Execution Model¶
An NVSHMEM program consists of a set of NVSHMEM processes called PEs. While not required by NVSHMEM, in typical usage, PEs are executed using a single program, multiple data (SPMD) model. SPMD requires each PE to use the same executable; however, PEs are able to follow divergent control paths. PEs are implemented using OS processes and PEs are permitted to create additional threads, when threading support is enabled.
PE execution is loosely coupled, relying on NVSHMEM operations to
communicate and synchronize among executing PEs. The NVSHMEM phase in a
program begins with a call to the initialization routine
nvshmem_init or nvshmem_init_thread, which must be performed
before using any of the other NVSHMEM library routines. An NVSHMEM
program concludes its use of the NVSHMEM library when all PEs call
nvshmem_finalize or any PE calls nvshmem_global_exit. During a
call to nvshmem_finalize, the NVSHMEM library must complete all
pending communication and release all the resources associated to the
library using an implicit collective synchronization across PEs. Calling
any NVSHMEM routine before initialization or after nvshmem_finalize
leads to undefined behavior. After finalization, a subsequent
initialization call also leads to undefined behavior.
The PEs of the NVSHMEM program are identified by unique integers. The identifiers are integers assigned in a monotonically increasing manner from zero to one less than the total number of PEs. PE identifiers are used for NVSHMEM calls (e.g., to specify put or get routines on symmetric data objects, collective synchronization calls) or to dictate a control flow for PEs using constructs of C. The identifiers are fixed for the duration of the NVSHMEM phase of a program.
Progress of NVSHMEM Operations¶
The NVSHMEM model assumes that computation and communication are naturally overlapped. NVSHMEM programs are expected to exhibit progression of communication both with and without NVSHMEM calls. Consider a PE that is engaged in a computation with no NVSHMEM calls. Other PEs should be able to communicate (e.g., put, get, atomic, etc.) and complete communication operations with that computationally-bound PE without that PE issuing any explicit NVSHMEM calls. One-sided NVSHMEM communication calls involving that PE should progress regardless of when that PE next engages in an NVSHMEM call.
Invoking NVSHMEM Operations¶
Pointer arguments to NVSHMEM routines that point to non-const data
must not overlap in memory with other arguments to the same NVSHMEM
operation, with the exception of in-place reductions as described in
Section NVSHMEM_REDUCTIONS.
Otherwise, the behavior is undefined. Two arguments overlap in memory if
any of their data elements are contained in the same physical memory
locations. For example, consider an address  returned by the
returned by the
nvshmem_ptr operation for symmetric object 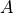 on PE
on PE
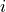 . Providing the local address and the symmetric
address of object to an NVSHMEM operation targeting PE
results in undefined behavior.
. Providing the local address and the symmetric
address of object to an NVSHMEM operation targeting PE
results in undefined behavior.
Buffers provided to NVSHMEM routines are in-use until the
corresponding NVSHMEM operation has completed at the calling PE. Updates
to a buffer that is in-use, including updates performed through locally
and remotely issued NVSHMEM operations, result in undefined behavior.
Similarly, reads from a buffer that is in-use are allowed only when the
buffer was provided as a const-qualified argument to the NVSHMEM
routine for which it is in-use. Otherwise, the behavior is undefined.
Exceptions are made for buffers that are in-use by AMOs, as described in
Section Atomicity Guarantees. For
information regarding the completion of NVSHMEM operations, see
Section Memory Ordering.
NVSHMEM routines with multiple symmetric object arguments do not require these symmetric objects to be located within the same symmetric memory segment. For example, objects located in the symmetric data segment and objects located in the symmetric heap can be provided as arguments to the same NVSHMEM operation.