Tokkio LLM-RAG
Introduction
The Tokkio LLM-RAG sample application provides a reference for the users to showcase how an LLM or a RAG can be easily connected to the Tokkio pipeline. In this example, Tokkio and the RAG are deployed separately. The RAG is responsible for generating the text content of the interaction and Tokkio is providing a solution to enable avatar live interaction. Those two entities are separated and are communicating using the REST API. The users can develop their requirements and tune the app based on their needs. The Tokkio LLM-RAG app supports Nvidia enterprise RAG and Nvidia Generative AI examples out of the box. The process to deploy Tokkio with those RAGS will be presented here. Tokkio can also be connected to a 3rd party RAG. This will be presented in the section Customize the pipeline.
The LLM-RAG app aims to demonstrate the architectural and functional improvements in Tokkio: LLM features, easy switching between LLM models, adding any custom moderation policy to the bot, and ease of tuning the plugin server based on needs. Users can easily bring their own RAG with this Tokkio pipeline. The figure below shows tokkio end to end architecture for the reference LLM app:
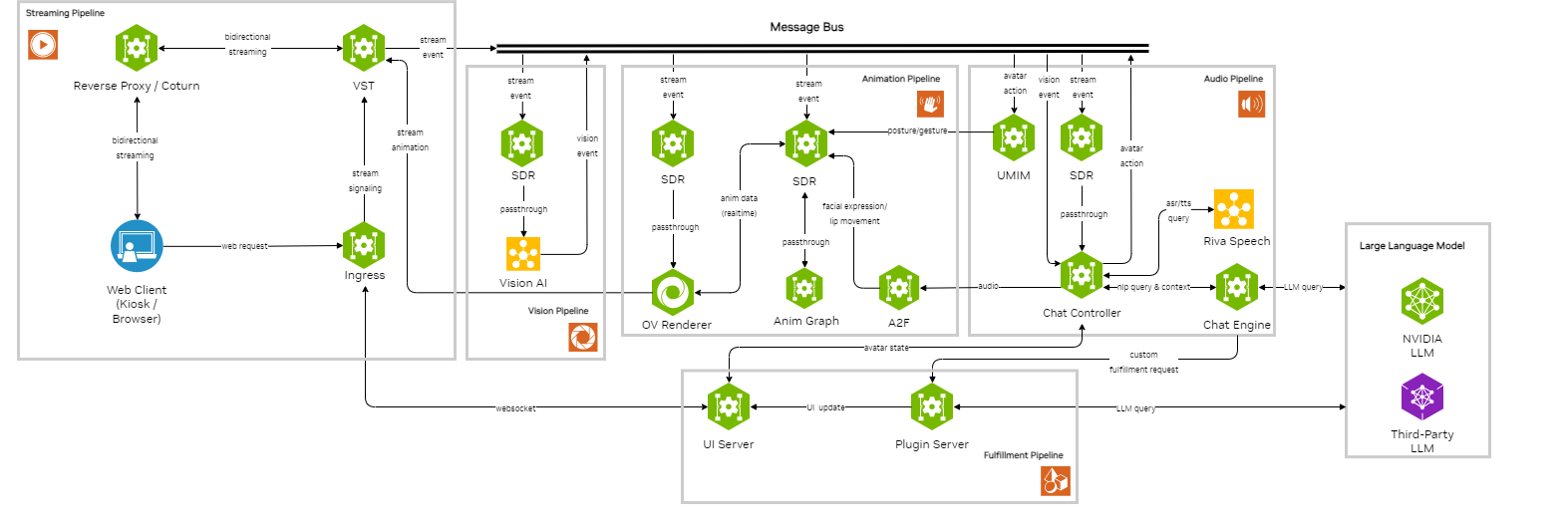
Quickstart
To deploy the Tokkio LLM-RAG reference app, the user needs to deploy a RAG server, ingest the desired documents in the RAG, configure Tokkio to use the RAG, and then deploy Tokkio. We recommend tuning the prompt of the LLM used in the RAG server to customize the behavior of the RAG to your needs.
Step 1. Deploy the RAG server
Tokkio LLM-RAG supports multiple RAG with multiple architectures:
For local LLM and vector databases with Kubernetes, refer to the Nvidia Enterprise RAG.
