The most common initial performance issues in 3D applications tend to involve causing the driver to do needless work, or doing work in the app on the CPU that could be done more efficiently on the GPU.
Avoid redundant state changes to the driver (e.g. glEnable/glDisable). There are several common cases:
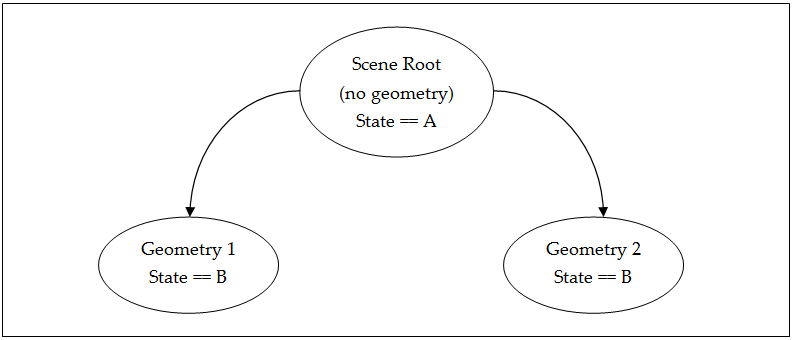
Do not "push" and "pop" render state. In other words, during a scene graph traversal, every render state change should be directly related to a draw call. Often, push/pop-style behavior can lead to cases such as the following (see the simple scene graph above):
In this case, both objects were drawn with the driver having to at least process the changed state in order to determine that it hadn’t actually changed (it was B in both draw calls). Associate state with drawable objects and set accordingly.
Do not send every render state to the driver on every draw call and assume the driver will test for unchanged values. Use high-level app knowledge to send only state that has changed, since this can often be done with far fewer comparisons at a higher level.
Know which states are particularly expensive, and do not change them very frequently. Particularly expensive states include:
glUseProgram: Changing shader programs can be very expensive, as the shader program is responsible (according to the GLES spec) for storing and restoring the state of all of its uniforms (or shader constants). The more uniforms in the shader, the more expensive swapping will be. Avoid dynamically re-linking shader programs, as compiling and linking shaders are heavyweight operations.Where possible, accumulate the scene’s drawable objects into sets, grouped by expensive states like shader program, and then render all objects with those same states together, changing state only at the start of each different set, not each object. This form of state gathering can also be useful for analysis.
Avoid the following functions on a per-frame basis, as they use memory bandwidth and can stall the rendering pipeline, minimizing GPU/CPU parallelism:
glReadPixels gl*Tex*Image* Processing vertices on the CPU is sub-optimal for several reasons:
Therefore, it is best to rework CPU-based vertex transforms and deformations into vertex shaders. This can allow for a range of optimizations, since vertex shaders on Tegra can utilize a wide range of data types directly (i.e., float, half-float, byte, short, etc). This can allow for smaller vertex data than would have to be kept around for CPU-based vertex processing.
Try to deliver as much geometry as possible with each submitted drawcall. Drawing tens (or even hundreds) of triangles per drawcall results in low GPU utilization and poor overall performance. Consider batching (in your tool-chain, preferably) each scene (or sub-scene) by material to increase the payload of each drawcall. Doing this will ensure maximum "bang for your buck" for every drawcall, and keep the GPU operating as close to peak efficiency as possible.

NVIDIA® GameWorks™ Documentation Rev. 1.0.220830 ©2014-2022. NVIDIA Corporation and affiliates. All Rights Reserved.