ASR Overview
Contents
ASR Overview#
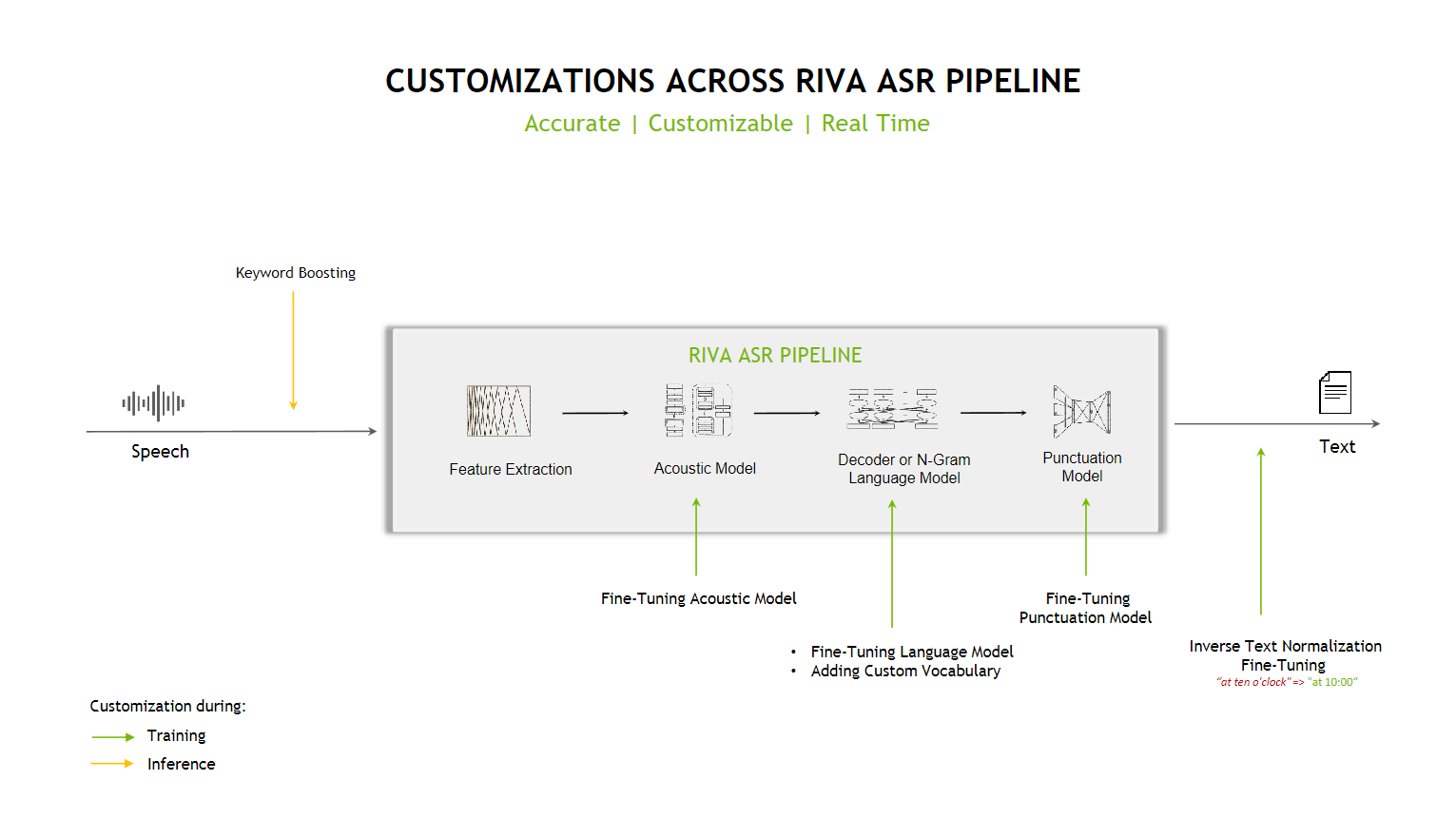
Automatic Speech Recognition (ASR) takes an audio stream or audio buffer as input and returns one or more text transcripts, along with additional optional metadata. Speech recognition in Riva is a GPU-accelerated compute pipeline, with optimized performance and accuracy. Riva supports offline/batch and streaming recognition modes.
Try It Out#
Language Support#
Riva Speech AI Skills provides high-quality pretrained models across a variety of languages. Upgraded models and new languages are released regularly.
