Components#
This section describes the hardware components of the Enterprise RA.
NVIDIA HGX B300 Baseboard#
The HGX B300 baseboard (Figure 1) is an AI powerhouse that enables enterprises to expand the frontiers of business innovation and optimization. HGX B300 is a unified platform consisting of 8 Blackwell GPUs internally connected by NVLink and externally connected by a network interface of 800 Gb/s (2 x 400Gb/s Ethernet) per GPU. This connectivity is provided by 8x ConnectX-8 SuperNICs on the HGX baseboard for the East/West (East/West) networking.

Figure 1 Figure 1: HGX B300 Baseboard.#
Table 1: HGX H200, B200 and B300 GPU and per Node & Memory specifications.
Specification |
NVIDIA H200 SXM |
NVIDIA B200 SXM |
NVIDIA B300 SXM |
|---|---|---|---|
Memory per GPU |
141GB HBM3e |
180GB HBM3e |
288GB HBM3e |
Memory per Node |
1.1TB HBM3e |
1.44TB HBM3e |
2.30TB HBM3e |
GPU Bandwidth |
4.80TB/s |
Up to 8TB/s |
Up to 8TB/s |
GPU Aggregate Bandwidth per Node |
38.4TB/s |
Up to 64TB/s |
Up to 64 TB/s |
The HGX B300 baseboard provides up to 144 petaflops of processing power, making it a leading accelerated platform for AI. It offers advanced networking up to 800 Gbps with ConnectX-8 SuperNICs, enabling AI cloud networking, composable storage, zero-trust security, and GPU compute elasticity for AI workloads.
NVIDIA HGX B300 Systems#
NVIDIA-Certified HGX B300 systems are based on a common system design with flexibility for optimizing the configuration to match the cluster requirements. An example of this design is shown in Figure 2.
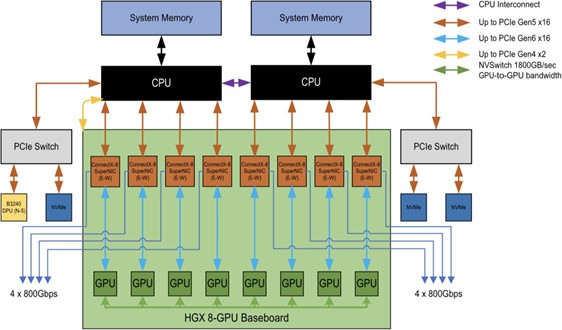
Figure 2 Figure 2: HGX B300 System.#
Elements for an NVIDIA-Certified HGX B300 system are listed in Table 2
Table 2. NVIDIA HGX B300 system elements.
Parameter |
Requirement |
|---|---|
Target workloads |
Large Language Model; Traditional DL Inference Models, HPC |
GPU configuration |
Eight NVIDIA B300 GPUs on an HGX B300 baseboard with up to 2304 GB of GPU memory |
NVIDIA® NVLink™ and NVSwitch™ |
NVIDIA HGX B300 Baseboards use a combination of fifth-generation NVSwitch and fifth-generation NVLink |
CPU |
Total Aggregate Bandwidth 14.4TB/s |
CPU sockets |
GPU-to-GPU Bandwidth 1800GB/s |
CPU speed |
2.0 GHz minimum base CPU clock |
CPU cores |
Minimum of 48 physical CPU cores per socket. Recommendation of 56 physical CPU cores per socket. |
System memory (total across all CPU sockets) |
Minimum of 2TB system memory. Minimum of 500GB/s memory bandwidth. For optimal performance, system memory should be evenly distributed across all CPU sockets and memory channels and should be fully populated and symmetrically placed on all CPU memory controller (MC) channels. |
DPU (North/South) |
One NVIDIA® BlueField®-3 DPU per server |
PCI Express |
Eight Gen5 x16 links and one Gen4 x2 link per NVIDIA HGX B300 baseboard. One Gen5 x16 link per DPU, SuperNIC or adapter. |
PCIe topology |
Balanced PCIe topology with connectivity spread evenly across CPU sockets and PCIe root ports. |
Network Adapters/NICs speed (East/West) |
Eight NVIDIA® ConnectX-8 SuperNICs per NVIDIA HGX B300 baseboard. Up to 800 Gbps per adapter. |
Local storage |
Local storage recommendations are as follows: |
Remote systems management |
SMBPBI over SMBus (OOB) protocol to BMC. PLDM T5-enabled. SPDM-enabled. |
Security |
TPM 2.0 module (secure boot) |
Control Plane/Management Nodes#
The cluster design specified in this Enterprise RA can support up to eight control plane nodes. In addition to the standard compute nodes, control plane nodes are needed to run the software that manages the cluster and provides access for users. The specific components depend on the management software. Table 3 shows an example configuration for these nodes.
