For clean Markdown of any page, append .md to the page URL. For a complete documentation index, see https://docs.nvidia.com/aistore/llms.txt. For full documentation content, see https://docs.nvidia.com/aistore/llms-full.txt.
The AIStore PyTorch integration is a growing set of datasets, samplers, and more that allow you to use easily add AIStore support
to a codebase using PyTorch. This document contains API documentation for the AIStore PyTorch integration.
For usage examples, please see:
* [AIS Plugin for PyTorch](https://github.com/NVIDIA/aistore/tree/main/python/aistore/pytorch/README.md)
* [Jupyter Notebook Examples](https://github.com/NVIDIA/aistore/tree/main/python/examples/pytorch/)
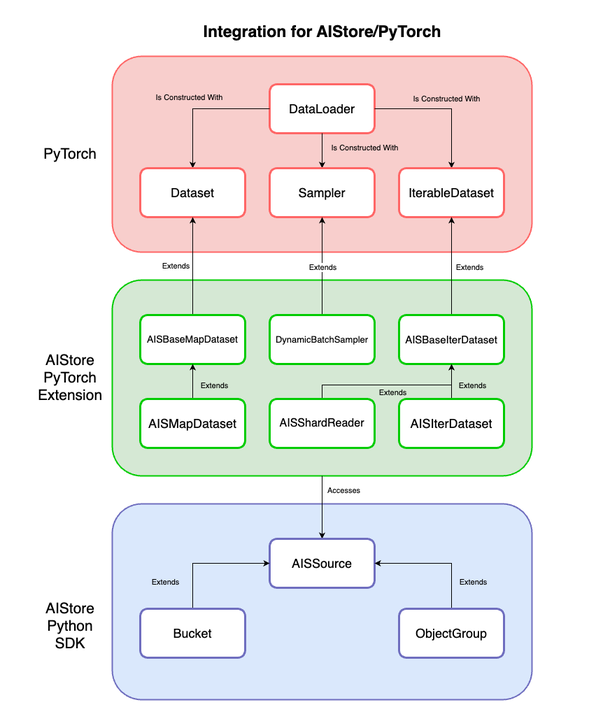
* [base\_map\_dataset](#base_map_dataset)
* [AISBaseMapDataset](#base_map_dataset.AISBaseMapDataset)
* [get\_obj\_list](#base_map_dataset.AISBaseMapDataset.get_obj_list)
* [base\_iter\_dataset](#base_iter_dataset)
* [AISBaseIterDataset](#base_iter_dataset.AISBaseIterDataset)
* [\_\_iter\_\_](#base_iter_dataset.AISBaseIterDataset.__iter__)
* [\_\_len\_\_](#base_iter_dataset.AISBaseIterDataset.__len__)
* [map\_dataset](#map_dataset)
* [AISMapDataset](#map_dataset.AISMapDataset)
* [iter\_dataset](#iter_dataset)
* [AISIterDataset](#iter_dataset.AISIterDataset)
* [shard\_reader](#shard_reader)
* [AISShardReader](#shard_reader.AISShardReader)
* [\_\_len\_\_](#shard_reader.AISShardReader.__len__)
* [ZeroDict](#shard_reader.AISShardReader.ZeroDict)
* [multishard\_dataset](#multishard_dataset)
* [AISMultiShardStream](#multishard_dataset.AISMultiShardStream)
* [parallel\_map\_dataset](#parallel_map_dataset)
* [AISParallelMapDataset](#parallel_map_dataset.AISParallelMapDataset)
* [num\_workers](#parallel_map_dataset.AISParallelMapDataset.num_workers)
Base class for AIS Map Style Datasets
Copyright (c) 2024-2025, NVIDIA CORPORATION. All rights reserved.
## Class: AISBaseMapDataset
```python
class AISBaseMapDataset(ABC, Dataset)
```
A base class for creating map-style AIS Datasets. Should not be instantiated directly. Subclasses
should implement :meth:`__getitem__` which fetches a samples given a key from the dataset and can optionally
override other methods from torch Dataset such as :meth:`__len__` and :meth:`__getitems__`.
**Arguments**:
- `ais_source_list` _Union[AISSource, List[AISSource]]_ - Single or list of AISSource objects to load data
prefix_map (Dict(AISSource, List[str]), optional): Map of AISSource objects to list of prefixes that only allows
objects with the specified prefixes to be used from each source
### get\_obj\_list
```python
def get_obj_list() -> List[Object]
```
Getter for internal object data list.
**Returns**:
- `List[Object]` - Object data of the dataset
Base class for AIS Iterable Style Datasets
Copyright (c) 2024-2025, NVIDIA CORPORATION. All rights reserved.
## Class: AISBaseIterDataset
```python
class AISBaseIterDataset(ABC, torch_utils.IterableDataset)
```
A base class for creating AIS Iterable Datasets. Should not be instantiated directly. Subclasses
should implement :meth:`__iter__` which returns the samples from the dataset and can optionally
override other methods from torch IterableDataset such as :meth:`__len__`.
**Arguments**:
- `ais_source_list` _Union[AISSource, List[AISSource]]_ - Single or list of AISSource objects to load data
prefix_map (Dict(AISSource, List[str]), optional): Map of AISSource objects to list of prefixes that only allows
objects with the specified prefixes to be used from each source
### \_\_iter\_\_
```python
@abstractmethod
def __iter__() -> Iterator
```
Return iterator with samples in this dataset.
**Returns**:
- `Iterator` - Iterator of samples
### \_\_len\_\_
```python
def __len__()
```
Returns the length of the dataset. Note that calling this
will iterate through the dataset, taking O(N) time.
