Models And Schedulers¶
By incorporating multiple frameworks and also custom backends, the TensorRT Inference Server supports a wide variety of models. The inference server also supports multiple scheduling and batching configurations that further expand the class of models that the inference server can handle.
This section describes stateless, stateful and ensemble models and how the inference server provides schedulers to support those model types.
Stateless Models¶
With respect to the inference server’s schedulers, a stateless model (or stateless custom backend) does not maintain state between inference requests. Each inference performed on a stateless model is independent of all other inferences using that model.
Examples of stateless models are CNNs such as image classification and object detection. The default scheduler or dynamic batcher can be used for these stateless models.
RNNs and similar models which do have internal memory can be stateless as long as the state they maintain does not span inference requests. For example, an RNN that iterates over all elements in a batch is considered stateless by the inference server if the internal state is not carried between inference requests. The default scheduler can be used for these stateless models. The dynamic batcher cannot be used since the model is typically not expecting the batch to represent multiple inference requests.
Stateful Models¶
With respect to the inference server’s schedulers, a stateful model (or stateful custom backend) does maintain state between inference requests. The model is expecting multiple inference requests that together form a sequence of inferences that must be routed to the same model instance so that the state being maintained by the model is correctly updated. Moreover, the model may require that the inference server provide control signals indicating, for example, sequence start.
The sequence batcher must be used for these stateful models. As explained below, the sequence batcher ensures that all inference requests in a sequence get routed to the same model instance (and batch slot) so that the model can maintain state correctly. The sequence batcher also communicates with the model to indicate when a sequence is starting and when a sequence has a inference request ready for execution.
As explained in Client API for Stateful Models, when making inference requests for a stateful model, the client application must provide the same correlation ID to all requests in a sequence, and must also mark the start and end of the sequence. The correlation ID allows the inference server to identify that the requests belong to the same sequence.
As a running example, assume a TensorRT stateful model that has the following model configuration:
name: "stateful_model"
platform: "tensorrt_plan"
max_batch_size: 2
sequence_batching {
max_sequence_idle_microseconds: 5000000
control_input [
{
name: "START"
control [
{
kind: CONTROL_SEQUENCE_START
fp32_false_true: [ 0, 1 ]
}
]
},
{
name: "READY"
control [
{
kind: CONTROL_SEQUENCE_READY
fp32_false_true: [ 0, 1 ]
}
]
}
]
}
input [
{
name: "INPUT"
data_type: TYPE_FP32
dims: [ 100, 100 ]
}
]
output [
{
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 10 ]
}
]
instance_group [
{
count: 2
}
]
The sequence_batching section indicates that the model should use the sequence batcher. The instance_group indicates two instances of the model should be instantiated and max_batch_size indicates that each of those instances should perform batch-size 2 inferences. The following figure shows a representation of the sequence batcher and the inference resources specified by this configuration.

Each model instance is maintaining state for each batch slot, and is expecting all inference requests for a given sequence to be routed to the same slot so that the state is correctly updated. For this example that means that the inference server can simultaneously perform inference for up to four sequences.
The sequence batcher:
Recognizes when an inference request starts a new sequence and allocates a slot for that sequence. If no slot is available for the new sequence, the server places the inference request in a backlog.
Recognizes when an inference request is part of a sequence that has an allocated slot and routes the request to that slot.
Recognizes when an inference request is part of a sequence that is in the backlog and places the request in the backlog.
Recognizes when the last inference request in a sequence has been completed. The slot occupied by that sequence is immediately reallocated to a sequence in the backlog, or freed for a future sequence if there is no backlog.
The following figure shows how multiple sequences are scheduled onto the model instances. On the left the figure shows several sequences of requests arriving at the inference server. Each sequence could be made up of any number of inference requests and those individual inference requests could arrive in any order relative to inference requests in other sequences, except that the execution order shown on the right assumes that the first inference request of sequence 0 arrives before any inference request in sequences 1-5, the first inference request of sequence 1 arrives before any inference request in sequences 2-5, etc.