For local LLM and vector database with docker, refer to Nvidia Generative AI example repository and the Nvidia Generative AI example documentation
For cloud-based LLM and local vector database with docker, refer to Nvidia Generative AI example repository and the Nvidia Generative AI API catalog documentation
Note
Note that the RAG or LLM pipeline needs to be deployed on the same network as Tokkio.
Note
By default, the RAG pipeline is designed to answer questions specifically about the uploaded documents. This ensures that the avatar remains focused on the intended topic of discussion. While this behavior can be beneficial in maintaining relevance, it also means that the avatar will not engage in small talk or general discussions. However, this behavior can be customized to suit different use cases. You can update the prompt of the LLM used in the RAG by modifying the environment variable APP_PROMPTS_RAGTEMPLATE.
About the Nvidia Enterprise RAG
To use the Nvidia Enterprise RAG with Tokkio, you’ll need to manually open the chain-server port to enable communication between the 2 entities. This can done as follows:
In the downloaded helm manifest file “helmpipeline_app_trtllm.yaml”, find the repo entry “rag-llm-app” and change the service type from “ClusterIP” to “NodePort”.
Execute this command after the pods are deployed:
$ kubectl port-forward service/chain-server -n rag-sample 32090:8081
Once the port is forwarded, the chain server application can be found at http://localhost:32090.
About the Nvidia Generative AI API catalog RAG
By default, the Nvidia Generative AI API uses Mixtral 7b. While this will work out of the box, we recommend Llama 3 70b for better results.
The RAG can be configured to use this LLM like this:
++ b/deploy/compose/rag-app-api-catalog-text-chatbot.yaml @@ -11,7 +11,7 @@ services: environment: APP_VECTORSTORE_URL: "http://milvus:19530" APP_VECTORSTORE_NAME: "milvus" - APP_LLM_MODELNAME: ${APP_LLM_MODELNAME:-ai-mixtral-8x7b-instruct} + APP_LLM_MODELNAME: ${APP_LLM_MODELNAME:-ai-llama3-70b}
The NVIDIA Generative AI API catalog supports a large set of LLM. The list of the LLM available can be found using:
from langchain_nvidia_ai_endpoints import ChatNVIDIA NVIDIA_API_KEY="<add your api key>" ChatNVIDIA().get_available_models()
To configure the RAG to use a specific LLM set the model id in the APP_LLM_MODELNAME in the /deploy/compose/rag-app-api-catalog-text-chatbot.yaml Please note that the API key will need to be generated on a model basis
Once the RAG is deployed, follow the RAG documentation to ingest documents in the RAG
Step 2. Connect the RAG and deploy Tokkio
Refer to the Quickstart Guide to get the Tokkio LLM UCS app source code. Then open the tokkio-llm-app-params.yaml and update the rag-server service and port with the IP and port of the chain-server component of the RAG.
rag-server: service: "00.000.00.000" port: 0000
Then the helm chart can be built and deployed using the Quickstart Guide
Customizing the Pipeline
The Tokkio-LLM-RAG app can be customized to connect to your desired LLM or RAG. This section assumes that the LLM or RAG you want to connect to Tokkio is deployed behind a REST API server. This server can be connected to Tokkio, by customizing the LLM client plugin in the Tokkio-LLM-RAG ACE agent bot. For a complete description of an ACE agent bot, we invite the reader to visit the Nvidia Ace agent section.
Step 1. Get the Tokkio-LLM-RAG ACE bot
The path of the Tokkio-LLM-RAG bot can be found in the tokkio-llm-app-params.yaml at this NGC path:
chat-controller: pipeline: avatar_umim configNgcPath: "NGC_PATH"
Then, it can downloaded from NGC using:
$ ngc registry resource download-version "NGC_PATH"
Step 2. Customize the Tokkio-LLM-RAG ACE bot
Introduction to the Tokkio LLM-RAG ACE bot
The Tokkio LLM-RAG ace bot contains the following files:
tokkio_rag_bot_config- this file contains the ACE bot definitionspeech_config.yaml- this file contains the speech configuration parameters for the applicationplugin_config.yaml- this file contains the definition of the ACE plugin server configurationaction.py- this contains custom actions that the Colang code can call like the plugin-serverplugin/rag.py- this file contains the definition of the Python client of the external RAG or LLMmodel_config.yaml- The definition of the model to use. This can be overwritten in the UCS appcmudict_ipa.txt- It allows to customize the pronunciation of some specific wordsasr_words_to_boost_conformer.txt- a default list of words for asr word boosting.
