Graph API#
Backend Native CUDA Graph API#
The backend native CUDA graph API consists of two functions:
For general information about this API, refer to Native CUDA Graph API in the Frontend Developer Guide.
Graph API Example with Operation Fusion#
The following example implements a fusion of convolution, bias, and activation.
Creating Operation and Tensor Descriptors to Specify the Graph Dataflow#
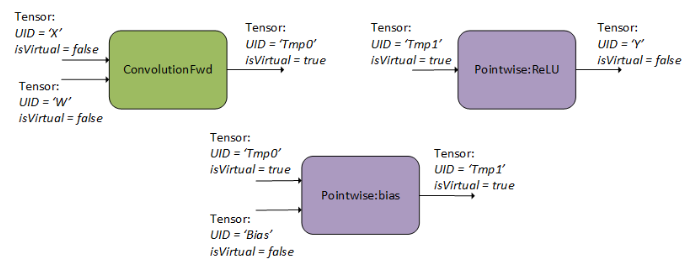
First, create three cuDNN backend operation descriptors.
In the following figure, the user specified one forward convolution operation (using CUDNN_BACKEND_OPERATION_CONVOLUTION_FORWARD_DESCRIPTOR), a pointwise operation for the bias addition (using CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_ADD), and a pointwise operation for the ReLU activation (using CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_RELU_FWD). Refer to the Backend Descriptor Types for more details on setting the attributes of these descriptors. For an example of how a forward convolution can be set up, refer to the Setting Up An Operation Graph For A Grouped Convolution use case.
You should also create tensor descriptors for the inputs and outputs of all of the operations in the graph. The graph dataflow is implied by the assignment of tensors, for example, by specifying the backend tensor Tmp0 as both the output of the convolution operation and the input of the bias operation, cuDNN infers that the dataflow runs from the convolution into the bias. The same applies to tensor Tmp1. If the user doesn’t need the intermediate results Tmp0 and Tmp1 for any other use, then the user can specify them to be virtual tensors, so the memory I/Os can later be optimized out.
Graphs with more than one operation node do not support in-place operations (that is, where any of the input UIDs matches any of the output UIDs). Such in-place operations are considered cyclic in later graph analysis and deemed unsupported. In-place operations are supported for single-node graphs.
The operation descriptors can be created and passed into cuDNN in any order, as the tensor UIDs are enough to determine the dependencies in the graph.
Finalizing The Operation Graph#
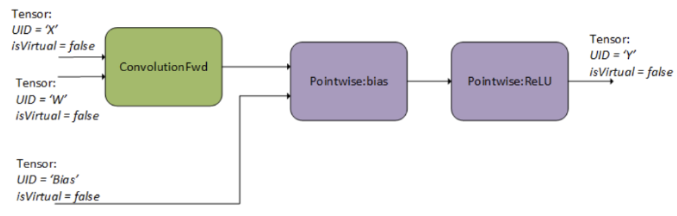
Second, the user finalizes the operation graph. As part of finalization, cuDNN performs the dataflow analysis to establish the dependency relationship between operations and connect the edges, as illustrated in the following figure. In this step, cuDNN performs various checks to confirm the validity of the graph.
Configuring An Engine That Can Execute The Operation Graph#
Third, given the finalized operation graph, the user must select and configure an engine to execute that graph, which results in an execution plan. As mentioned in Heuristics, the typical way to do this is:
Query heuristics mode A or B.
Look for the first engine config with functional support (or auto-tune all the engine configs with functional support).
If no engine config was found in (2), try querying the fallback heuristic for more options.
Executing The Engine#
Finally, with the execution plan constructed and when it comes time to run it, the user should construct the backend variant pack by providing the workspace pointer, an array of UIDs, and an array of device pointers. The UIDs and the pointers should be in the corresponding order. With the handle, the execution plan and variant pack, the execution API can be called and the computation is carried out on the GPU.