NOTE: If you want the length of the dataset after iterating through
it, use `for i, data in enumerate(dataset)` instead.
PyTorch Dataset for AIS.
Copyright (c) 2022-2026, NVIDIA CORPORATION. All rights reserved.
## Class: AISMapDataset
```python
class AISMapDataset(AISBaseMapDataset)
```
A map-style dataset for objects in AIS.
If `etl_name` is provided, that ETL must already exist on the AIStore cluster.
**Arguments**:
- `ais_source_list` _Union[AISSource, List[AISSource]]_ - Single or list of AISSource objects to load data
prefix_map (Dict(AISSource, List[str]), optional): Map of AISSource objects to list of prefixes that only allows
objects with the specified prefixes to be used from each source
- `etl_name` _str, optional_ - Optional ETL on the AIS cluster to apply to each object
NOTE:
Each object is represented as a tuple of object_name (str) and object_content (bytes)
Iterable Dataset for AIS
Copyright (c) 2024-2025, NVIDIA CORPORATION. All rights reserved.
## Class: AISIterDataset
```python
class AISIterDataset(AISBaseIterDataset)
```
An iterable-style dataset that iterates over objects in AIS and yields
samples represented as a tuple of object_name (str) and object_content (bytes).
If `etl_name` is provided, that ETL must already exist on the AIStore cluster.
**Arguments**:
- `ais_source_list` _Union[AISSource, List[AISSource]]_ - Single or list of AISSource objects to load data
prefix_map (Dict(AISSource, Union[str, List[str]]), optional): Map of AISSource objects to list of prefixes that only allows
objects with the specified prefixes to be used from each source
- `etl_name` _str, optional_ - Optional ETL on the AIS cluster to apply to each object
- `show_progress` _bool, optional_ - Enables console dataset reading progress indicator
**Yields**:
Tuple[str, bytes]: Each item is a tuple where the first element is the name of the object and the
second element is the byte representation of the object data.
AIS Shard Reader for PyTorch
PyTorch Dataset and DataLoader for AIS.
Copyright (c) 2024-2025, NVIDIA CORPORATION. All rights reserved.
## Class: AISShardReader
```python
class AISShardReader(AISBaseIterDataset)
```
An iterable-style dataset that iterates over objects stored as Webdataset shards
and yields samples represented as a tuple of basename (str) and contents (dictionary).
**Arguments**:
- `bucket_list` _Union[Bucket, List[Bucket]]_ - Single or list of Bucket objects to load data
prefix_map (Dict(AISSource, Union[str, List[str]]), optional): Map of Bucket objects to list of prefixes that only allows
objects with the specified prefixes to be used from each source
- `etl_name` _str, optional_ - Optional ETL on the AIS cluster to apply to each object
- `show_progress` _bool, optional_ - Enables console shard reading progress indicator
**Yields**:
Tuple[str, Dict(str, bytes)]: Each item is a tuple where the first element is the basename of the shard
and the second element is a dictionary mapping strings of file extensions to bytes.
### \_\_len\_\_
```python
def __len__()
```
Returns the length of the dataset. Note that calling this
will iterate through the dataset, taking O(N) time.
NOTE: If you want the length of the dataset after iterating through
it, use `for i, data in enumerate(dataset)` instead.
## Class: ZeroDict
```python
class ZeroDict(dict)
```
When `collate_fn` is called while using ShardReader with a dataloader,
the content dictionaries for each sample are merged into a single dictionary
with file extensions as keys and lists of contents as values. This means,
however, that each sample must have a value for that file extension in the batch
at iteration time or else collation will fail. To avoid forcing the user to
pass in a custom collation function, we workaround the default implementation
of collation.
As such, we define a dictionary that has a default value of `b""` (zero bytes)
for every key that we have seen so far. We cannot use None as collation
does not accept None. Initially, when we open a shard tar, we collect every file type
(pre-processing pass) from its members and cache those. Then, we read the shard files.
Lastly, before yielding the sample, we wrap its content dictionary with this custom dictionary
to insert any keys that it does not contain, hence ensuring consistent keys across
samples.
NOTE: For our use case, `defaultdict` does not work due to needing
a `lambda` which cannot be pickled in multithreaded contexts.
Multishard Stream Dataset for AIS.
Copyright (c) 2024-2025, NVIDIA CORPORATION. All rights reserved.
## Class: AISMultiShardStream
```python
class AISMultiShardStream(IterableDataset)
```
An iterable-style dataset that iterates over multiple shard streams and yields combined samples.
**Arguments**:
- `data_sources` _List[DataShard]_ - List of DataShard objects
**Returns**:
- `Iterable` - Iterable over the combined samples, where each sample is a tuple of
one object bytes from each shard stream
PyTorch Map-style Dataset with parallel download acceleration.
Copyright (c) 2026, NVIDIA CORPORATION. All rights reserved.
## Class: AISParallelMapDataset
```python
class AISParallelMapDataset(AISBaseMapDataset)
```
Map-style dataset that uses parallel download to fetch objects.
Parallel download splits each object into byte ranges and fetches them
concurrently using `num_workers` workers.
`__getitem__` returns `(object_name, ParallelBuffer)`. The caller (or
PyTorch DataLoader collate function) is responsible for consuming and
closing the `ParallelBuffer`.
**Arguments**:
- `ais_source_list` - Single or list of AISSource objects to load data.
- `prefix_map` - Map of AISSource to prefix(es) for filtering objects.
- `num_workers` - Number of concurrent range-read workers per object.
### num\_workers
```python
@property
def num_workers() -> int
```
Number of concurrent range-read workers per object.