3. Specify Dashboard Configurations#
The dashboard includes two tabs: AI Training and AI Inference.
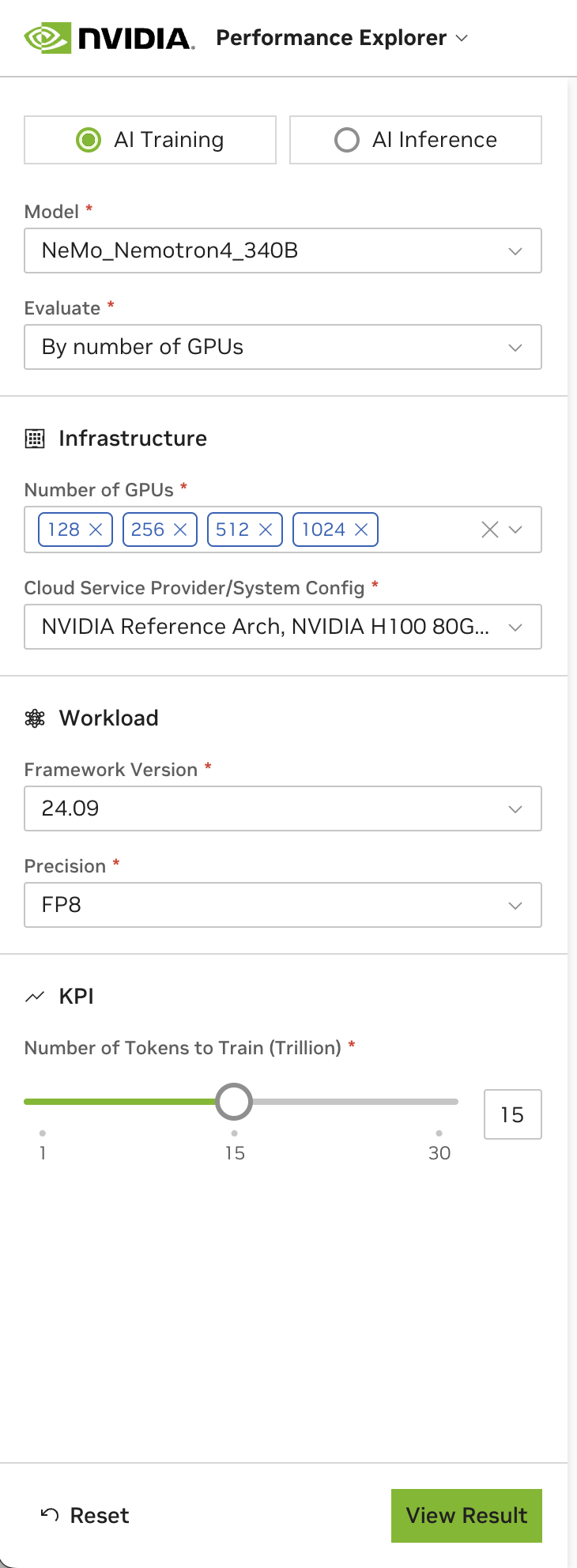
3.1. AI Training#
The AI Training tab provides three configuration guidance cards:
Why Precision Matters: Compare how different precision modes (for example, BF16 and FP8) affect training speed, memory use, and compute costs.
Why Framework Version Matters: Evaluate how framework versions influence accuracy, speed, and reproducibility.
Why Cluster Size Matters: Analyze how GPU cluster sizes can impact throughput and project cost.

To add custom metrics, choose Explore Results. Use these metrics to evaluate your LLM’s performance during training:
3.1.1. AI Training Metrics#
Metric |
Configuration Example |
Optimization Guidance |
|---|---|---|
Model |
Maxtext_GPT3_175B |
Select a model architecture and size to balance training time, accuracy, and resource usage. Use pipeline parallel optimization for large models. |
Evaluate |
By CSP/System Config |
Select the performance indicator to measure training efficiency. |
Number of GPUs |
256 |
Scale GPU count based on budget, deadlines, and performance goals. |
Cloud Service Provider / System Config |
Native GCP, Google TPU v5p |
Optimize infrastructure by evaluating network latency, resource availability, and compatibility. |
Framework Version |
24.08.01 |
Select a software version to ensure compatibility and reproducibility. Validate framework-specific optimizations. |
Precision |
BF16 |
Specify data precision to balance accuracy, training speed, and memory usage. Weigh performance gains against detail loss. |
KPI Number of Tokens to Train (Trillion) |
15 |
Scale token count based on model capacity and convergence behavior while avoiding overfitting. |
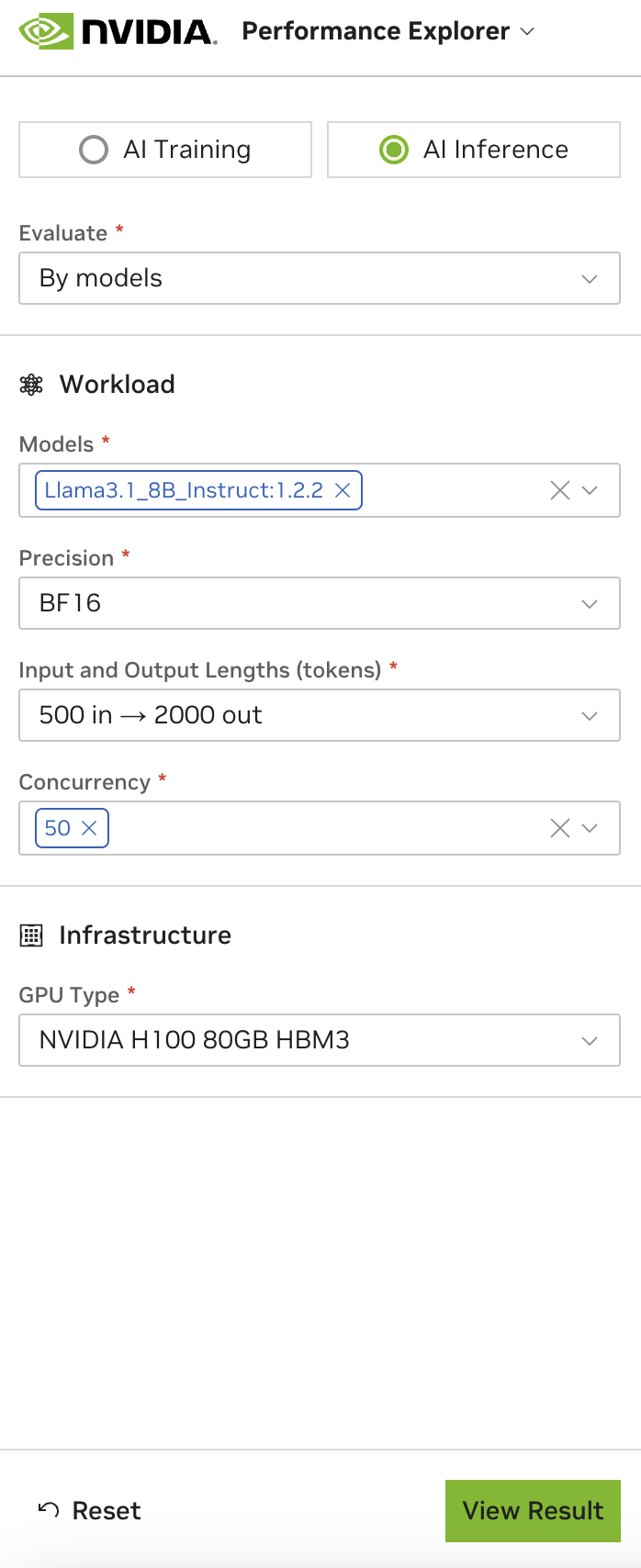
3.2. AI Inference#
