Best Performance Cluster Configuration#
The Best Performance configuration is designed to provide maximum performance per node, maximizing the number of nodes for scale-up and scale-out. By providing the maximum number of GPUs per rack, 22 GPUs compared with 15 GPUs, maximum throughput is best achieved.
It is important to note that sizing calculations are based on a 14kW redundant PDU per rack and a dual 1600W PSU per server since most enterprise data centers have these requirements. Due to these power requirements, rack density calculation resulted in fewer GPU nodes per rack than CPU-only nodes per rack for the Best Performance configuration.
Server and Rack Configuration#
The Best Performance configuration maximizes the number of GPUs within a 2U system. Keeping with the same Server hardware configuration and the same CPU used in the Mainstream configuration, the Best Performance configuration further increases the RAM, storage, power supply sizes, and network cards and doubles the number of GPUs. Since the number of GPUs double per server, VMs servicing as four-node clusters totals 21 with 2 VMs per server.
Enterprise AI / Edge AI / Data Analytics |
|---|
2U NVIDIA-Certified System |
Dual Intel® Xeon® Gold 6248R 3.0G, 24C/48T, 10.4GT/s, 35.75 M Cache, Turbo, HT (205W) DDR4-2933 |
24x 32GB RDIMM, 3200MT/s, Dual Rank |
2x 1.92TB SSD SATA Mix Use 6Gbps 512, 2.5in Hot-plug AG Drive, 3 DWPD, 10512 TBW |
1x 3.84TB Enterprise NVMe Read Intensive AG Drive U.2 Gen4 with carrier |
1x 16GB microSDHC/SDXC Card |
Dual, Hot-plug, Redundant Power Supply (1+1), 2000W |
2x NVIDIA® BlueField-2® 100G or NVIDIA ConnectX-6 DX 100G / 200G |
NVIDIA® SN3420/SN3700 Top of Rack |
2x NVIDIA A100 for PCIe |
Important
NVIDIA A30 and A100 GPUs are compute-only GPUs and are not suitable for Remote Collaboration/ProViz workloads.
The following table illustrates the rack density for the Best Performance configuration. The rack configuration would consist of 11 nodes requiring ~13.7 kW of power. Please refer to the Sizing Guide Appendix for additional clarification regarding Best Performance sizing calculations.
Enterprise AI / Edge AI / Data Analytics |
|---|

|
Rack Density 11 nodes requiring ~13.7 kW of power. |
It is important to note: the Best Performance configuration increases the amount of GPU resources, and thereby provides increased performance throughput. The number of nodes in the rack has decreased (Best – 15, Mainstream – 11) with relatively the same amount of kW of power draw. However, since the number of GPUs double per server, the number of VMs servicing as 4-node clusters totals 21 – 2 VMs per server.
Networking#
The Best Performance configuration provides the highest-performance networking since it is critical as AI Enterprise workloads scale-out and scale-up. With up to 11 nodes per rack and 22 GPUs per rack, upgrading NVIDIA Mellanox ConnectX-6 DX PCIe to 100 or 200GB and NVIDIA SN37000 switch will even further maximize throughput between compute nodes.
The following diagram describes the networking topology. This network topology uses the same topology as the Mainstream configuration but introduces a dual non-blocking GPU Leaf switch design for maximum throughput across the compute nodes.
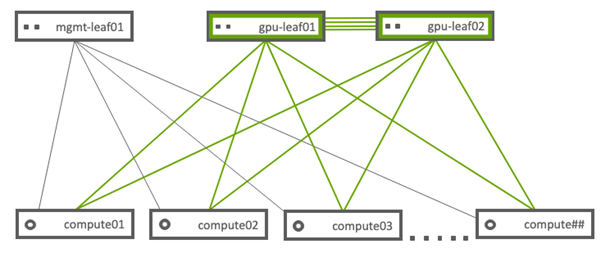
Note
mgmt-leaf01 is the Infrastructure Top of Rack switch.
gpu-leaf01 and gpu-leaf02 are the compute Top of Rack NVIDIA Mellanox SN3700 switch.
Storage#
The Best Performance cluster configuration increases the NVMe and NFS cache drives over the Mainstream configuration for maximum throughput and increased model sizes. This configuration contains more GPU resources, allowing for more extensive data for AI Enterprise workloads. Adding additional NVMe drives can further improve performance and throughput.
The Best Performance configuration is also positioned to prepare future storage technologies like NVMe over Fabric (NVMeoF) and GPU Direct Storage (GDS).
Performance#
This configuration can improve performance up to 44x when compared to a CPU-only rack. By maximizing A100 GPUs and NVIDIA NICs in the NVIDIA-Certified Systems using the Best Performance configuration, organizations can dramatically increase performance throughput for AI Enterprise workloads. However, because this configuration requires more power than the CPU-only configuration, at the rack level, it can only accommodate 11 GPU nodes compared to 20 CPU-only nodes.
For more information regarding performance test results, see the Sizing Guide Appendix.