2FaceClaire |
4.4+ GiB |
“LocalA2F-James” |
James v3.0 diffusion model |
NvAudio2FaceJames |
4.4+ GiB |
“LocalA2F-Mark” |
Mark v3.0 diffusion model |
NvAudio2FaceMark |
4.4+ GiB |
“LocalA2F-Claire-AR” |
Claire v2.3 regressive model |
NvAudio2FaceClaireRegressive |
2.9+ GiB |
“LocalA2F-James-AR” |
James v2.3 regressive model |
NvAudio2FaceJamesRegressive |
2.9+ GiB |
“LocalA2F-Mark-AR” |
Mark v2.3 regressive model |
NvAudio2FaceMarkRegressive |
3.0+ GiB |
Note
The Audio2Face-3D local execution models can use more VRAM depending on the amount of VRAM the GPU provides.
Audio2Face-3D Burst Setting (Optional)#
Added in version 2.4.
We support two modes for sending audio into Audio2Face-3D inference:
Burst Mode: Send audio as quickly as it’s available from the application
Real-Time Mode: Limit how quickly audio is sent, so that inference doesn’t run any faster than it needs to for real-time animation
When Burst mode is on, using the “Animate Samples” Blueprint nodes will process the entire audio clip at once. Calling the AnimateFromAudioSamples C++ functions will process the entire chunk of audio at once. Burst mode is not recommended when Audio2Face-3D inference executes on the same system as rendering. See https://docs.nvidia.com/ace/latest/modules/a2f-docs/text/sharing_a2f_compute_resources.html for details. Burst mode is also not recommended for the RemoteA2F provider with audio clips of longer than 10 seconds due to known issues.
When Real-Time mode is on, the rate of Audio2Face-3D inference processing will be automatically limited. So the “Animate Samples” latent Blueprint nodes and AnimateFromAudioSamples C++ functions will take longer to complete. It is useful to limit resource contention when Audio2Face-3D inference executes on the same system as other work such as rendering.
The ACE Unreal plugin’s project settings have options for controlling Burst mode behavior. Find them under Edit > Project Settings… > Plugins > NVIDIA ACE > Audio2Face-3D:
Inference Burst Mode: Set according to desired behavior.
Default: Use the default recommended mode. In the current plugin release the recommended mode is Real-Time.
Force Burst Mode: Always enable Burst mode. Audio will be processed as quickly as possible.
Force Real-Time Mode: Always enable Real-Time mode. Audio will be processed only fast enough to keep up with real-time animation.
Max Initial Audio Chunk Size (Seconds): The initial amount of audio to process before limiting the rate of audio processing. Only has an effect in Real-Time mode. The default is 0.5 seconds.
There are also two blueprint nodes available if you need to override the project settings at runtime:
ACE > Audio2Face-3D > Override Audio2Face-3D Inference Burst Mode
ACE > Audio2Face-3D > Override Audio2Face-3D Inference Max Initial Chunk Size
Resource Optimization (Optional)#
Added in version 2.4.
You can usually let an Audio2Face-3D provider manage its own resources automatically. But for applications that want to ensure optimal use of resources, we allow the application to provide hints that can improve resource usage and performance.
Pre-allocate Resources#
Use the Allocate Audio2Face-3D Resources blueprint node before using an Audio2Face-3D provider for the first time, to
indicate that the application will soon be using this provider. This can reduce latency the first time the Audio2Face-3D
provider is used. The equivalent C++ function is available as FACERuntimeModule::Get().AllocateA2F3DResources().
It’s safe to call this function at any time. If the resources have already been allocated for the provider, it will have no effect. Typically this function would be used when loading an actor that will eventually be animated using Audio2Face-3D. If this function is not used, the resources will still be allocated as needed.
Examples of resources that may be affected include:
Allocating VRAM used for inference in the case of a local Audio2Face-3D provider
Establishing a network connection to a service in the case of a remote Audio2Face-3D provider
Free Resources Early#
Use the Free Audio2Face-3D Resources blueprint node to indicate that the application won’t be using a given Audio2Face-3D provider
in the near future. Some resources allocated by the provider will be freed as soon as it’s safe to do so. The
equivalent C++ function is available as FACERuntimeModule::Get().FreeA2F3DResources().