For example, a configuration using NVIDIA Base Command Manager, Slurm, and Kubernetes together can include seven control plane nodes in total: two for Base Command Manager (with high availability configured), two for Slurm head nodes, and three for Kubernetes control plane nodes. This uses seven of the eight available control plane nodes possible.
Table 3. Control plane node components
Component |
Quantity |
Description |
|---|---|---|
CPU |
2 |
32C Intel Xeon Gold 6448Y or equivalent / 32C AMD EPYC 9354 |
North/South (DPU) |
1 |
NVIDIA BlueField-3 B3220 DPU with two 200G ports and 1Gb RJ45 management port. Other variants can be supported as per Compute Node alternatives - Table 4 |
System Memory |
– |
Minimum of 256 GB DDR5 |
Boot Drive |
1 |
1 TB NVMe SSD |
Local storage |
1 |
4 TB NVMe SSD. More may be required if image storage is required |
BMC |
1 |
1 Gb RJ45 management port |
In cases where the existing control plane nodes are missing, the Enterprise RA recommends deploying one set per cluster. Configure these nodes for high availability to keep your cluster running smoothly.
Networking#
The NVIDIA HGX platform networking configuration enables the highest Al performance and scale, while ensuring cloud manageability and security. It leverages the NVIDIA expertise in Al cloud data centers and optimizes network traffic flow:
East/West (Compute Network) traffic: This refers to traffic between NVIDIA HGX systems within the cluster, typically for multi-node Al training, AI fine tuning, HPC collective operations, and other workloads.
North/South (Customer and Storage Network) traffic: This involves traffic between NVIDIA HGX systems and any external resources including cloud management and orchestration systems, remote data storage nodes, and other parts of the data center or the Internet.
When combined with NVIDIA Spectrum-X Ethernet, the NVIDIA HGX B300 platform delivers strong performance for deep learning training and inference, data science, scientific simulation, and other modern workloads. The following sections describe recommended NVIDIA HGX B300 platform configurations along with their associated NVIDIA networking platforms.
Compute (Node East/West) Ethernet Networking#
On the NVIDIA HGX B300 baseboard, NVIDIA ConnectX-8 SuperNIC offers up to 800 Gb/s, low-latency network connectivity between GPUs in the Al cluster, featuring RDMA and RoCE acceleration, with NVIDIA® GPUDirect® and GPUDirect Storage technologies. For data centers that deploy Ethernet, NVIDIA ConnectX-8 offers a range of advancements including RoCE optimizations and multi-tenancy, which are key in Al cloud environments. Additionally, NVIDIA ConnectX-8 offers advanced hardware offloads for overlay networks such as VXLAN and NVGRE, which help reduce CPU load and improve network efficiency.
Beyond raw speed, NVIDIA ConnectX-8 enhances network performance with features like advanced congestion control, telemetry-based routing, and quality of service (QoS) capabilities to meet diverse AI application and training requirements. Security is built in with hardware acceleration for cryptographic protocols like IPSec and MACSec, taking these tasks over from the CPU to maintain performance.
Multi-node deployments with an NVIDIA HGX B300 platform should adhere to the following total compute network bandwidth per GPU recommendations.
The NVIDIA ConnectX-8 SuperNIC is integrated onto the NVIDIA HGX B300 baseboard, maintaining a 1:1 GPU-to-NIC ratio to ensure optimal bandwidth and direct connectivity for each GPU.
Total Minimum Compute Network Bandwidth
400 GB/s (8x 400 Gb/s Ethernet NICs)
Total Recommended Compute Network Bandwidth
800 GB/s (16x 400 Gb/s Ethernet NICs using breakout)
Converged (Node North/South) Ethernet Networking#
This section describes the NVIDIA BlueField-3 role for the North South (North/South) Ethernet network in the NVIDIA HGX platform and the recommended NVIDIA BlueField-3 models for this infrastructure.
