|
|
L4T Multimedia API Reference28.2 Release |
|
|
L4T Multimedia API Reference28.2 Release |
This sample demonstrates the simplest way to use NVIDIA® TensorRT™ to decode video and save the bounding box information to the result.txt file. TensorRT was previously known as GPU Inference Engine (GIE).
This samples does not require a Camera or display.
$ cd $HOME/tegra_multimedia_api/samples/04_video_dec_trt $ make
$ ./video_dec_trt <in-file> <in-format> [options]
$ ./video_dec_trt ../../data/Video/sample_outdoor_car_1080p_10fps.h264 H264 \
--trt-deployfile ../../data/Model/GoogleNet_one_class/GoogleNet_modified_oneClass_halfHD.prototxt \
--trt-modelfile ../../data/Model/GoogleNet_one_class/GoogleNet_modified_oneClass_halfHD.caffemodel
The sample generates result.txt by default.The result saves the normalized rectangle within [0,1].
For example, the following shows the beginning of a result file:
frame:0 class num:0 has rect:3
x,y,w,h:0 0.333333 0.00208333 0.344444
x,y,w,h:0.492708 0.474074 0.05625 0.0888889
x,y,w,h:0.558333 0.609259 0.09375 0.181481
frame:1 class num:0 has rect:3
x,y,w,h:0 0.333333 0.003125 0.346296
x,y,w,h:0.491667 0.474074 0.0572917 0.0907407
x,y,w,h:0.558333 0.612963 0.0979167 0.185185
frame:2 class num:0 has rect:3
x,y,w,h:0 0.331481 0.003125 0.344444
x,y,w,h:0.492708 0.472222 0.0583333 0.0925926
x,y,w,h:0.559375 0.614815 0.102083 0.194444
frame:3 class num:0 has rect:2
x,y,w,h:0 0.32963 0.00208333 0.346296
x,y,w,h:0.560417 0.635185 0.105208 0.198148
frame:4 class num:0 has rect:2
x,y,w,h:0 0.32037 0.00208333 0.348148
x,y,w,h:0.561458 0.648148 0.113542 0.214815
frame:5 class num:0 has rect:3
x,y,w,h:0 0.324074 0.00208333 0.35
x,y,w,h:0.494792 0.487037 0.059375 0.087037
x,y,w,h:0.563542 0.661111 0.120833 0.225926
02_video_dec_cuda can verify the result and scale the rectangle parameters with the following command: $ cp result.txt $HOME/tegra_multimedia_api/samples/02_video_dec_cuda $ cd $HOME/tegra_multimedia_api/samples/02_video_dec_cuda $ ./video_dec_cuda ../../data/Video/sample_outdoor_car_1080p_10fps.h264 H264 --bbox-file result.txt
../../data/Model/GoogleNet_one_class/GoogleNet_modified_oneClass_halfHD.prototxtand the model file is:
../../data/Model/GoogleNet_one_class/GoogleNet_modified_oneClass_halfHD.caffemodel
GoogleNet_modified_oneClass_halfHD.prototxt, but is limited by the available system memory.$ rm trtModel.cache
The data pipeline is as follow:
Input video file -> Decoder -> VIC -> TensorRT Inference -> Plain text file with Bounding Box info
The sample does the following:
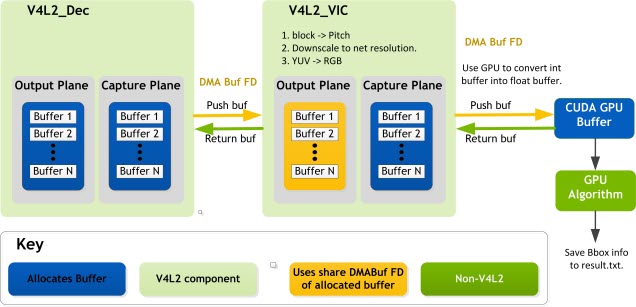
The block diagram contains not only the pipeline, but also the memory sharing information among different engines, which can be a reference for the other samples.
This sample uses the following key structures and classes:
The global structure context_t manages all the resources in the application.
| Element | Description |
|---|---|
| NvVideoDecoder | Contains all video decoding-related elements and functions. |
| NvVideoConverter | Contains elements and functions for video format conversion. |
| EGLDisplay | The EGLImage used for CUDA processing. |
| conv_output_plane_buf_queue | Output plane queue for video conversion. |
| TRT_Context | Provide a series of interfaces to load Caffemodel and do inference. |
| Member | Description |
|---|---|
| decCaptureLoop | Get buffers from dec capture plane and push to converter, and handle resolution change. |
| Conv outputPlane dqThread | Return the buffers dequeued from converter output plane to decoder capture plane. |
| Conv captuerPlane dqThread | Get buffers from conv capture plane and push to the TensorRT buffer queue. |
| trtThread | CUDA process and doing inference. |
$ ./video_dec_cuda <in-file> <in-format> --bbox-file result.txt
The default deploy file is
GoogleNet_modified_oneClass_halfHD.prototxt
The default model file is
GoogleNet_modified_oneClass_halfHD.caffemodel
In this directory:
$SDKDIR/data/Model/GoogleNet_one_class
End-of-stream (EOS) process:
a. Completely read the file.
b. Push a null v4l2buf to decoder.
c. Decoder waits for all output plane buffers to return.
d. Set get_eos:
decCap thread exit
e. End the TensorRT thread.
f. Send EOS to the converter:
conv output plane dqThread callback return false conv output plane dqThread exit conv capture plane dqThread callback return false conv capture plane dqThread exit
g. Delete the decoder:
deinit output plane and capture plane buffers
h. Delete the converter:
unmap capture plane buffers
./video_dec_trt <in-file> <in-format> [options]
| Option | Description |
|---|---|
--trt-deployfile | Sets deploy file name. |
--trt-modelfile | Sets the model file name. |
--trt-float32 <int> | Specifies to use float16 or not[0-2], where <int> is one of the following:
|
--trt-enable-perf | Enables performance measurement. |

