Graph API#
For general information about cuDNN graphs, refer to Graphs in the Frontend Developer Guide. Use the cuDNN frontend to access the cuDNN Graph API unless you want to use legacy fixed-function routines or if you need a C-only graph API.
Backend Native CUDA Graph API#
For general information about the Native CUDA Graph API, refer to Native CUDA Graph API in the Frontend Developer Guide. Use the cuDNN frontend to access this API unless you want to use legacy fixed-function routines or if you need a C-only interface.
The backend native CUDA graph API consists of two functions:
Specialized Runtime Fusion Engines#
Unless you need a C-only graph API, use the following cuDNN frontend runtime fusion engines:
Fused Attention fprop#
Mha-Fprop fusions \(O=matmul\left( S=g_{4} \left( P=matmul\left( Q, g_{3}\left( K \right) \right), V \right)\right)\) have been added to the runtime fusion engine to serve patterns that are commonly used in attention. These patterns can be used in BERT, T5, and so on.
There are two key differences to the flash fused attention patterns described in later sections:
Input sizes supported contain small sequence lengths (<= 512).
The operation graph is flexible to switch between different types of masks, different operations between the two matrix multiplications, and so on.

g 3 can be an empty graph or a single scale operation with the scale being a scalar value (CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_MUL).
g 4 can be empty or the combination of the following DAGs of cuDNN operations. Each of these DAGs is optional, as shown by the dotted line.

The combination has to obey the order in which we present them. For example, if you want to use the padding mask and softmax, the padding mask has to appear before softmax.
These operations are commonly used in attention. In the following diagram, we depict how to create a DAG for each of the operations. In later versions, we will be expanding the possible DAGs for g 3 and g 4.
Padding Mask
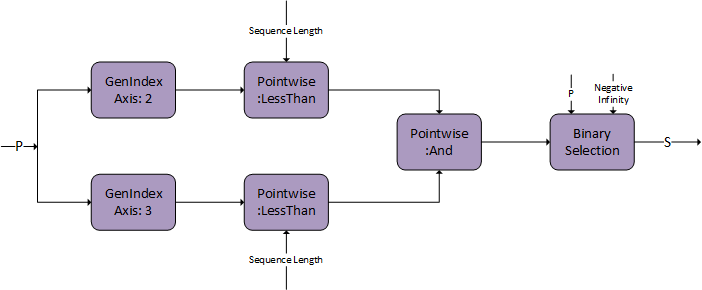
Causal Mask

Softmax

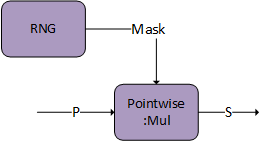
Dropout
g 4 is capable of storing an intermediate tensor to global memory marked as S, which can be used for fused multi-head attention bprop. Both DAG:Softmax and DAG:Dropout have this capability. Set S as the output from the last DAG in the graph.
The tensor descriptor marked as S must have the CUDNN_ATTR_TENSOR_REORDERING_MODE set to CUDNN_TENSOR_REORDERING_F16x16. This is because the tensor is stored in a special format and can only be consumed by fused attention bprop.
There is an additional option of generating the mask on the user end and passing it directly to the pointwise multiplier. The mask needs to be of I/O data type FP16/BF16 and S will store the mask in the sign bit to communicate to bprop.
Limitation |
|
|---|---|
Matmul |
|
Pointwise operations in g 3 and g 4 |
Compute type must be |
Reduction operations in g 3 and g 4 |
I/O types and compute types must be |
RNG operation in g 3 and g 4 |
|
Layout requirements of Mha-fprop fusions include:
All I/O tensors must have 4 dimensions, with the first two denoting the batch dimensions. The usage of rank-4 tensors in
matmulops can be read from the Backend Descriptor Types documentation.The contracting dimension (dimension
K) for the first matmul must be 64.The non-contracting dimension (dimensions
MandN) for the first matmul must be less than or equal to 512. In inference mode, any sequence length is functional. For training, support exists only for multiples of 64.The last dimension (corresponding to hidden dimensions) in
Q,V, andOis expected to have stride1.For the
Ktensor, the stride is expected to be1for the 2nd last dimension.The
Stensor is expected to haveCUDNN_ATTR_TENSOR_REORDERING_MODEset toCUDNN_TENSOR_REORDERING_F16x16.
Fused Attention bprop#
Mha-Bprop fusions are executed in a fused pattern in a single kernel.
\(dV=matmul\left( g_{5}\left( S \right), dO \right)\) \(dS=matmul\left( dO, VT\right)\) \(dQ=matmul\left( g_{6}\left( dS \right), K \right)\) \(dK=matmul\left( Q, g_{7}\left( dS \right)\right)\)
cuDNN supports the corresponding backpropagation graph for fused attention. This can be used together with the fused attention fprop graph to perform training on models that have similar architectures to BERT and T5. This is not compatible with the flash fused attention bprop operation graph.
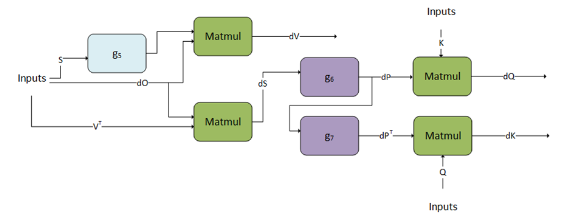
g 5, g 6, and g 7 can only support a fixed DAG. We are working towards generalizing these graphs.

