# Forecasting with HEAVY.AI and Prophet
See the Prophet [project documentation](http://facebook.github.io/prophet/) to learn more and [stay up to date](https://altair-viz.github.io/releases/changes.html).
[Prophet](https://facebook.github.io/prophet/) is an open-source library from Facebook that provides basic forecasting capabilities for time series data. HEAVY.AI includes Prophet in its data science foundation. With the Ibis backend for HEAVY.AI, you can create time series inputs into Prophet for quick forecasts. Combined with distributed execution frameworks like Dask or Ray, forecasts can be generated in parallel for multiple time series. In addition, you can use Altair to visualize forecast results and load forecast outputs back to HEAVY.AI so they can be used in Heavy Immerse.
The following example shows how to generate a simple Prophet forecast using Ibis to extract data from HEAVY.AI, use Altair to visualize the forecast results, and then use Ray to create forecasts in parallel for multiple time series.
## Using Ibis with Prophet
Let's use the flights dataset to create a forecast. The example uses HEAVY.AI server, but you can use any dataset that has date or timestamp as a key attribute. Connect via Ibis.
```python
conn = ibis.heavyai.connect(
host='metis.mapd.com', user='admin', password='HyperInteractive',
port=443, database='heavyai', protocol= 'https'
)
t = conn.table('flights_donotmodify')
```
First, predict daily arrival delays for a single airport, given the annual history of arrival delays for that airport. To do this, create an Ibis expression that shapes data into the format expected by Prophet.
For simplicity, Prophet always expects a time series to be a two-column dataset of the form `date, value.`With Ibis, you can specify an expression to alias column names as well as perform additional transformations to date/time fields.
Now, create a Python function to extract time series data for a specific airport. This uses Ibis, but returns an expression that evaluates to the average departure delay for a given city. (The columns are named `ds` and `y` as expected by Prophet.)
```python
def get_delay_ts(city: str):
ds=t.dep_timestamp.truncate('D').name('ds')
y = t.depdelay.mean().name('y')
filters = [t.dest_city == city,
ds.notnull()]
expr = t.filter(filters).group_by(ds).aggregate(y)
return expr
```
Try it to verify the output. You can customize the function to generate the time series granularity you want; for example, hourly delays instead of daily.
```python
print(get_delay_ts('New York').compile())
#this compiles to
SELECT DATE_TRUNC(DAY, "dep_timestamp") AS ds, avg("depdelay") AS y
FROM flights_2008_7M
WHERE ("dest_city" = 'New York') AND
(DATE_TRUNC(DAY, "dep_timestamp") IS NOT NULL) AND
("flight_year" >= 2008)
GROUP BY ds
```
Now, create a simple forecast. Feed the time series above directly to Prophet and have it generate a forecast. In this case, you set the appropriate parameters to consider seasonality at a yearly level.
```python
from fbprophet import Prophet
m = Prophet()
m.add_seasonality(name='yearly', period=365, fourier_order=20)
m.fit(get_delay_ts('Chicago').execute())
future = m.make_future_dataframe(periods=30)
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
```
This generates a pandas dataframe with a forward-looking forecast for a month, based on past data for the year 2008 for New York City.
| | | ds | yhat | yhat\_lower | yhat\_upper |
| - | - | -- | ---- | ----------- | ----------- |
| 391 | 2009-01-26 | 15.837485 | -1.127451 | 32.935337 |
| --- | ---------- | --------- | --------- | --------- |
| 392 | 2009-01-27 | 12.255507 | -4.316904 | 29.076066 |
| --- | ---------- | --------- | --------- | --------- |
| 393 | 2009-01-28 | 11.985047 | -3.894635 | 29.361144 |
| --- | ---------- | --------- | --------- | --------- |
| 394 | 2009-01-29 | 12.829259 | -3.570059 | 28.911738 |
| --- | ---------- | --------- | --------- | --------- |
| 395 | 2009-01-30 | 20.024641 | 4.543431 | 37.593828 |
| --- | ---------- | --------- | -------- | --------- |
Finally, to see show how Ibis can support multiple backends, including pandas as an ibis backend, build an Altair chart for the forecast output dataframe to see what the forecast looks like. Use Altair's [compound chart](https://altair-viz.github.io/user_guide/compound_charts.html) functionality to overlay the original Ibis expression for the past data, with the error bounds and the forecast trend line.