The AI Inference tab provides four configuration guidance cards. Each card describes a unique use case or application:
Text Summarization: Generate concise summaries from lengthy documents.
Data Generation: Create synthetic data (structured or unstructured) using prompts.
Chat/QA: Deploy chatbots or QA systems to process user queries.
Translation: Translate text from one language to another.

To add custom metrics, choose Explore Results. Use these metrics to evaluate your LLM’s performance during inference when your trained model makes predictions on new data:
3.2.1. AI Inference Metrics#
Metric |
Configuration Example |
Optimization Guidance |
|---|---|---|
Evaluate |
By models |
Select a key performance indicator to identify inference efficiency. Prioritize based on your requirements for speed, response time, and prediction quality. |
Model |
Llama 3.1_8B_Instruct:1.2.2 |
Choose a model to evaluate inference performance. Verify model versions align with your accuracy, speed, and resource constraints. |
Precision |
BF16 |
Specify data precision for calculations during inference. Use FP8/BF16 to accelerate inference. Balance speed gains against potential accuracy tradeoffs. |
Input and Output Lengths (tokens) |
512 in → 2000 out |
Configure sequence lengths based on your task requirements. Longer sequences improve context but require more memory. |
Concurrency |
50 |
Adjust based on hardware capacity and response time requirements. |
GPU Type |
NVIDIA H100 80GB HBM3 |
Choose the GPU type to specify your hardware accelerator. Use H100/Tensor Core GPUs for large workloads and monitor cloud costs. |
3.3. View Results#
After selecting metrics, choose View Result to analyze your benchmarking outcomes.
3.3.1. Explore Benchmarking Results#
Analyze training results using “Total Cost to Train” and “Total Time to Train” metrics. These appear as bar charts to help you quickly identify trends and cost/time tradeoffs.