All the files in the colang folder define the flow for handling various queries in the LLM bot with multimodality.
Connect to an LLM or RAG
Once the ACE bot is obtained, it can be customized to connect to a 3rd party LLM. The LLM client can be found in the bot under plugin/rag.py. By default, it contains the Python client for the Nvidia Enterprise RAG and the Nvidia Generative AI example This file can be customized to add the Python client of the LLM or RAG of your choice with or without streaming. This client is called every time a request is sent to the ACE bot, it runs inside the ace-agent-plugin-server and is being called by the action.py from the ace-agent-chat-engine pod.
Gesture generation
By default, the bot prompts the RAG in a parallel Colang flow to annotate the response with a gesture. This enables the pipeline to render the avatar with situational gestures aligned with the meaning of the response. However, the quality of the gesture generation depends on the capabilities of the RAG you set up. In case of low-quality gesture response, you might see the avatar performing gestures that don’t match the content of the response.
Gesture generation can be disabled by removing the following lines in the colang/main.co
else start attempt to infer gesture $question $response
Interruptions
The bot supports being interrupted by the user. This is especially useful in a RAG context where the response is long responses for certain queries. The bot supports two types of interruptions
The user can interrupt the response of the avatar by saying “stop”, “stop talking” or “cancel”. This will stop the RAG response and acknowledge the user’s request. Please note that the identification of these short requests is handled based on a regular expression that you can update in the colang/main.co file.
The avatar can also be stopped by asking a new question. In that case, the current RAG response will be stopped and the RAG will be queried with the new user request.
Small Talk
Some small talk question-answer pairs can be added to the Colang script. The users can add their examples for small talk in a dedicated Colang file. You can find more details in the Colang Language Reference on how to handle user intents.
Proactive bot
By default, the bot is configured to be proactive if the user does not respond within a certain time. In that case, the RAG is queried to provide an encouraging response to the user to re-engage the user with the interaction. This behavior can be customized in the colang/main.co file
orwhen user didnt respond 20.0 #Change what happens if the user does not respond
Publish the bot
Once the ACE bot is customized it can be pushed to NGC using:
$ ngc registry resource upload-version --source BOT_FOLDER_NAME targeted_ngc_path:version
Step 3. Connect a custom ACE bot to Tokkio-LLM-RAG
Once the customized bot is available on NGC, it can connected to Tokkio by adding the path of the custom ACE bot in the tokkio-llm-app-params.yaml. Note that it appears 3 times
chat-controller:
pipeline: avatar_umim
configNgcPath: "<path to the custom ACE bot resource on ngc>"
speechConfigPath: "speech_config.yaml" # resource containing the model configuration for the riva speech models
wordBoostFilePath: "asr_words_to_boost_conformer.txt" # resource containing the words to boost
ipaDictPath: "cmudict_ipa.txt" # resource to customize the prononciation of certain words
pipelineParams: # can be extended for all pipeline params in parameters.yaml
grpc_server:
nvidia::rrt::BotRuntimeGrpc:
virtual_assistant_num_instances: 10
speech_pipeline_manager: # config name
SpeechPipelineManager: # component name
tts_eos_delay_ms: 0 # parameters (0 in tbyb)
initial_state: "INIT"
always_on: true
#asr_idle_timeout_ms: -1 ()
riva_asr:
RivaASR:
enable_profanity_filter: false
riva_tts:
RivaTTS:
voice_name: "English-US-RadTTS.Male-1" # Change to English-US.Female-1 for Female voice
sample_rate: 16000
chunk_duration_ms: 600 #amount of data to be sent to downstream in real time
audio_start_threshold_ms: 2000 #duration for which audio data will be sent in burst and rest of the data will be sent in realtime
send_audio_in_realtime: true #this will send synthesized audio data in realtime to downstream
chat-engine:
configNgcPath: <path to the custom ACE bot resource on ngc>
botConfigName: tokkio_rag_bot_config.yml # file in the above mentioned resource containing the ACE engine bot definition
interface: "event"
logLevel: "INFO"
plugin-server:
configNgcPath: ""<path to the custom ACE bot resource on ngc>""
pluginConfigPath: "plugin_config.yaml" # Definition of the plugin server to use
The build and deploy the helm chart using the Quickstart Guide.