Add Custom QDQ Insertion Case¶
This toolkit’s default quantization behavior for each supported layer is displayed in the Add New Layer Support section.
For the most part, it quantizes (adds Q/DQ nodes to) all inputs and weights (if the layer is weighted) of supported layers. However, the default behavior might not always lead to optimal INT8 fusions in TensorRT™. For example, Q/DQ nodes need to be added to residual connections in ResNet models. We provide a more in-depth explanation about this case in the “Custom Q/DQ Insertion Case Quantization” section later in this page.
To tackle those scenarios, we added the Custom Q/DQ Insertion Case library feature, which allows users to programmatically decide how a specific layer should be quantized differently in specific situations. Note that providing an object of QuantizationSpec class is a hard coded way of achieving the same goal.
Let’s discuss the library-provided ResNetV1QDQCase to understand how passing custom Q/DQ insertion case objects affect Q/DQ insertion for the Add layer.
Why is this needed?¶
The main goal of the Custom Q/DQ Insertion feature is to twick the framework’s behavior to meet network-specific quantization requirements. Let’s check this through an example.
Goal: Perform custom quantization on a ResNet-like model. More specifically, we aim to quantize a model’s residual connections.
We show three quantization scenarios: 1) default, 2) custom with QuantizationSpec (suboptimal), and 3) custom with Custom Q/DQ Insertion Case (optimal).
Default Quantization¶
Note
Refer to Full Default Quantization mode.
The default quantization of the model is done with the following code snippet:
# Quantize model
q_nn_model = quantize_model(model=nn_model_original)
Figure 1, below, shows the baseline ResNet residual block and its corresponding quantized block with the default quantization scheme.
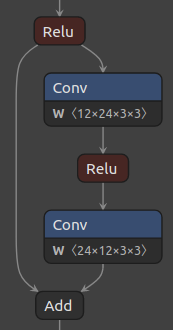
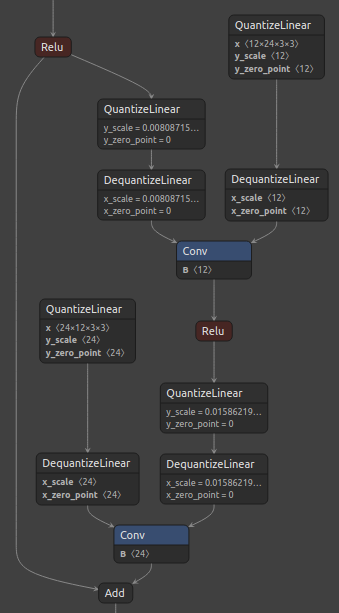
Figure 1. ResNet residual block (left), and default quantized block (right).
Notice that the default quantization behavior is to not add Q/DQ nodes before Add layers. Since AddQuantizeWrapper
is already implemented in the toolkit, and just disabled by default, the simplest way to quantize that layer would be
to enable quantization of layers of class type Add.
Custom Quantization with ‘QuantizationSpec’ (suboptimal)¶
Note
Refer to Full Custom Quantization mode.
The following code snippet enables quantization of all layers of class type Add:
# 1. Enable `Add` layer quantization
qspec = QuantizationSpec()
qspec.add(name='Add', is_keras_class=True)
# 2. Quantize model
q_nn_model = quantize_model(
model=nn_model_original, quantization_spec=qspec
)
Figure 2, below, shows the standard ResNet residual block and its corresponding quantized block with the suggested custom quantization.
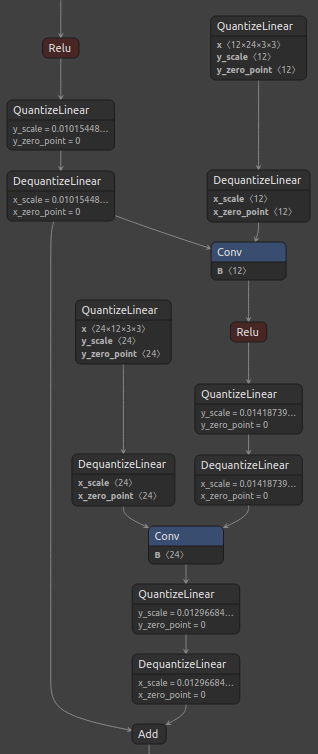
Figure 2. ResNet residual block (left), and Q/DQ node insertion for Add layer passed via QuantizationSpec (right).