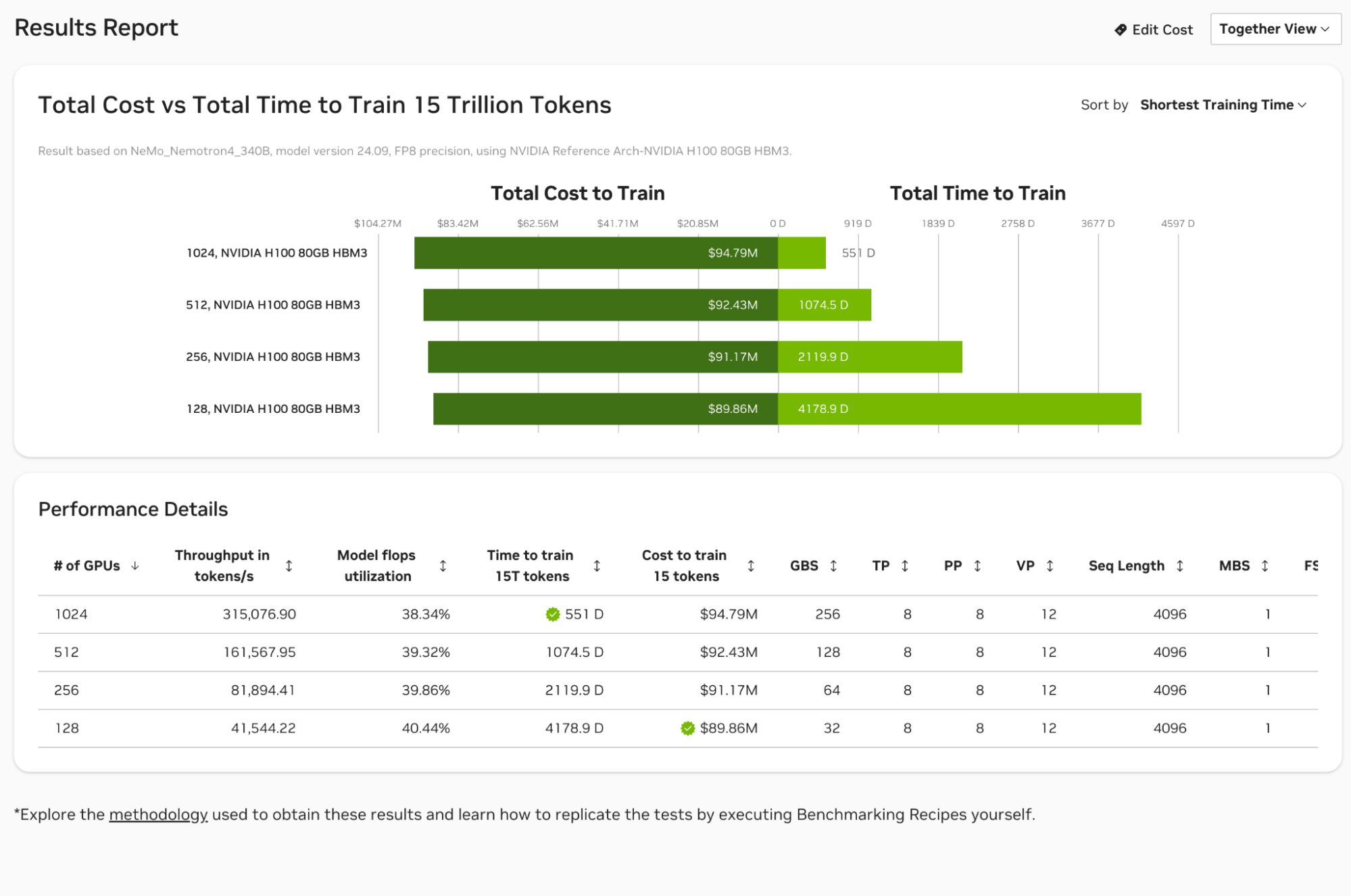
Total costs use chip and platform list prices. To adjust pricing directly in the graphs and refine analysis with custom comparisons, choose Edit Cost above the chart or click inside the chart area to bring up the Edit Cost Dialog.
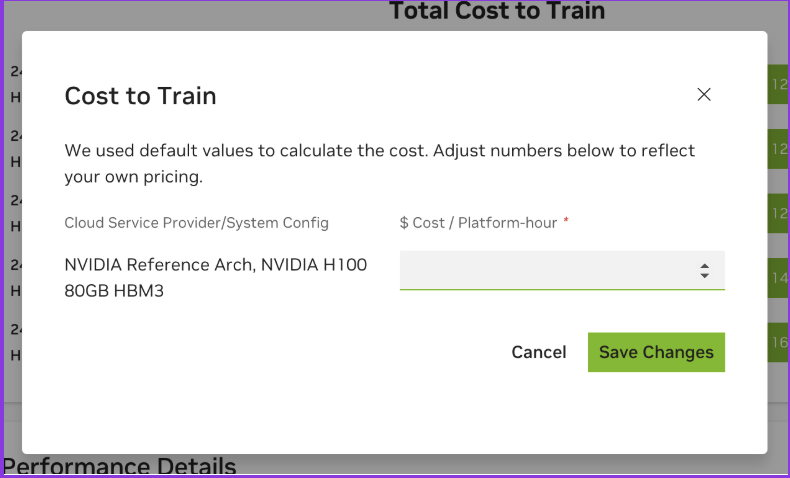
You can evaluate inference performance across different configuration setups. Adjust parameters in real-time to test scenarios and optimize results.
For support resources, go to the Get Help tab.