Running the Semantic Deduplication Pipeline#
Semantic Deduplication is a process used to identify highly similar video clips based on their content or meaning, rather than just file names or metadata. This involves a two step process:
Cluster similar embeddings together into n clusters.
Within each cluster, find the most similar clips and drop the one which has a similarity greater than some threshold
You can run the semantic deduplication pipeline either by passing S3 input/output
paths or by directly uploading a .zip file containing the proper parquet file.
The Semantic Deduplication pipeline produces the following artifacts:
├── clustering_results/
│ ├── kmeans_centroids.npy # Embedding vectors for each K-Means Centroids
│ ├── embs_by_nearest_center/ # All clip embeddings grouped by their nearest centroid
│ ├── nearest_cent={centroid-index}
│ ├── {sha}.parquet # Embeddings that are close to {index}-th centroid
├── extraction/
│ ├── dedup_summary_{eps-threshold}.csv # Deduplication summary for a given Epsilon threshold
│ ├── semdedup_pruning_tables/
│ ├── cluster_{centroid-index}.parquet # Semantic matches for a single cluster with cosine_sim_score for each clip
│ ├── unique_ids_{eps-threshold}.parquet/
│ ├── part.{centroid-index}.parquet # Similar clips that are within a given Epsilon threshold
Deduplication Pipeline Configuration Options#
Below are the key options for the deduplication pipeline:
--input-embeddings-path: The path to input embeddings, typically ending withiv2_embd_parquetorce1_embd_parquet, depending on which embedding model is used in thesplit-annotatepipeline. Note that this option only applies to S3-based Semantic Deduplication invocations.--output-path: The output location. Note that this option only applies to S3-based Semantic Deduplication invocations.--n-clusters: The number of clusters for K-Means clustering--max-iter: The maximum iterations for clustering. The default value is100.--eps-to-extract: The epsilon value to extract deduplicated records. The default value is0.01.--sim-metric: The metric to use for ordering within a cluster with respect to the centroid. Accepted values includecosineandl2. The default value iscosine.
Running Semantic Deduplication Pipeline Using S3 Input/Output#
The following are step-by-step instructions for running the semantic deduplication pipeline using S3 input/output.
Note
These instructions assume that you have already run the split curation pipeline to generate video embeddings.
You must enter three required arguments as part of the invocation of the pipeline; there are additional optional arguments as well. Below are the details for the required, threshold, and optional arguments.
Required Arguments#
input-embeddings-path: The path to the embeddings. This can be either an S3 or local path.output-path: The path to the output. See the following section for more information about the directory structure.num_clusters: The number of K-Means clusters
Threshold Arguments#
The following argument is only required if you want to use pre-determined thresholds.
eps_to_extract: Extracts only clips that are within this threshold. This will create theextraction/unique_ids_{this_value}.parquetoutput file.
Optional Arguments#
max-iter: The number of iterations to run KMeans onrandom-state: The random state for KMeanswhich-to-keep: The method to use for selecting the most similar clip within a cluster. Accepted values includehard,easy, andrandom.
Invoking Semantic Deduplication Pipeline#
When invoking the semantic deduplication pipeline, a user must provide the following information:
AWS Credentials
Pipeline Arguments
Below are the parameter details for the AWS credentials and pipeline arguments.
AWS Credential Parameters#
[default]
aws_access_key_id=<YOUR_ACCESS_KEY_ID>
aws_secret_access_key=<YOUR_SECRET_ACCESS_KEY>
region=<REGION_OF_YOUR_S3_BUCKET (e.g. us-west-2)>
aws_session_token=<YOUR_SESSION_TOKEN (**this field only applies if you are using temporary credentials**)>
Note
We do not recommend using temporary credentials for this pipeline, as temporary credentials are short-lived and may expire before the pipeline completes.
