Creating a job
A job corresponds to a one-off task that runs to completion and then stops.
This page will go through the basics of creating a job in Lepton with the various configurable options available to you when creating a job: environment variables, secrets, file system mounts and more.
Create Job in Dashboard
Navigate to the create job page, you can see the create job page as following image.
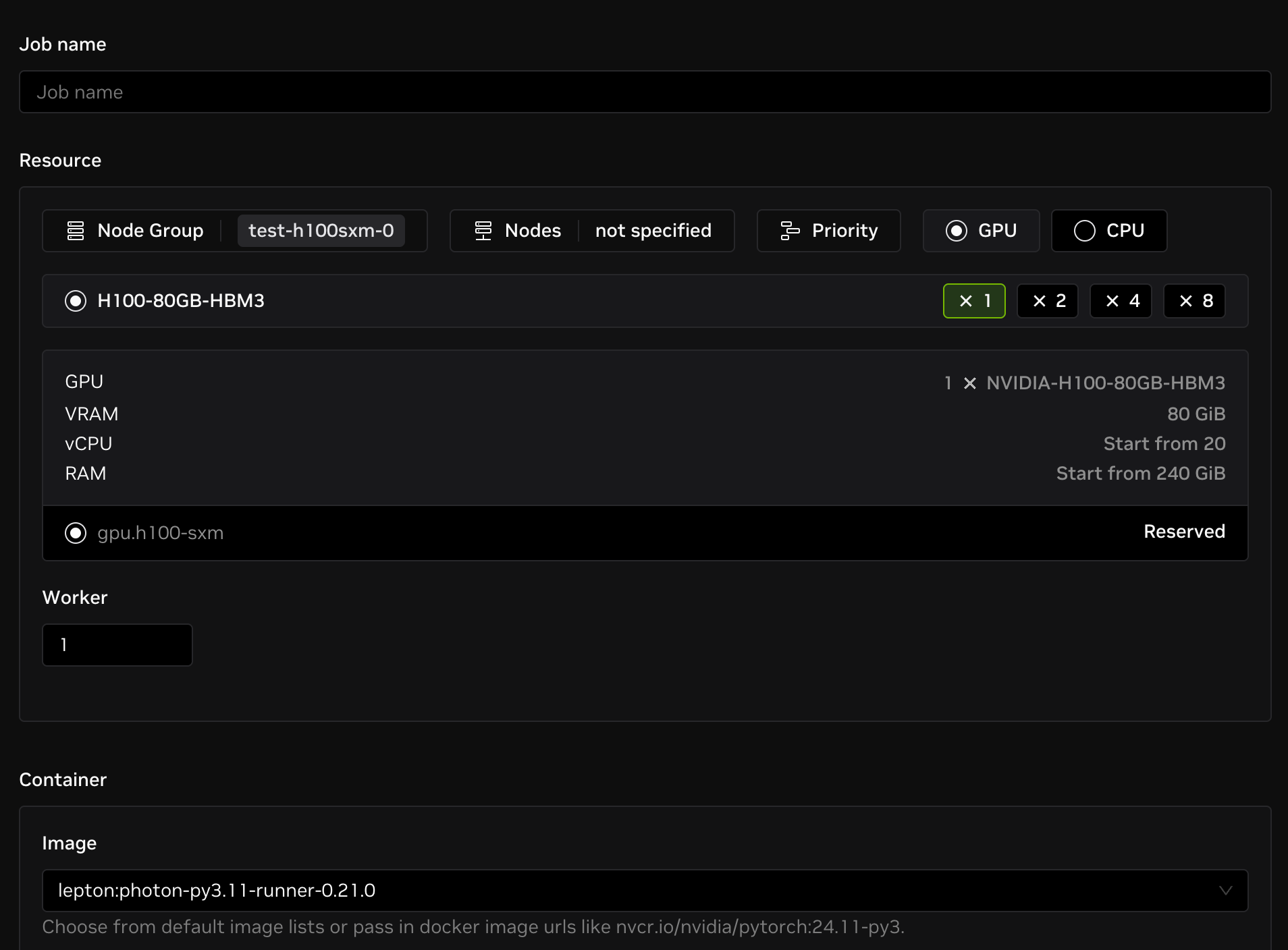
Configure Options
Resource
- Node group: The node group that the job will be launched on, default to the shared node group.
- Resource shape: The instance type that the job will be running on, select from a variety of CPU and GPU shapes.
