Introduction#
NVIDIA Cosmos is a developer-first platform for designing Physical AI systems. Cosmos is divided into three components, each with its own GitHub repository:
Cosmos-Predict1: A collection of general-purpose world foundation models (WFMs) for inference, along with scripts for post-training these models for specific Physical AI use cases.
Cosmos-Transfer1: A set of pre-trained, diffusion-based conditional world models designed for multimodal, controllable world generation. These models can create world simulations based on multiple spatial control inputs across various modalities such as segmentation, depth, and edge maps. Cosmos-Transfer1 offers the flexibility to weight different conditional inputs differently at varying spatial locations and temporal instances, enabling highly customizable world generation. This capability is particularly useful for various world-to-world transfer applications, including Sim2Real.
Cosmos-Reason1: A suite of models, ontologies, and benchmarks that enable multimodal LLMs to generate physically grounded responses. This release includes two multimodal LLMs: Cosmos-Reason1-8B and Cosmos-Reason1-56B, which are trained in four stages: vision pre-training, general SFT, Physical AI SFT, and Physical AI reinforcement learning. Cosmos-Reason1 also defines ontologies for physical common sense and embodied reasoning, including benchmarks to evaluate Physical AI reasoning capabilities of multimodal LLMs.
Cosmos-Predict1#
The architecture of Cosmos-Predict1 is shown in the following figure:

Cosmos-Predict1 includes the following components:
Diffusion Models: Generate visual simulations using text or video prompts.
Autoregressive Models: Generate visual simulations using video prompts along with optional text prompts.
Tokenizers: Split images or videos into continuous tokens (latent vectors) and discrete tokens (integers) efficiently and effectively.
Post-training Scripts: Help developers post-train the diffusion and autoregressive models for their particular Physical AI use cases.
Pre-training Scripts: Help developers train their WFMs from scratch.
Examples#
Cosmos-Predict1-7B-Text2World-Multiview#
This video shows the text input and corresponding multiview output generated using inference with the Cosmos-Predict1-7B-Text2World-Multiview diffusion model.
Cosmos-Predict1-5B-Video2World#
This video shows the text and image input and the corresponding video output generated using inference with the Cosmos-Predict1-5B-Video2World autoregressive model.
Getting Started Workflow#
Follow these steps to explore the capabilities of Cosmos-Predict1:
Use the Model Matrix page to determine the best model for your use case. Note that only a subset of models currently support post-training.
Review the Prerequisites page and follow the Installation guide.
Follow the steps in the Diffusion Quickstart Guide or Autoregressive Quickstart Guide to get familiar with the inference process.
If you want to post-train a model for a particular Physical AI use case, follow the steps in the Diffusion Post-Training Guide or Autoregressive Post-Training Guide.
To learn more about the inference options available for each model, refer to the Diffusion Model Reference or Autoregressive Model Reference.
Cosmos-Transfer1#
The architecture of Cosmos-Transfer1 is shown in the following figure:
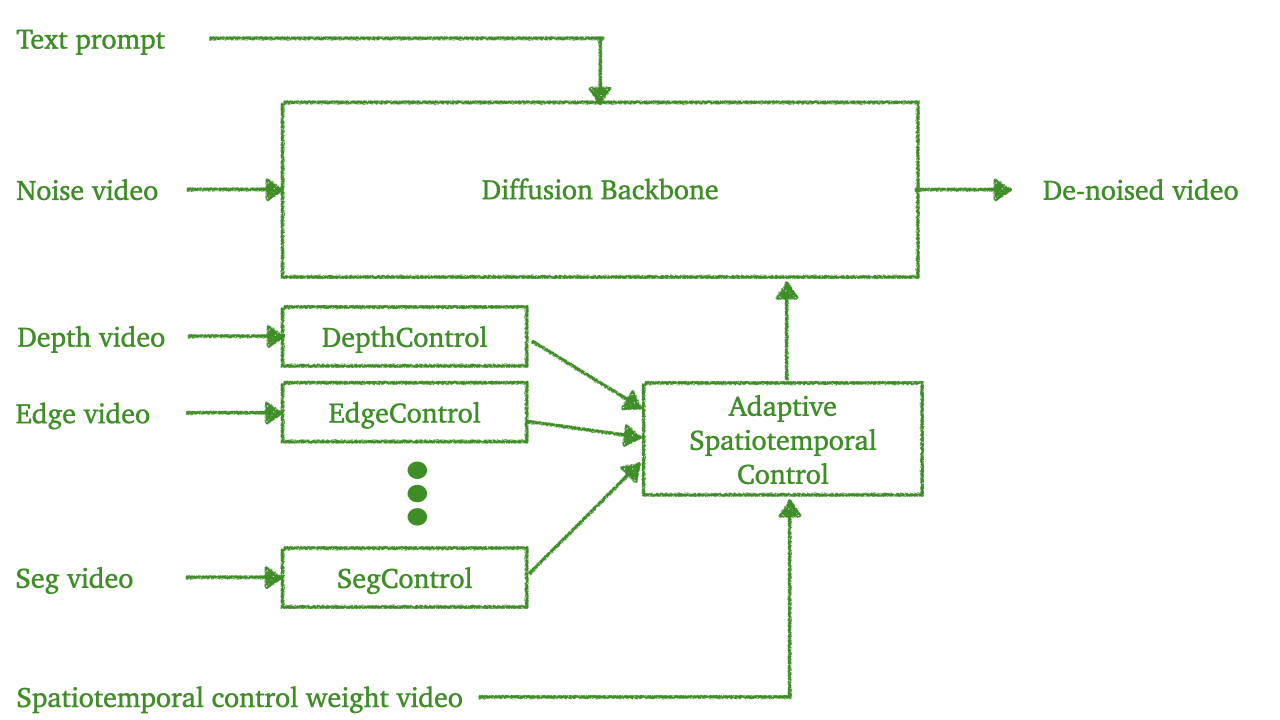
Cosmos-Transfer1 includes the following components:
ControlNet-based single modality conditional world generation: Generate visual simulation based on one of the following modalities: segmentation video, depth video, edge video, blur video, LiDAR video, or HDMap video. Cosmos-Transfer1 generates a video based on the signal modality, conditional input, user text prompt, and, optionally, an input RGB video frame prompt (which could be from the last video generation result when operating in the autoregressive setting). We will use Cosmos-Transfer1-7B [Modality] to refer to the model operating in this setting. For example, Cosmos-Transfer1-7B [Depth] refers to a depth ControlNet model.
MultiControlNet-based multimodal conditional world generation: Generate visual simulation based on any combination of segmentation video, depth video, edge video, and blur video (LiDAR video and HDMap in the AV sample) with a spatiotemporal control map to control the strength of each modality across space and time. Cosmos-Transfer1 generates a video based on the multimodal conditional inputs, a user text prompt, and, optionally, an input RGB video frame prompt (This could be from the last video generation result when operating in the autoregressive setting). This is the preferred mode of Cosmos-Transfer. We will refer it as Cosmos-Transfer1-7B.
4KUpscaler: Allows for upscaling 720p-resolution video to 4K-resolution.