Language |
Language Code |
Acoustic Model |
Language Model |
Punctuation |
Text Norm |
Pipeline |
|---|---|---|---|---|---|---|
English |
en-US |
✅ (35000 hrs) |
✅ |
✅ |
✅ |
|
Spanish |
es-US |
✅ (2800 hrs) |
✅ |
✅ |
✅ |
|
Spanish |
es-ES |
✅ (1100 hrs) |
✅ |
✅ |
❌ |
|
German |
de-DE |
✅ (3500 hrs) |
✅ |
✅ |
✅ |
|
French |
fr-FR |
✅ (3320 hrs) |
✅ |
✅ |
✅ |
|
Hindi |
hi-IN |
✅ (1908 hrs) |
✅ |
✅ |
❌ |
|
Russian |
ru-RU |
✅ (2600 hrs) |
✅ |
❌ |
❌ |
|
English |
en-GB |
✅ (1000 hrs) |
✅ |
✅ |
❌ |
|
Korean |
ko-KR |
✅ (3500 hrs) |
✅ |
✅ |
❌ |
|
Brazilian-Portuguese |
pt-BR |
✅ (3200 hrs) |
✅ |
✅ |
❌ |
|
Japanese |
ja-JP |
✅ (1600 hrs) |
✅ |
✅ |
❌ |
|
Italian |
it-IT |
✅ (2700 hrs) |
✅ |
✅ |
❌ |
|
Arabic |
ar-AR |
✅ (1100 hrs) |
✅ |
✅ |
✅ |
|
Mandarin* |
zh-CN |
✅ (4100 hrs) |
✅ |
✅ |
❌ |
To select which language to deploy, simply change the variable language_code in the config.sh file within the quickstart directory of the Quick Start scripts.
Currently, Speech hints is supported only with English(en-US).
Features#
Riva ASR features include:
Support for offline and streaming use cases
A streaming mode that returns intermediate transcripts with low latency
GPU-accelerated feature extraction
Multiple (and growing) acoustic model architecture options accelerated by NVIDIA TensorRT
Beam search decoder based on n-gram language models
Voice activity detection algorithms (CTC-based)
Automatic punctuation
Ability to return top-N transcripts from beam decoder
Word-level timestamps
Word-level confidences
Inverse Text Normalization (ITN)
Offline non-overlapping Speaker Diarization
Speech hints
For more information, refer to the Speech to Text Citrinet Notebook and the Speech to Text Jasper and QuartzNet Notebook. These notebooks provide an end-to-end workflow for speech recognition. This workflow starts with training in TAO Toolkit and ends with deployment using Riva.
Offline Recognition#
In offline or batch mode, the full audio signal is first read from a file or captured from a microphone. Following the capture of the entire signal, the client makes a request to the Riva Speech AI server to transcribe it. The client then waits for the response from the server.
Tip
This method can have long latency because the processing of the audio signal begins only after the full audio signal has been captured or read from the file.
Streaming Recognition#
In streaming recognition mode, as soon as an audio segment of a specified length is captured or read, a request is made to the server to process that segment. On the server side, a response is returned as soon as an intermediate transcript is available.
Note
You can select the length of the audio segments based on speed and memory requirements.
Refer to the riva/proto/riva_asr.proto documentation for more details.
Offline Recognition with Non-Overlapping Speaker Diarization#
When the ASR offline client is run with speaker diarization enabled, the audio data is sent as input to the Riva Speech AI server. The server then returns an ASR transcript to the client as output, along with a speaker tag for each word in the transcript.
Multiple Deployed Models#
The Riva server supports multiple speech recognition models deployed simultaneously, up to the limit of your GPU’s memory. As such, a single-server process can host models tailored for streaming or batch, various languages, accents, or channel characteristics.
When receiving requests from the client application, the Riva server selects the deployed ASR model
to use based on the RecognitionConfig of the client request. If no models are available to fulfill
the request, an error is returned. In the case where multiple models might be able to fulfill the
client request, one model is selected at random. You can also explicitly select which ASR model
to use by setting the model field of the RecognitionConfig protobuf object to the value of
<pipeline_name> which was used with the riva-build command. This enables you to deploy
multiple ASR pipelines concurrently and select which one to use at runtime.
Checking deployed models#
Once a server is running retrieving the available models can be done via the GetRivaSpeechRecognitionConfig rpc. For each model availble to make inference requets, the rpc returns the parameters used when the model was deployed.