It’s safe to call this function at any time, even while the provider is still producing animation output. No resources will be freed until it is safe to do so, after any in-progress animations complete. If you use the same provider again after resources are freed, the resources will be automatically reallocated.
Examples of resources that may be freed include:
VRAM used for inference in the case of a local Audio2Face-3D provider
Open network connections to a service in the case of a remote Audio2Face-3D provider
Note
Freeing resources too often can add extra latency to the start of animations, because resources will need to be recreated the next time the Audio2Face-3D provider is used.
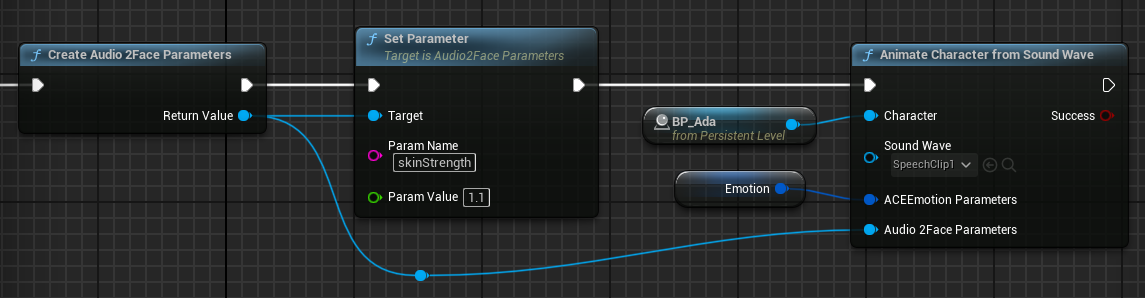
Adjusting Audio2Face-3D Parameters (Optional)#
Certain Audio2Face-3D runtime parameters can be overridden by the application. These parameters tend to be tightly coupled with the model deployed to the service or run through local inference. Typically, it’s not recommended to change these in the application. If you think you need to change any of these, refer to the Audio2Face-3D service documentation for details on what they do.
Set parameters by string name. The parameters available might change depending on the version of the service you have deployed. The set of available parameters for v1.0 Audio2Face-3D service are:
Parameter |
Description |
Valid Range |
Default |
|---|---|---|---|
skinStrength |
Controls the range of motion of the skin |
0.0 – 2.0 |
1.0 |
upperFaceStrength |
Controls the range of motion on the upper regions of the face |
0.0 – 2.0 |
1.0 |
lowerFaceStrength |
Controls the range of motion on the lower regions of the face |
0.0 – 2.0 |
1.0 |
eyelidOpenOffset |
Adjusts the default pose of eyelid open-close (-1.0 means fully closed. 1.0 means fully open) |
-1.0 – 1.0 |
depends on deployed model |
blinkStrength |
0.0 – 2.0 |
1.0 |
|
lipOpenOffset |
Adjusts the default pose of lip close-open (-1.0 means fully closed. 1.0 means fully open) |
-0.2 – 0.2 |
depends on deployed model |
upperFaceSmoothing |
Applies temporal smoothing to the upper face motion |
0.0 – 0.1 |
0.001 |
lowerFaceSmoothing |
Applies temporal smoothing to the lower face motion |
0.0 – 0.1 |
depends on deployed model |
faceMaskLevel |
Determines the boundary between the upper and lower regions of the face |
0.0 – 1.0 |
0.6 |
faceMaskSoftness |
Determines how smoothly the upper and lower face regions blend on the boundary |
0.001 – 0.5 |
0.0085 |
tongueStrength |
0.0 – 3.0 |
depends on deployed model |
|
tongueHeightOffset |
-3.0 – 3.0 |
depends on deployed model |
|
tongueDepthOffset |
-3.0 – 3.0 |
depends on deployed model |
Note
Emotion and face parameter inputs may not have any effect for audio clips less than 0.5 seconds.