NanoGPT Training
This is a step-by-step guide on training a NanoGPT model with distributed training on Lepton.
Create Training Job
Navigate to the create job page, you can see the job configuration form.
- Job name: We can set it to
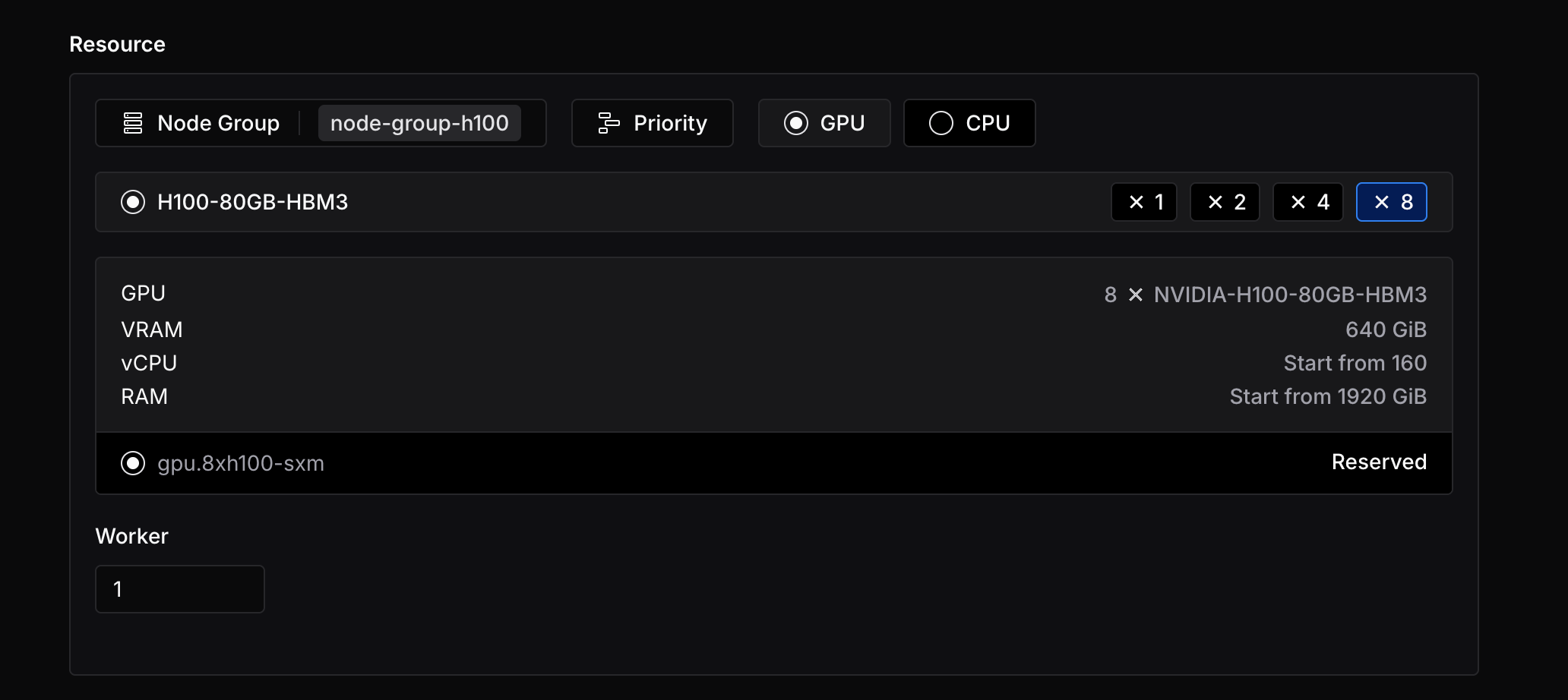
nanogpt-training. - Resource: We need to use H100 GPUs, select H100 x8 and set worker count to 1. You can use multiple workers to speed up the training process.
- Image: Choose the custom image, and fill in image
nvcr.io/nvidia/pytorch:24.11-py3 - Run command: Copy the following codes to the run command field.