The right of the figure shows how the inference request sequences are scheduled onto the model instances over time.

For a stateful model to configure the sequence batcher, the model must accept two input tensors that the inference server uses to communicate with the model. The control_input section of the sequence batcher configuration indicates how the model exposes the tensors.
Start: The start input tensor is specified using CONTROL_SEQUENCE_START in the configuration. The example configuration indicates that the model has an input tensor called START with a 32-bit floating point data-type. The inference server will define this tensor when executing an inference on the model. The tensor provided by the inference server will be 1-dimensional with size equal to the batch-size. Each element in the tensor indicates if the sequence in the corresponding slot is starting or not. In the example configuration, fp32_false_true indicates that a sequence start is indicated by tensor element equal to 1, and non-start is indicated by tensor element equal to 0.
Ready: The ready input tensor is specified using CONTROL_SEQUENCE_READY in the configuration. The example configuration indicates that the model has an input tensor called READY with a 32-bit floating point data-type. The inference server will define this tensor when executing an inference on the model. The tensor provided by the inference server will be 1-dimensional with size equal to the batch-size. Each element in the tensor indicates if the sequence in the corresponding slot has an inference request ready for inference. In the example configuration, fp32_false_true indicates that a sequence ready is indicated by tensor element equal to 1, and non-start is indicated by tensor element equal to 0.
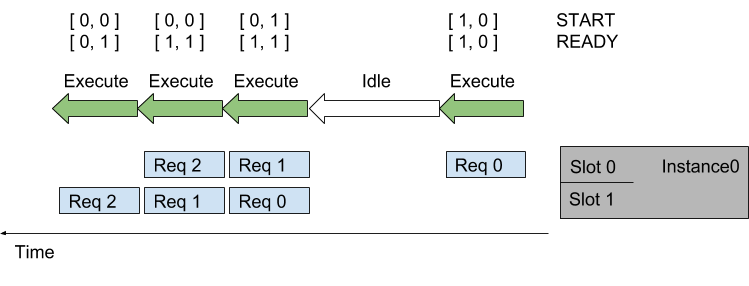
The following figure shows the inference server uses the control input tensors to communicate with the model. The figure shows two sequences assigned to the two slots in a model instance. Inference requests for each sequence arrive over time. The START and READY rows show the input tensor values used for each execution of the model. Over time the following happens:
The first request arrives for the sequence in slot0. Assuming the model instance is not already executing an inference, the sequence scheduler immediately schedules the model instance to execute because an inference request is available.
This is the first request in the sequence so the corresponding element in the START tensor is set to 1. There is no request available in slot1 so the READY tensor shows only slot0 as ready.
After the inference completes the sequence scheduler sees that there are no requests available in any slot and so the model instance sits idle.
Next, two inference requests arrive close together in time so that the sequence scheduler sees them both available in their respective slots. The scheduler immediately schedules the model instance to perform a batch-size 2 inference and uses START and READY to show that both slots have an inference request avaiable but that only slot1 is the start of a new sequence.
The processing continues in a similar manner for the other inference requests.
Ensemble Models¶
An ensemble model represents a pipeline of one or more models and the connection of input and output tensors between those models. Ensemble models are intended to be used to encapsulate a procedure that involves multiple models, such as “data preprocessing -> inference -> data postprocessing”. Using ensemble models for this purpose can avoid the overhead of transferring intermediate tensors and minimize the number of requests that must be sent to the inference server.
The ensemble scheduler must be used for
ensemble models, regardless of the scheduler used by the models within the
ensemble. With respect to the ensemble scheduler, an ensemble model is not
an actual model. Instead, it specifies the dataflow between models within the
ensemble as Step. The
scheduler collects the output tensors in each step, provides them as input
tensors for other steps according to the specification. In spite of that, the
ensemble model is still viewed as a single model from an external view.