Notice that all inputs of the Add layer were quantized. However, that still does not enable optimal layer fusions in TensorRT™, where a Convolution layer followed by an ElementWise layer (such as Add) can be fused into a single Convolution kernel.
The recommendation, in this case, is to add Q/DQ nodes in the residual connection only (not between Add and Conv).
Custom Quantization with ‘Custom Q/DQ Insertion Case’ (optimal)¶
Note
Refer to Full Custom Quantization mode.
The library-provided ResNetV1QDQCase class solves this issue by programming Add layer class to skip Q/DQ in one path if that path connects to Conv.
This time, we pass an object of ResNetV1QDQCase class to the quantize_model function:
# 1. Indicate one or more custom QDQ cases
custom_qdq_case = ResNetV1QDQCase()
# 3. Quantize model
q_nn_model = quantize_model(
model=nn_model_original, custom_qdq_cases=[custom_qdq_case]
)
Figure 3, below, shows the standard ResNet residual block and its corresponding quantized block with the suggested custom quantization.
Figure 3. ResNet residual block (left), and Q/DQ node insertion for Add layer passed via ResNetV1QDQCase (right).
Notice that Q/DQ nodes are not added to the path coming from Conv layer. Additionally, since both outputs of the first Relu layer were quantized, it was possible to perform a horizontal fusion with them, resulting in only one pair of Q/DQ nodes at that location.
This quantization approach leads to an optimal graph for TensorRT INT8 fusions.
Library provided custom Q/DQ insertion cases¶
We provide custom Q/DQ insertion cases for the models available in the model zoo. The library-provided custom Q/DQ insertion case classes can be imported from tensorflow_quantization.custom_qdq_cases module and passed to the quantize_model function.
Note
Refer to tensorflow_quantization.custom_qdq_cases module for more details.
How to add a new custom Q/DQ insertion case?¶
Create a new class by inheriting
tensorflow_quantization.CustomQDQInsertionCaseclass.Override two methods:
case(compulsory)
This method has fixed signature as shown below. Library automatically calls
casemethod of all members ofcustom_qdq_casesparameter insidequantize_modelfunction. Logic for changing the default layer behavior should be encoded in this function and an object ofQuantizationSpecclass must be returned.(function)CustomQDQInsertionCase.case( self, keras_model : 'tf.keras.Model', qspec : 'QuantizationSpec' ) -> 'QuantizationSpec'
info(optional)
This is just a helper method explaining the logic inside
casemethod.Add object of this new class to a list and pass it to the
custom_qdq_casesparameter of thequantize_modelfunction.
Attention
If CustomQDQInsertionCase is written, QuantizationSpec object MUST be returned.
Example,
class MaxPoolQDQCase(CustomQDQInsertionCase):
def __init__(self) -> None:
super().__init__()
def info(self) -> str:
return "Enables quantization of MaxPool layers."
def case(
self, keras_model: tf.keras.Model, qspec: QuantizationSpec
) -> QuantizationSpec:
mp_qspec = QuantizationSpec()
for layer in keras_model.layers:
if isinstance(layer, tf.keras.layers.MaxPooling2D):
if check_is_quantizable_by_layer_name(qspec, layer.name):
mp_qspec.add(
name=layer.name,
quantize_input=True,
quantize_weight=False
)
return mp_qspec
As shown in the above MaxPool custom Q/DQ case class, the case method needs to be overridden. The optional info method returns a short description string.
The logic written in the case method might or might not use the user-provided QuantizationSpec object, but it MUST return a new QuantizationSpec which holds information on the updated layer behavior. In the MaxPoolQDQCase case above, the custom Q/DQ insertion logic is dependent of the user-provided QuantizationSpec object (check_is_quantizable_by_layer_name checks if the layer name is in the user-provided object and gives priority to that specification).