Pipeline Argument Parameters#
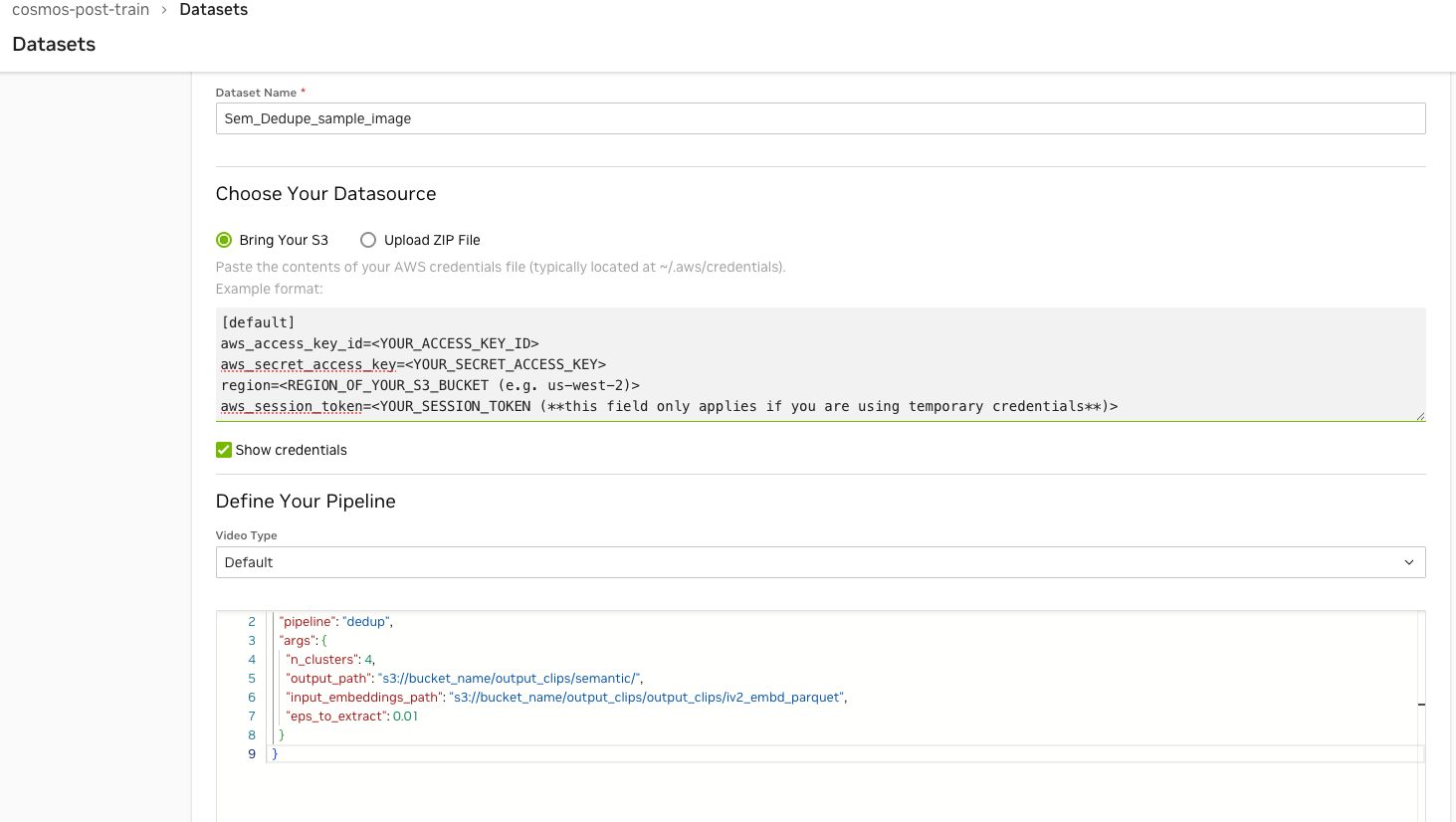
{
"pipeline": "dedup",
"args": {
"n_clusters": 4,
"output_path": "s3://bucket_name/output_clips/semantic/",
"input_embeddings_path": "s3://bucket_name/output_clips/output_clips/iv2_embd_parquet",
"eps_to_extract": 0.01
}
}
The following is an example of the UI entry for the semantic deduplication pipeline.
Running Semantic Deduplication Pipeline Using ZIP Upload#
You can also invoke the semantic deduplication pipeline by uploading a .zip file containing
the proper parquet file. Below are the steps to do so:
Run the split curation pipeline to generate video embeddings.
Download the output
.zipfile by clicking Download Clips and Captions.In the
.zipfile, copy theiv2_embd_parquet/folder out. Then, compress the contents as a.zipfile (e.g.iv2_embd_parquet.zip).The folder to be copied out may also be
ce1_embd_parquet/if you choose to use thecosmos-embed1embedding algorithm.