- Number of workers: The number of workers that will be used for the job, default to 1.
Please reach out to your Technical Account Manager (TAM) if you need more resource shapes and node groups.
Container
- Image: The container image that will be used to create the job. You can choose from default image lists or use your own custom image.
- Private image registry auth (optional): If you are using a private image, you need to specify the image registry auth.
- Run Command: Command to run when the container starts.
- Container Ports: The ports that the container will listen on.
- Log Collection: Whether to collect the logs from the container, following the workspace level setting by default.
Advanced
- Environment Variables: Environment variables are key-value pairs that are passed to the job. They will be automatically set as environment variables in the job container, so the runtime can refer to them as needed.
Note
Your defined environment variables should not start with the name prefix
LEPTON_, as this prefix is reserved for predefined env variables. The following environment variables are predefined and will be available in the job:LEPTON_JOB_NAME: The name of the jobLEPTON_RESOURCE_ACCELERATOR_TYPE: The resource accelerator type of the job
- Shared Memory: The shared memory size is the size of the shared memory that will be allocated to the container.
- Max replica failure retry: Maximum number of times to retry a failed replica, zero by default.
- Max job failure retry: Maximum number of failure restarts of the entire job.
- Visibility: You can use this to specify the visibility of the job. If the visibility is set to private, only the creator can access the job. If the visibility is set to public, all the users in the workspace can access the job.
Environment Variables
There are several environment variables that are predefined and will be available in the job:
| Env Variable Name | Meaning | Sample Value |
|---|---|---|
| LEPTON_RESOURCE_ACCELERATOR_NUM | Number of hardware accelerators allocated | 1 |
| LEPTON_JOB_WORKER_HOSTNAME_PREFIX | Prefix used for naming worker hostnames | worker |
| LEPTON_WORKSPACE_ID | Identifier for the current workspace | prod01awsuswest2wssys |
| LEPTON_RESOURCE_ACCELERATOR_TYPE | Type of hardware accelerator used | NVIDIA-A100-80GB |
| LEPTON_WORKER_ID | Unique identifier for the current worker | env-job-98bw-0-2nm7s |
| LEPTON_JOB_FAILURE_COUNT | Number of failed job attempts | 0 |
| LEPTON_JOB_TOTAL_WORKERS | Total number of workers assigned to the job | 1 |
| LEPTON_JOB_WORKER_INDEX | Index of the current worker within the job | 0 |
| LEPTON_SUBDOMAIN | Subdomain name assigned to the job service | env-job-98bw-job-svc |
| LEPTON_JOB_SERVICE_PREFIX | Prefix used for naming services related to the job | env-job-98bw |
| LEPTON_JOB_NAME | Name assigned to the job | env-job-98bw |
| LEPTON_VIRTUAL_ENV | Path to the Python virtual environment | /opt/lepton/venv |
By leveraging the environment variables, you can customize your job to meet your specific needs. Here are some commonly used environment variables when launching a job via torch.distributed.launch:
#! /usr/bin/env bash
# Setup the service prefix and subdomain
SERVICE_PREFIX="${LEPTON_JOB_SERVICE_PREFIX:-$LEPTON_JOB_NAME}"
SUBDOMAIN="${LEPTON_SUBDOMAIN:-$LEPTON_JOB_NAME-job-svc}"
# Setup the master address, port, world size and node rank
export MASTER_ADDR=${SERVICE_PREFIX}-0.${SUBDOMAIN}.ws-${LEPTON_WORKSPACE_ID}.svc.cluster.local
export MASTER_PORT=29400
export WORLD_SIZE=${LEPTON_JOB_TOTAL_WORKERS}
export WORKER_ADDRS=$(seq 1 $((LEPTON_JOB_TOTAL_WORKERS - 1)) | xargs -I {} echo ${SERVICE_PREFIX}-{}.${SUBDOMAIN}.ws-${LEPTON_WORKSPACE_ID}.svc.cluster.local | paste -sd ',' -)
export NODE_RANK=${LEPTON_JOB_WORKER_INDEX}
# Run the distributed training script.
python -m torch.distributed.run \
--nnodes=$WORLD_SIZE \
--nproc_per_node=$LEPTON_RESOURCE_ACCELERATOR_NUM \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
/path/to/train.py
Examples
For job creation, job failure diagnosis and so on, you can refer to the following examples:
Distributed training with PyTorch