Cascaded Compression#
Cascaded compression is a general compression scheme that is ideally suited for analytical workloads. It uses a series of low-level compression building blocks that can be used in combination. Since there are many possible combinations of these building blocks, Cascaded compression can be configured in several different ways. Below is a brief overview of each low-level building block compression scheme.
A more detailed description of each algorithm is available in the GTC 2020 presentation “Software-Based Compression for Analytical Workloads”.
Run-Length Encoding (RLE)#
Run-length encoding is a very simple encoding scheme that compresses repeated values into a single pair: the value and run length (number of repetitions). Since RLE only compresses repeated duplicates, its performance is highly dependent on the input dataset. Note that performing RLE on a sequence of inputs results in two sequences: values and runs. Thus, if every run is of length 1 (no duplicate consecutive values), RLE can result in an expansion of the input by a factor of 2.
Example:
3 9 9 4 4 4 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 -> (3,1) (9,2) (4,3) (0,10) (1,6)
For encoding (compression), nvCOMP uses the low-level RLE kernel available in the CUB library. Overall, the approach is simply to identify the start of each run and compute their lengths. In parallel, we identify the start of each run by having each thread check if a pair of consecutive values differ. We then use a prefix sum operation to compute the length of each run.
Decoding (decompression) is accomplished by first performing a prefix sum on the run lengths to compute the output index of the start of each run. We then simply write the duplicates out for each run, being careful to have sufficient parallelism when writing out large runs.
Delta Encoding#
Delta encoding involves representing each value by its differential (or delta) relative to the previous value in the sequence. While it does not directly compress itself, it provides two potential benefits: 1) reducing the range of values, allowing further compression with bitpacking (described below), and 2) creating more consecutive duplicates that can be compressed by a later RLE step.
Example:
15000 15001 15002 15003 15004 15204 15104 15103 15102 15101 15100 -> 15000 1 1 1 1 200 -100 -1 -1 -1 -1
We can efficiently perform Delta encoding (compression) on the GPU by simply computing the difference between every pair of consecutive values in a thread-parallel manner.
Decoding (decompression) is performed by a simple exclusive prefix sum operation, which we perform using the CUB library implementation.
Bitpacking#
Bitpacking is a bit-level operation that aims to reduce the number of bits required to store each value. It does this by using only as many bits as needed to represent the range of values that are found in the input data. If the input uses B bits per value and we can pack them into b bits per value, then the achieved compression ratio is approximately B/b.
Example:
15000 15001 15002 15003 15004 15204 15104 15103 15102 15101 15100 -> min:15000, 0 1 2 3 4 204 104 103 102 101 100
Resulting values are all < 256, so each compressed value requires only 8 bits.
The bitpacking compression algorithm has two steps: 1) find min and max values, and 2) encode the input data. We can efficiently find the min and max values with a parallel scan and reduction operation. Once the min and max values are found, the range is computed as max-min, giving us the number of bits, b, needed for each value. We then encode every value in the dataset as val-min, represented using only b bits. We store this encoding along with min as the final compressed bitstring. Note that, if b is not a multiple of the machine word size (32), some symbols may straddle multiple words. We take special care to handle these cases, and details are available in the GTC 2020 presentation “Software-Based Compression for Analytical Workloads”.
Unpacking (decompression) involves computing the full value of each encoded symbol (symbol + min) and writing it out using the full B bits. Since we know B, we can easily compute the output location of each value and perform this in a thread-parallel manner.
The only portion of the cascaded compressor that depends on whether the
specified data type is signed or unsigned is the finding of min and max
values for bitpacking when compressing with no delta encoding, since for
a signed data type, values greater than the maximum signed value will be
interpreted as negative, whereas for an unsigned data type, they will be
interpreted as positive. This means that if the data to be compressed
represent integers that can only be positive, and no delta encoding is
used, it may be beneficial in some cases to specify an unsigned data
type, such as uchar or uint, instead of a signed data type, such
as char or int.
Combining into a Cascaded scheme#
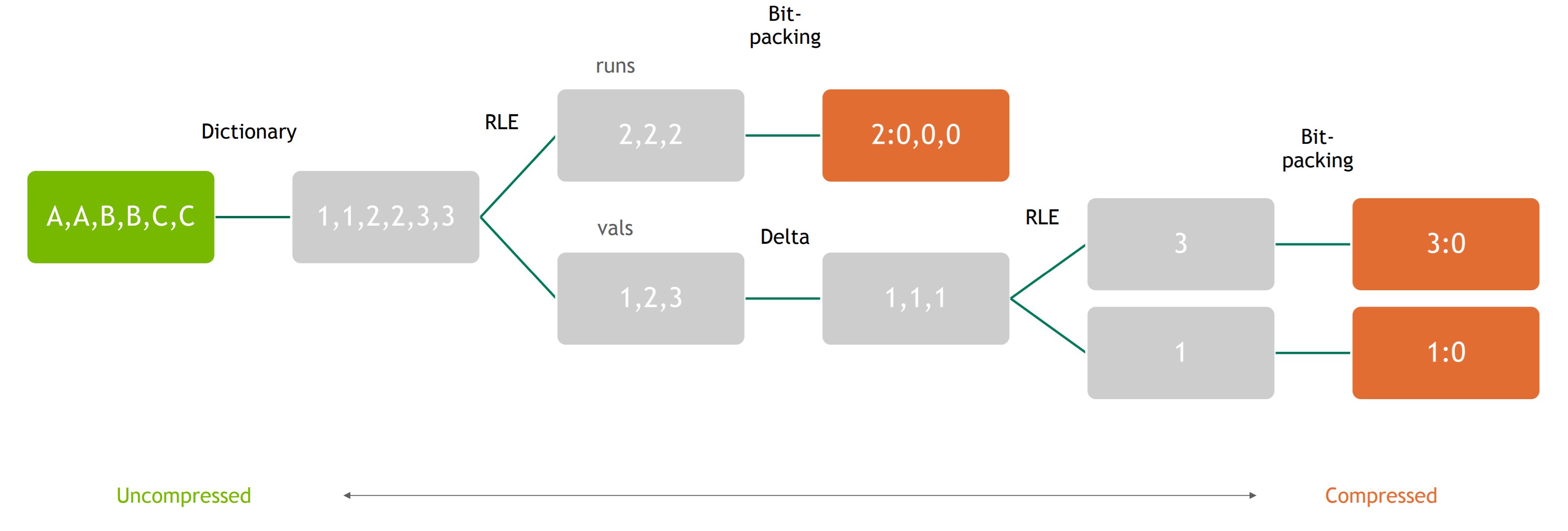
Using the RLE, Delta, and bitpacking building blocks, we can assemble various cascaded schemes. We define each scheme by the number of RLEs, Deltas, and whether bitpacking is enabled. Thus, 2 2 1 would be a cascaded compression scheme with 2 RLEs, 2 Deltas, and bitpacking enabled. Layers of RLE and Delta are interleaved. The building block compression schemes are then connected together in the following way: RLEs and Deltas are interleaved, with the values output from RLE used as input to Delta. Once all RLEs and Deltas are finished, bitpacking is performed on all resulting data (runs and values).
The Cascaded compression scheme is available with both C and C++ API
calls, and each is configurable by passing the API calls a compression
format. In the C and C++ APIs, the compression call takes a
nvcompBatchedCascadedCompressOpts_t structure that has 5 fields:
internal_chunk_bytes, type, num_RLEs, num_deltas, and use_bp.
The example below illustrates a 2 1 1 (RLE=2, Delta=1, bitpacking=1) cascaded scheme.