```python
connection = ibis.pandas.connect({'forecast': forecast })
table = connection.table('forecast')
line = alt.Chart(table).mark_line().encode(
x='ds:T',
y='yhat:Q'
)
band = alt.Chart(table).mark_errorband().encode(
x='ds:T',
y='yhat_lower:Q',
y2='yhat_upper:Q'
)
points = alt.Chart(get_delay_ts('New York')).mark_point(size=2, color='red').encode(
x='ds:T',
y='y:Q')
(band+line+points).properties(width=1000, height=400)
```
The generated chart shows the past data and extends out by a month to show predicted arrival delay.
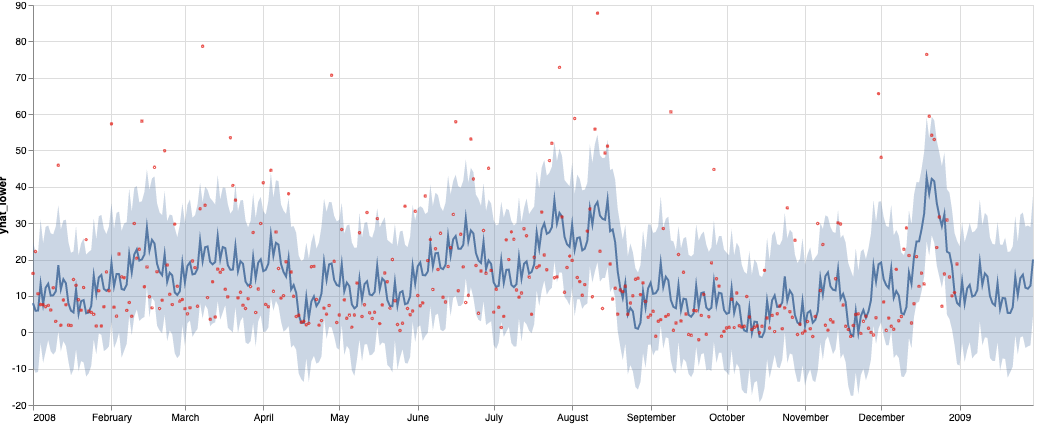
The above forecast is for a single city. If you want to create arrival delay forecasts for multiple cities in parallel, you can use frameworks like Dask or Ray that allow distributed execution.
## Parallelizing the Forecasts
In the example above, the function `get_delay_ts` returns a single time series for a city. You may want to compute arrival delay forecasts for a large number cities. Each prophet forecast takes approximately 1-2 seconds.
Let's see how many forecasts you need to generate:
```python
t.dest_city.nunique().execute()
#this should return the following, for the public flights dataset used above
290
```
At about 1-2 seconds per Prophet forecast, running these serially could take anywhere from 5-10 minutes\*\*.\*\* Because the time series for arrival delays for each city is independent, parallelization can speed up the process.
### Using Dask
Use Dask to parallelize this operation. First, make sure you have Dask installed in your Python environment:
```python
conda install -c conda-forge dask
```
Now, modify the method slightly to get the time series of daily arrival delays for a city. Make the city an optional parameter, and group by the city.
```python
def get_delay_ts(city: str = None):
ds=t.dep_timestamp.truncate('D').name('ds')
y = t.depdelay.mean().name('y')
filters = [ds.notnull()]
if city is not None:
filters.append(t.dest_city == city)
expr = t.filter(filters).group_by([ds, t.dest_city]).aggregate(y)
return expr
```
Try this modified method to see if it works correctly without a parameter for the city name.
```python
print(get_delay_ts().compile())
#This will return the following. Passing in a city parameter will filter by the city
SELECT DATE_TRUNC(DAY, "dep_timestamp") AS ds, "dest_city",
avg("depdelay") AS y
FROM flights_donotmodify
WHERE DATE_TRUNC(DAY, "dep_timestamp") IS NOT NULL
GROUP BY ds, dest_city
```
Now, use Dask to parallelize this operation.
