Overview¶
This section describes the basic working principle of the cuStateVec library. For a general introduction to quantum circuits, please refer to Introduction to quantum computing.
Description of state vectors¶
In the cuStateVec library, the state vector is always given as a device array and its data type is specified by a cudaDataType_t constant. It’s users’ responsibility to manage memory for the state vector.
This version of cuStateVec library supports 128-bit complex (complex128) and 64-bit complex (complex64) as datatypes of the state vector. The size of a state vector is represented by the nIndexBits argument which corresponds to the number of qubits in a circuit. Therefore, the state vector size is expressed as \(2^{\text{nIndexBits}}\).
The type custatevecIndex_t is provided to express the state vector index, which is a typedef of the 64-bit signed integer.
Bit ordering¶
In the cuStateVec library, the bit ordering of the state vector index is defined in the little endian order. The 0-th index bit is the least significant bit (LSB). Most functions accept arguments to specify bit positions as integer arrays. Those bit positions are specified in the little endian order. Values in bit positions are in the range \([0, \text{nIndexBits})\).
In order to represent bit strings, a pair of bitString and bitOrdering arguments are used. The bitString argument specifies bit string values as an array of 0 and 1. The bitOrdering argument specifies the bit positions of the bitString array elements in the little endian order.
In the following example, “10” is specified as a bit string. Bit string values are mapped to the 2nd and 3rd index bits and can be used to specify a bit mask, \(*\cdots *10*\).
int32_t bitString[] = {0, 1}
int32_t bitOrdering[] = {1, 2}
Supported data types¶
By default, computation is executed by the corresponding precision of the state vector, double float (FP64) for complex128 and single float (FP32) for complex64.
The cuStateVec library also provides the compute type, allowing computation with reduced precision. Some cuStateVec functions accept the compute type specified by using custatevecComputeType_t.
Below is the table of combinations of state vector and compute types available in the current version of the cuStateVec library.
State vector / cudaDataType_t |
Matrix / cudaDataType_t |
Compute / custatevecComputeType_t |
|---|---|---|
Complex 128 / CUDA_C_F64 |
Complex 128 / CUDA_C_F64 |
FP64 / CUSTATEVEC_COMPUTE_64F |
Complex 64 / CUDA_C_F32 |
Complex 128 / CUDA_C_F64 |
FP32 / CUSTATEVEC_COMPUTE_32F |
Complex 64 / CUDA_C_F32 |
Complex 64 / CUDA_C_F32 |
FP32 / CUSTATEVEC_COMPUTE_32F |
Note
CUSTATEVEC_COMPUTE_TF32 is not available at this version.
Workspace¶
The cuStateVec library internally manages temporary device memory for executing functions, which is referred to as context workspace.
The context workspace is attached to the cuStateVec context and allocated when a cuStateVec context is created by calling custatevecCreate(). The default size of the context workspace is chosen to cover most typical use cases, obtained by calling custatevecGetDefaultWorkspaceSize().
When the context workspace cannot provide enough amount of temporary memory or when a device memory chunk is shared by two or more functions, there are two options for users:
Users can provide user-managed device memory for the extra workspace. Functions that need the extra workspace have their sibling functions suffixed by
GetWorkspaceSize(). If these functions return a nonzero value via theextraBufferSizeInBytesargument, users are requested to allocate a device memory and supply the pointer to the allocated memory to the corresponding function. The extra workspace should be 256-byte aligned, which is automatically satisfied by usingcudaMalloc()to allocate device memory. If the size of the extra workspace is not enough, CUSTATEVEC_STATUS_INSUFFICIENT_WORKSPACE is returned.Users also can set a device memory handler. When it is set to the cuStateVec library context, the library can directly draw memory from the pool on users’s behalf. In this case, users are not required to allocate device memory explicitly and a null pointer (zero size) can be specified as the extra workspace (size) in the function. Please refer to custatevecDeviceMemHandler_t and custatevecSetDeviceMemHandler() for details.
Gate fusion¶
Gate applications account for large proportion of the computation cost in quantum simulators. We can reduce the overall memory footprint required in gate applications by fusing multiple gates into one larger gate.