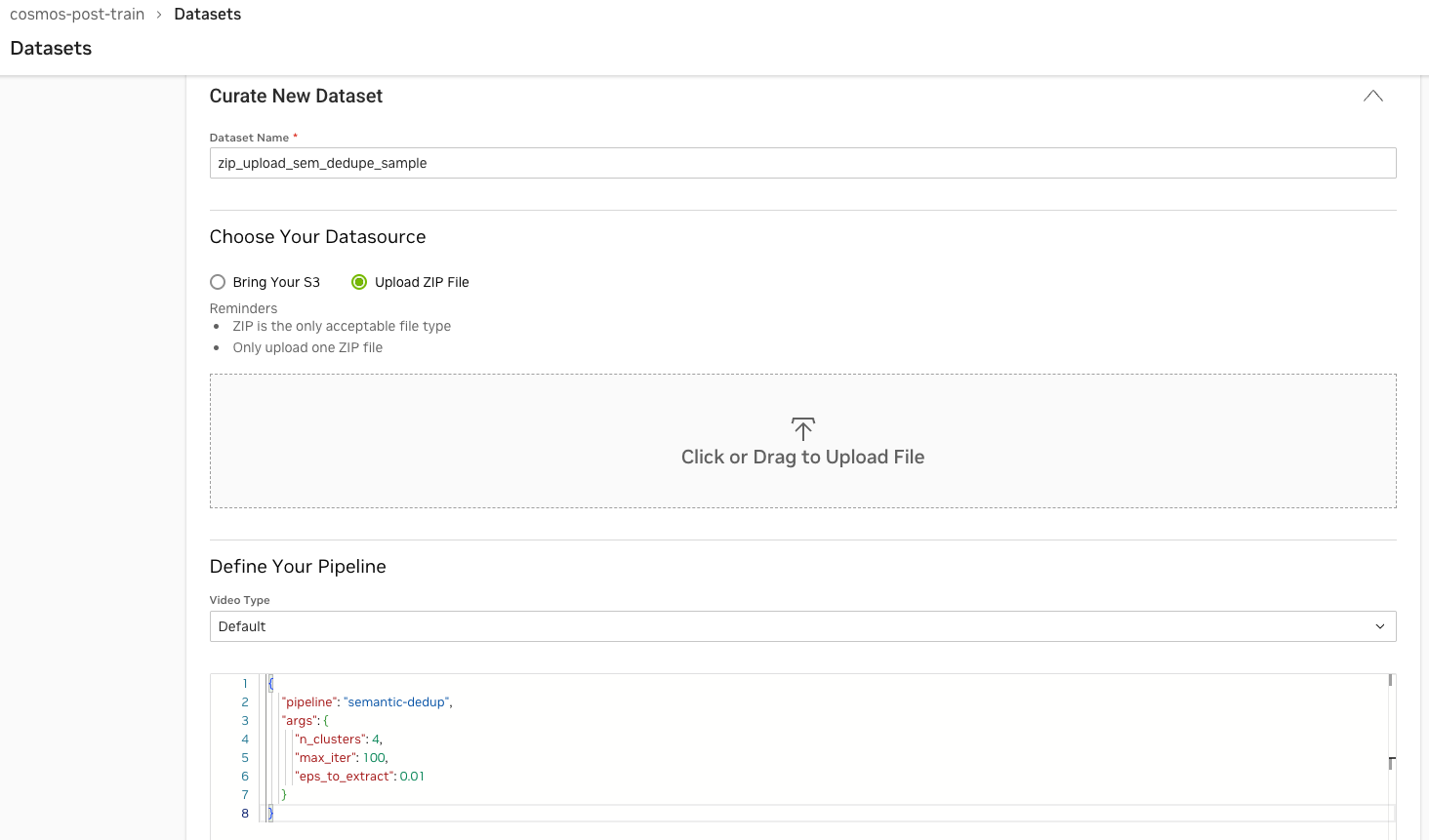
Start a new pipeline run with the above parquet
.zipfile. Use the following job spec within the JSON editor of the UI:{ "pipeline": "semantic-dedup", "args": { "n_clusters": 4, "max_iter": 100, "eps_to_extract": 0.01 } }
After the curation job is complete, download the results by clicking Download Clips and Captions.
The following is an example of the UI entry for the semantic deduplication pipeline.
Semantic Deduplication Pipeline Output#
For a full description of the pipeline output, refer to the cosmos-curate OSS library documentation.