```python
from dask import delayed
from dask.distributed import Client, progress
def get_forecast_for_ts(city, ts):
print(f'Computing forecast for {city}')
m = Prophet()
m.add_seasonality(name='yearly', period=365, fourier_order=10)
m.fit(ts)
future = m.make_future_dataframe(periods=7, freq='D')
fcst = m.predict(future)
return fcst
#This function creates an input dataframe for Prophet, keyed by city
#and executes the prophet forecast in parallel over a specified number of workers
def get_forecasts_dask(city:str = None):
input_df = get_delay_ts(city=city).execute()
#Change n_workers as needed for the machine you're running on (number of cores)
client = Client(threads_per_worker=1, n_workers=16)
#Use dask delayed, to create an array of deferred calls to the forecast method, splitting the above result dataframe by city
fcsts = [delayed(get_forecast_for_ts)(city=k, ts=v[['ds','y']]) for k, v in input_df.groupby('dest_city')]
#Run the forecasts in parallel
try:
forecasts = delayed(fcsts).compute()
return forecasts
except Exception as e:
print(f"Unexpected error {e}")
finally:
client.close()
```
You are ready to run parallelized forecasting. You have materialized the data for all cities in a single call, split the resulting dataframe by city, and handed it off to Dask to compute the forecast, returning an array with all the forecasts.
```python
%%time
dask_forecasts=get_forecasts_dask()
```
Once you start the run, you can examine the Dask UI at `localhost:8787` (assuming you can access it on the running machine), where you can see the entire process. With 16 cores (as specified in the call to Dask), forecasts for 288 cities complete in approximately *75-90 seconds*---a 3-6x increase in speed.
```python
CPU times: user 27 s, sys: 1.91 s, total: 28.9 s
Wall time: 1min 31s
```
### Using Ray
Next, let's use Ray, a distributed execution engine for Python. Ray is similar to Dask, but more specifically targeted at machine learning and deep learning workflows, and can be used to parallelize existing Python code. To get started, install Ray.
```python
pip install -U ray
```
Next, modify the methods used previously for use with Ray. In particular, declare the Prophet forecasting method to be a Ray *remote* method, which allows Ray to execute it on a cluster or a set of cores in parallel.
```python
import ray
#the below decorator allows Ray's runtime to execute multiple instances of it in parallel
@ray.remote
def get_forecast_for_ts(city, ts):
print(f'Computing forecast for {city}')
m = Prophet()
m.add_seasonality(name='yearly', period=365, fourier_order=10)
m.fit(ts)
future = m.make_future_dataframe(periods=7, freq='D')
fcst = m.predict(future)
return fcst
#This method is very similar to the Dask method, except for how Ray is invoked
def get_forecasts_ray(city:str = None):
ray.shutdown()
ray.init(ignore_reinit_error=True, log_to_driver=False, logging_level='INFO')
#Use Ibis to get the specific set of fuel locations to run the forecast on
input_df = get_delay_ts(city=city).execute()
#Create an array of deferred forecast objects that Ray will evaluate in parallel
fcsts = [get_forecast_for_ts.remote(city=k, ts=v[['ds','y']]) for k, v in input_df.groupby('dest_city')]
return ray.get(fcsts)
```
This starts a Ray distributed computation, similar to Dask. Ray is slightly faster for this same task.
```python
CPU times: user 16.4 s, sys: 762 ms, total: 17.1 s
Wall time: 1min 23s
```
```python
2020-08-30 16:20:02,762 INFO resource_spec.py:231 -- Starting Ray with 29.54 GiB memory available for workers and up to 14.77 GiB for objects. You can adjust these settings with ray.init(memory=, object_store_memory=).
2020-08-30 16:20:03,142 INFO services.py:1193 -- View the Ray dashboard at localhost:8265
CPU times: user 16.4 s, sys: 762 ms, total: 17.1 s
Wall time: 1min 23s
```