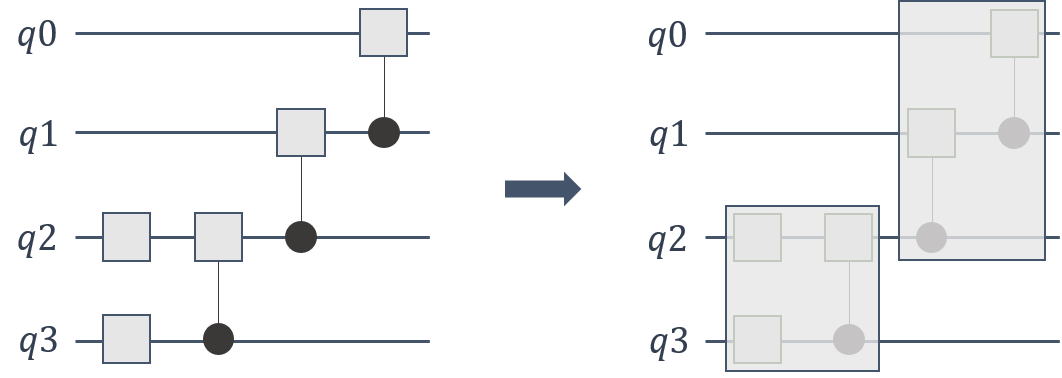
cuStateVec API supports these general gate applications with multiple qubits.
For the detailed availability, please refer to custatevecApplyMatrix().
Multi-GPU Computation¶
The memory usage in quantum circuit simulations increases exponentially with the number of qubits. To simulate more qubits, multiple GPUs are required. A typical approach is to divide the qubits into global and local ones. For an \(M\)-qubit system, suppose each GPU can store \(2^N\) state vector elements (for \(N\) local qubits), then \(2^{M-N}\) GPUs (that is, \(M-N\) global qubits) are required to store the entire state vector. The \(k\)-th GPU (\(k = (i_{M-1} i_{M-2} \cdots i_{N})_2\)) stores the state vector elements \(\alpha_{i_{M-1} i_{M-2} \cdots i_{N} i_{N-1} \cdots i_{0}}\) with \(i_p \in \{0, 1\}, 0 \leq p \leq N-1\).
For instance,
GPU #0 handles elements from \(\alpha_{0_{M-1} \cdots 0_{N+1} 0_{N} 0_{N-1} \cdots 0_{0}}\) to \(\alpha_{0_{M-1} \cdots 0_{N+1} 0_{N} 1_{N-1} \cdots 1_{0}}\),
GPU #1 handles elements from \(\alpha_{0_{M-1} \cdots 0_{N+1} 1_{N} 0_{N-1} \cdots 0_{0}}\) to \(\alpha_{0_{M-1} \cdots 0_{N+1} 1_{N} 1_{N-1} \cdots 1_{0}}\)
GPU #2 handles elements from \(\alpha_{0_{M-1} \cdots 1_{N+1} 0_{N} 0_{N-1} \cdots 0_{0}}\) to \(\alpha_{0_{M-1} \cdots 1_{N+1} 0_{N} 1_{N-1} \cdots 1_{0}}\)
GPU #3 handles elements from \(\alpha_{0_{M-1} \cdots 1_{N+1} 1_{N} 0_{N-1} \cdots 0_{0}}\) to \(\alpha_{0_{M-1} \cdots 1_{N+1} 1_{N} 1_{N-1} \cdots 1_{0}}\), and so on.
Here, the indices \(i_{M-1}, i_{M-2}, \cdots, i_{N}\) belong to the global qubits, and others belong to the local qubits.
cuStateVec provides APIs for multi-GPU qubit measurement and sampling. These APIs work on single GPU, and users are required to gather/scatter the results of each GPU. As for details, please refer to Batched Single Qubit Measurement and Sampling.
Also for those who are interested in multi-GPU quantum simulations, NVIDIA cuQuantum Appliance is available.
Note
Each GPU requires its own cuStateVec handle. Also, the users are responsible for switching the CUDA device context.