Ensemble Image Classification Example Application is an example that performs
image classification using an ensemble model.
Note that the ensemble models will inherit the characteristics of the models involved, so the meta-data in the request header must comply with the models within the ensemble. For instance, if one of the models is stateful model, then the inference request for the ensemble model should contain the information mentioned in the previous section, which will be provided to the stateful model by the scheduler.
As a running example, consider an ensemble model for image classification and segmentation that has the following model configuration:
name: "ensemble_model"
platform: "ensemble"
max_batch_size: 1
input [
{
name: "IMAGE"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
output [
{
name: "CLASSIFICATION"
data_type: TYPE_FP32
dims: [ 1000 ]
},
{
name: "SEGMENTATION"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
ensemble_scheduling {
step [
{
model_name: "image_preprocess_model"
model_version: -1
input_map {
key: "RAW_IMAGE"
value: "IMAGE"
}
output_map {
key: "PREPROCESSED_OUTPUT"
value: "preprocessed_image"
}
},
{
model_name: "classification_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "CLASSIFICATION_OUTPUT"
value: "CLASSIFICATION"
}
},
{
model_name: "segmentation_model"
model_version: -1
input_map {
key: "FORMATTED_IMAGE"
value: "preprocessed_image"
}
output_map {
key: "SEGMENTATION_OUTPUT"
value: "SEGMENTATION"
}
}
]
}
The ensemble_scheduling section indicates that the ensemble scheduler will be used and that the ensemble model consists of three different models. Each element in step section specifies the model to be used and how the inputs and outputs of the model are mapped to tensor names recognized by the scheduler. For example, the first element in step specifies that the latest version of image_preprocess_model should be used, the content of its input “RAW_IMAGE” is provided by “IMAGE” tensor, and the content of its output “PREPROCESSED_OUTPUT” will be mapped to “preprocessed_image” tensor for later use. The tensor names recognized by the scheduler are the ensemble inputs, the ensemble outputs and all values in the input_map and the output_map.
Assuming that only the ensemble model, the preprocess model, the classification model and the segmentation model are being served, the client applications will see them as four different models which can process requests independently. However, the ensemble scheduler will view the ensemble model as the following.
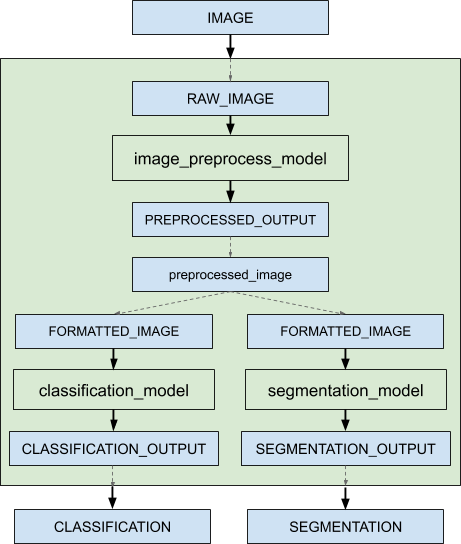
When an inference request for the ensemble model is received, the ensemble scheduler will:
Recognize that the “IMAGE” tensor in the request is mapped to input “RAW_IMAGE” in the preprocess model.
Check models within the ensemble and send an internal request to the preprocess model becuase all the input tensors required are ready.
Recognize the completion of the internal request, collect the output tensor and map the content to “preprocessed_image” which is an unique name known within the ensemble.
Map the newly collected tensor to inputs of the models within the ensemble. In this case, the inputs of “classification_model” and “segmentation_model” will be mapped and marked as ready.
Check models that require the newly collected tensor and send internal requests to models whose inputs are ready, the classification model and the segmentation model in this case. Note that the responses will be in arbitrary order depending on the load and computation time of individual models.
Repeat step 3-5 until no more internal requests should be sent, and then response to the inference request with the tensors mapped to the ensemble output names.