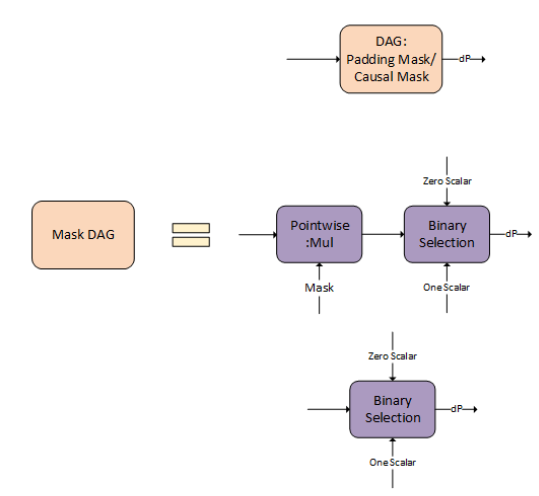
g 6 represents the backward pass of softmax and masking, to get dP.
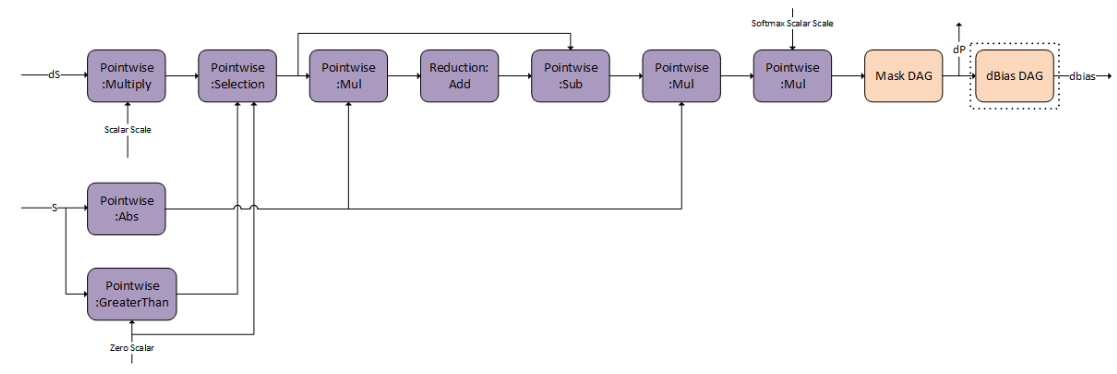
There are options for the Mask DAG that you can opt-in. You can either use the padding/causal mask, general mask as an input, or not do any masking.
dBias DAG is useful to calculate the bprop of the relative positional encoding and is optional and available for you to opt-in.

g 7 is the transpose of dP the output of g 6.

Limitation |
|
|---|---|
Matmul |
|
Pointwise operations in g 5, g 6, and g 7 |
Compute type must be |
Reduction operations in g 5, g 6, and g 7 |
I/O types and compute types must be |
Layout requirements of Mha-bprop fusions include:
All I/O tensors must have 4 dimensions, with the first two denoting the batch dimensions. The usage of rank-4 tensors in
matmulops can be read from the Backend Descriptor Types documentation.The contracting dimension (dimension
K) for the second matmul must be 64.The contracting dimension (dimension
K) for the first, second, and third matmul must be less than or equal to 512 and a multiple of 64.The last dimension (corresponding to hidden dimensions) in
Q,K,V,O, anddOis expected to have stride1.The
SanddPtensors are expected to haveCUDNN_ATTR_TENSOR_REORDERING_MODEset toCUDNN_TENSOR_REORDERING_F16x16.