# Download the environment setup script from Lepton's GitHub repository, make it executable, and source it to initialize the environment variables.
wget -O init.sh https://raw.githubusercontent.com/leptonai/scripts/main/lepton_env_to_pytorch.sh
chmod +x init.sh
source init.sh
export NCCL_DEBUG=INFO
# Print the environment variables and list the files in the root directory to verify the setup.
env | grep RANK
pip install torch numpy transformers datasets tiktoken wandb tqdm
# Clone the NanoGPT repository
cd /workspace
git clone https://github.com/karpathy/nanoGPT.git
cd nanoGPT
# prepare train data
python data/shakespeare_char/prepare.py
ngpus=$(nvidia-smi -L | wc -l)
if [ ngpus != 8 ]; then
unset NCCL_SOCKET_IFNAME
fi
accum_steps=$((ngpus*WORLD_SIZE*4))
sed -i "s/gradient_accumulation_steps = 1/gradient_accumulation_steps = ${accum_steps}/g" config/train_shakespeare_char.py
torchrun \
--master_addr ${MASTER_ADDR} \
--nnodes ${WORLD_SIZE} \
--node_rank ${NODE_RANK} \
--nproc_per_node ${ngpus} \
train.py config/train_shakespeare_char.py
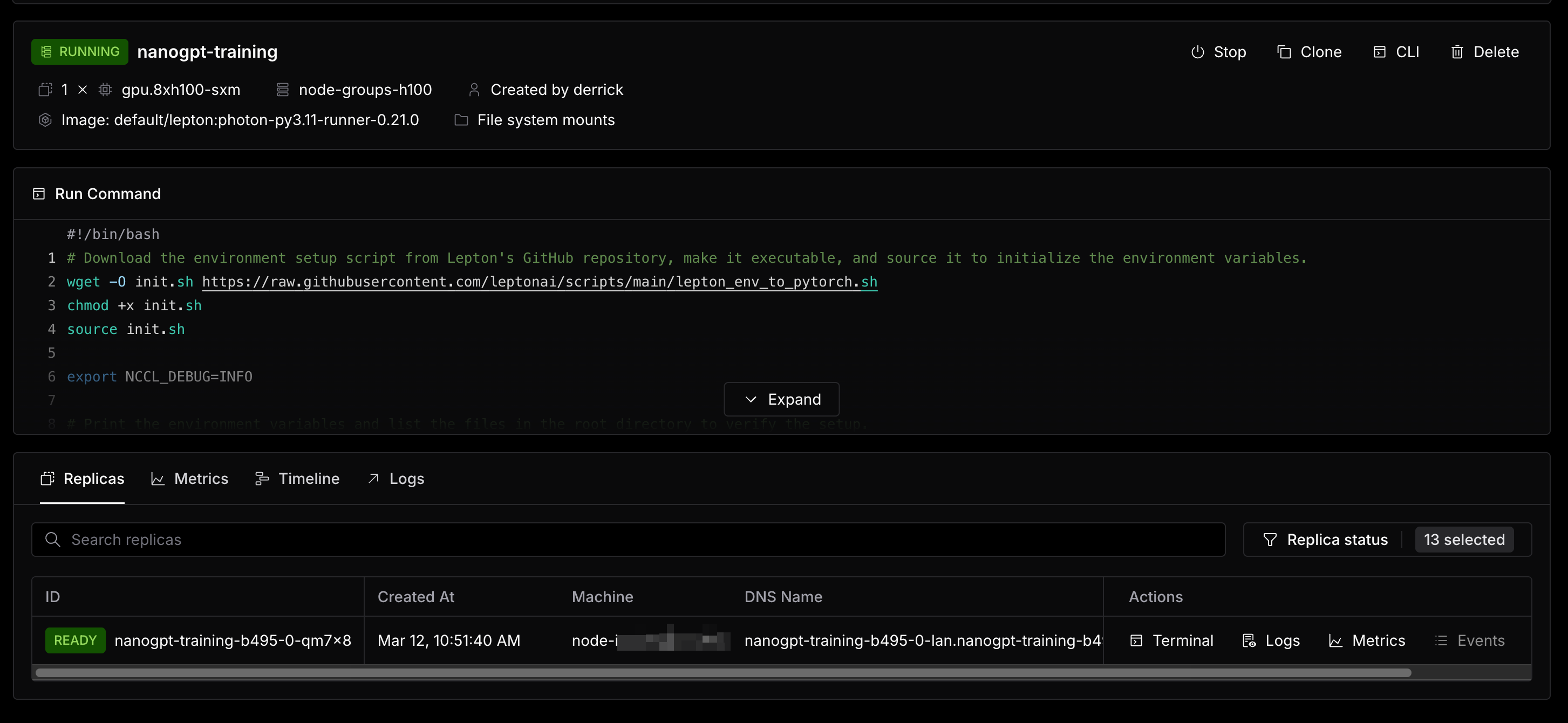
After the configuration is done, click on Create to submit the job, and you can see the job status in the job detail page.
