TTS Overview
Contents
TTS Overview#
The text-to-speech (TTS) pipeline implemented for the Riva TTS service is based on a two-stage pipeline. Riva first generates a mel-spectrogram using the first model, and then generates speech using the second model. This pipeline forms a TTS system that enables you to synthesize natural sounding speech from raw transcripts without any additional information such as patterns or rhythms of speech.
Riva TTS supports both streaming and batch inference modes. In batch mode, audio is not returned until the full audio sequence for the requested text is generated and can achieve higher throughput. When making a streaming request, audio chunks are returned as soon as they are generated, significantly reducing the latency (as measured by time to first audio) for large requests.
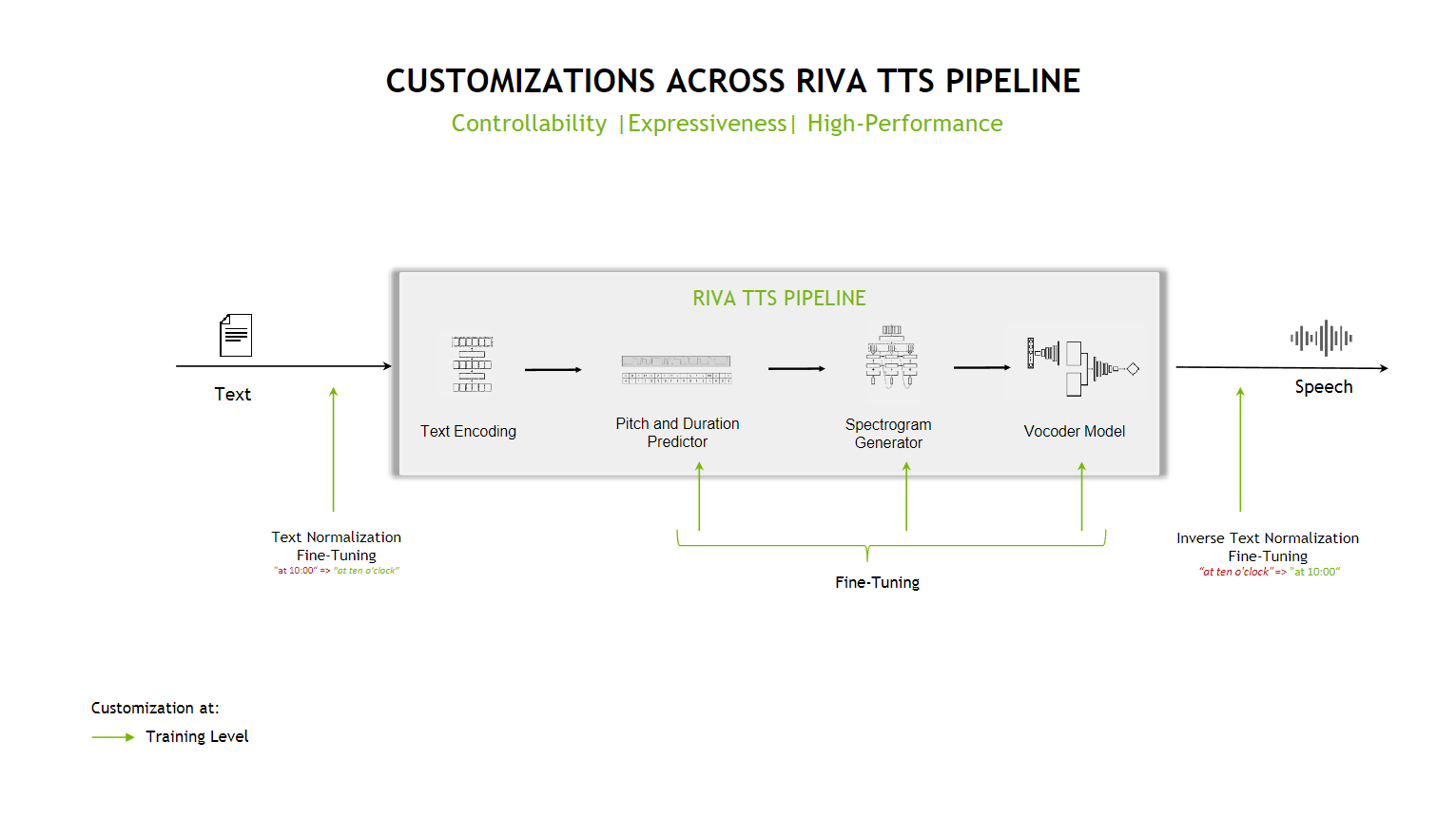
Try It Out#
Voices#
Language |
Language Code |
Gender |
Voice Name |
Sample |
|---|---|---|---|---|
English |
en-US |
Female |
|
|
English |
en-US |
Male |
|
Note
New in version 2.5.0: The Riva Quick Start scripts downloads a single model that enables both voices. Specify the requested TTS voice name in the Riva TTS request to change the voice.