The NVIDIA BlueField-3 data processing unit (DPU) is a 400 Gb/s infrastructure compute platform that enables organizations to securely deploy and operate NVIDIA HGX AI data centers at massive scales. NVIDIA BlueField-3 DPU is optimized for the North/South network and the NVIDIA BlueField-3 IC is optimized for the East/West, Al compute fabric.
NVIDIA BlueField-3 offers several essential capabilities and benefits within the NVIDIA HGX platform:
Workload Orchestration: NVIDIA BlueField-3 serves as an optimized compute platform for the data center control-plane, enabling automated provisioning and elasticity. This empowers NVIDIA HGX AI cloud platforms to scale resources dynamically based on fluctuating demand, ensuring efficient allocation of computing resources for transient Al workloads.
Storage Acceleration: NVIDIA BlueField-3 provides advanced storage acceleration features that optimize data storage access. Its innovative NVIDIA BlueField SNAP technology enables remote storage devices to function as local, improving Al performance and streamlining cloud operations.
Secure Infrastructure: NVIDIA BlueField-3 operates in a highly secure zero-trust mode and functions independently from the host, significantly enhancing the security of the NVIDIA HGX platform. In addition, NVIDIA BlueField-3 enables a wide range of accelerated security services, including next-generation firewall and micro-segmentation, bolstering the overall security posture of the infrastructure.
The NVIDIA BlueField‑3 DPU integration enhances NVIDIA HGX platforms by improving resource management, performance, security, and scalability, making them well‑suited for AI workloads in datacenter environments.
NVIDIA BlueField‑3 DPUs support multiple operating modes, including Embedded Function (ECPF) or DPU mode, which is commonly used as a default. In this mode, the Arm subsystem on the DPU owns and manages NIC resources, and network traffic typically passes through a virtual switch on the DPU before reaching the host, adding an extra layer of control.
To support secure management of NVIDIA HGX platforms, many NVIDIA BlueField products integrate an onboard Baseboard Management Controller (BMC). This BMC enables provisioning and management of both the NVIDIA BlueField DPU and the HGX platform using standard tools such as Redfish APIs, relies on an external root‑of‑trust for firmware protection, and connects to the management network through a dedicated 1GbE out‑of‑band port.
When planning NVIDIA HGX deployments with NVIDIA BlueField‑3, it is important to account for card form factor and power requirements. Some BlueField‑3 configurations for north‑south connectivity can draw more than 75 W and therefore require both standard PCIe slot power and an additional PCIe power connector rated for at least 75 W.
For NVIDIA BlueField3 DPUs used in the North/South network for NVIDIA HGX 8GPU platforms, the NVIDIA BlueField3 products listed in Table 4 are generally recommended as suitable options.
Table 4. HGX B300 recommended BF-3 DPUs for North/South Network
Product |
PCIe Card Form Factor |
Connector Required |
Applicable Topologies |
|---|---|---|---|
NVIDIA BlueField-3 B3240 P-Series FHHL DPU, 400GbE (default mode) /NDR IB, Dual-port QSFP112 |
Single-slot FHHL PCIe Gen5 x16 with x16 PCIe extension option |
8-pin ATX 12V PCIe 1G/USB Management Interfaces QSFP112 connector cages |
Cold-aisle slots/servers only |
NVIDIA BlueField-3 B3240 P-Series FHHL DPU, 400GbE (default mode) /NDR IB, Dual-port QSFP112 |
Dual-slot FHHL PCIe Gen5 x16 with x16 PCIe extension option |
8-pin ATX 12V PCIe 1G/USB Management Interfaces QSFP112 connector cages |
All |
NVIDIA BlueField-3 B3220 P-series FHHL DPU, 200GbE (default mode) /NDR200 IB, Dual-port QSFP112 |
Single-slot FHHL PCIe Gen5 x16 with x16 PCIe extension option |
8-pin ATX 12V PCIe 1G/USB Management Interfaces QSFP112 connector cages |
All |
Note
NVIDIA recommends using the NVIDIA BlueField-3 B3240 DPU with NVIDIA HGX B300 platforms rather than the NVIDIA BlueField-3 B3220 that is common in NVIDIA HGX H100/200 and HGX B200 systems with 2x 200GbE uplinks. For HGX B300 deployments, it can be helpful to consider future workloads such as distributed inference that may use KV cache offloads to highspeed, network attached storage. In these cases, having higher burst I/O capacity per GPU can be advantageous, even if the average bandwidth needs for typical training workloads are not very high.