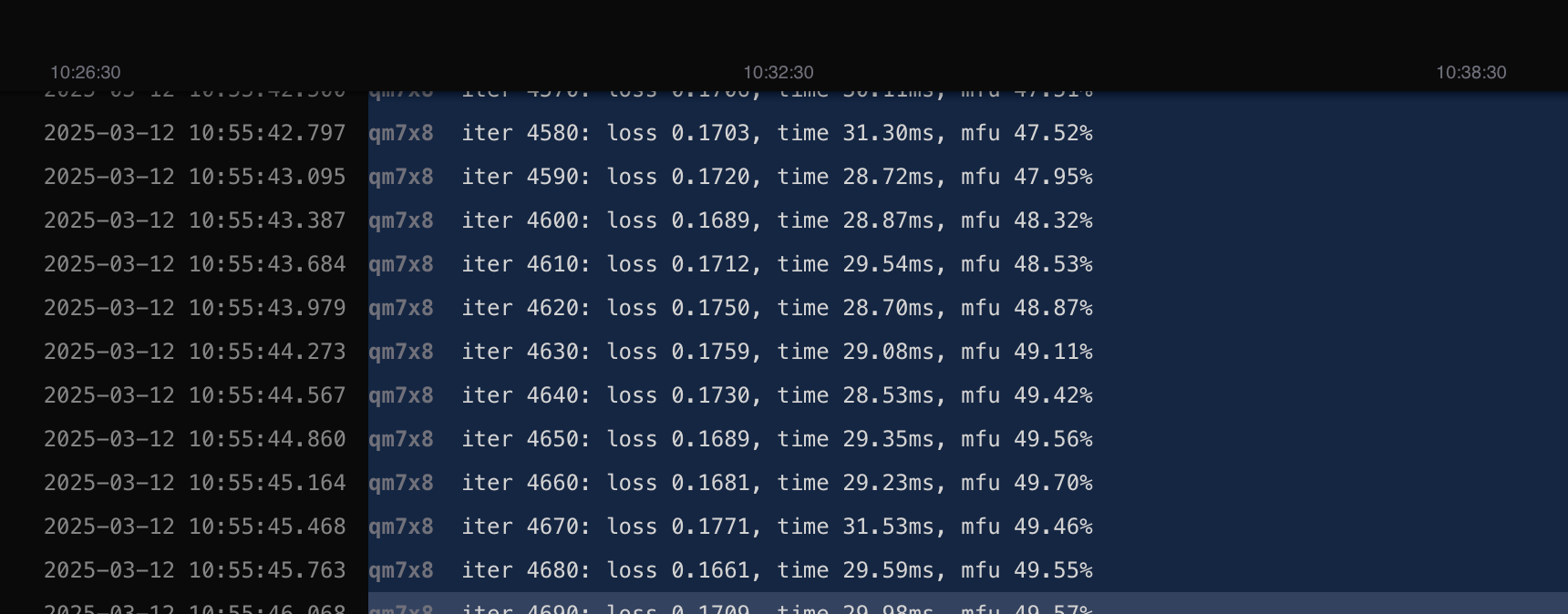
The duration of the training job depends on the number of parameters you set and the number of GPUs you use. When the job is running, you can check the real-time logs and metrics.