Streaming in ACE Agent
Most bots built on ACE Agent use an LLM to generate the bot response. The LLM response may come from NVIDIA NeMo Guardrails (for example, Colang-based bots like the Stock bot) or from the Plugin server (for example, RAG or LangChain-based bots). In either of these cases, the perceived latency can be reduced by streaming the response from ACE Agent to the client as it is being generated. ACE Agent enables streaming for bots by default.
Streaming Overview
The ACE Agent Chat Engine uses a streaming handler as a common interface between NeMo Guardrails and the Plugin server. If streaming is enabled, the streaming handler is attached to the NeMo Guardrails context for each query. Any chunks pushed to the streaming handler are post-processed and converted to the response schema of the /chat or /event endpoint based on the request endpoint.
For cases in which the response is formed using NeMo Guardrails, the generate_bot_message action is called. If an LLM is used for bot response generation, the streaming endpoint of the LLM is called and the streamed chunks are added to the streaming handler.
To form a response from the Plugin server, the plugin endpoint should return a streaming response.
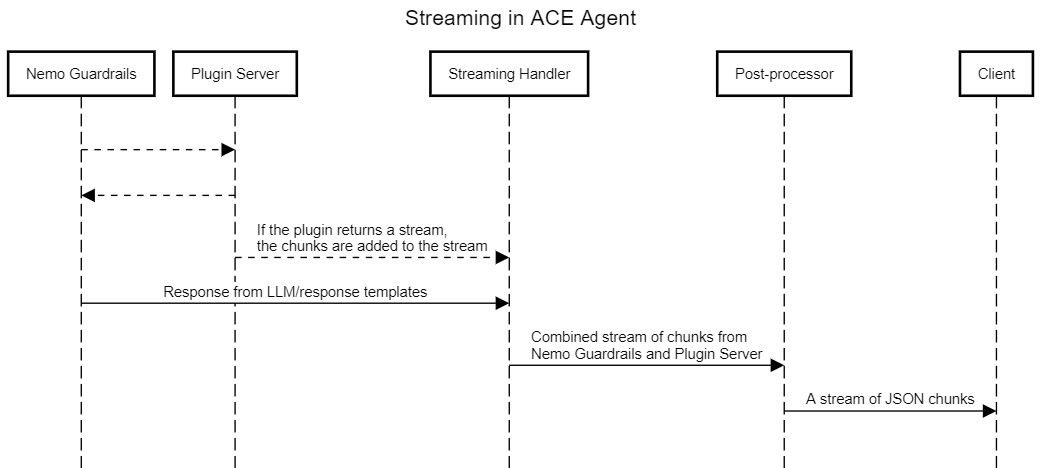
If the Plugin server is called by the bot and returns a non-streaming response, the response is not added to the stream.
If the response from the Plugin server is a text stream, the streamed chunks are added to the streaming handler by default.
If the response from the Plugin server is a stream of JSON responses in the Chat Engine response schema, the JSON chunks will be parsed and their Response. The text attribute will be added to the streaming handler by default.
The default behavior for streaming responses from the Plugin server is adding the chunks to the streaming handler. However, this can be disabled using the streaming argument of the plugin or chat_plugin action in your Colang files.
define flow user … $answer = execute plugin(endpoint="/your/endpoint", streaming=False) …
The ACE Agent Chat Engine has in-built protections to handle cases when the bot uses a static response template or does not create a text response at all. If your bot uses streaming responses in some cases and non-streaming responses in other cases, it is still beneficial to keep streaming enabled - Chat Engine will push the static response to the streaming handler as a single chunk.
Streaming Exceptions
There are certain cases in which streaming is disabled in ACE Agent.
If the LLM used by the bot does not support streaming.
If Output Rails are enabled in NeMo Guardrails.
In either of these cases, streaming will be disabled during bot initialization, even if streaming is enabled in the bot config file.
TTS Streaming
For bots that use speech or avatars, the ACE Agent Chat Controller is responsible for interacting with ACE Agent and processing the streaming response. The ACE Agent Chat Controller uses streaming by default, but this can be overridden in the speech_config.yaml file in the bot directory.
dialog_manager: DialogManager: server: "http://localhost:9000" use_streaming: false
If streaming is enabled in the bot and in the Chat Controller, then the Chat Controller reads the incoming stream and breaks the stream at every sentence boundary. Each sentence is then streamed to the client as text. If the query was a speech query, each sentence is passed to the TTS module and the TTS audio buffers are also streamed to the client. In practice, for long LLM responses, the first text and TTS chunks are received after the LLM generates the first sentence instead of after the full token generated by the LLM.