- Overview
- Building and Running
- Flow
- Key Structure and Classes
- Key Thread
- Programming Notes
- Command Line Options
Overview
This sample demonstrates the simplest way to use NVIDIA® TensorRT™ to decode video and save the bounding box information to the result.txt file. TensorRT was previously known as GPU Inference Engine (GIE).
This samples does not require a Camera or display.
Building and Running
Prerequisites
- You have followed Steps 1-3 in Building and Running.
- You have installed the following:
- NVIDIA® CUDA®
- TensorRT (previously known as GPU Inference Engine (GIE))
- OpenCV
To install TensorRT
- Open the apt source configuration file in a text editor:
$ sudo vi /etc/apt/sources.list.d/nvidia-l4t-apt-source.list
Change the repository name and download URL in the deb commands shown below:
deb https://repo.download.nvidia.com/jetson/common <release> main deb https://repo.download.nvidia.com/jetson/<platform> <release> main
<release> is the release number. Ex: r32.5.
<platform> identifies the platform's processor.
- t194 for Jetson AGX Xavier series or Jetson Xavier NX
- t186 for Jetson TX2 series
- t210 for Jetson Nano or Jetson TX1
- Enter:
$ sudo apt-get update $ sudo apt-get install tensorrt
To build:
- Enter:
$ cd /usr/src/jetson_multimedia_api/samples/04_video_dec_trt $ make
To run
- Enter:
$ ./video_dec_trt [Channel-num] <in-file1> <in-file2> ... <in-format> [options]
Example
The following example generates two results: result0.txt and result1.txt. The results contain normalized rectangle coordinates for detected objects.
$ ./video_dec_trt 2 ../../data/Video/sample_outdoor_car_1080p_10fps.h264 \
../../data/Video/sample_outdoor_car_1080p_10fps.h264 H264 \
--trt-onnxmodel ../../data/Model/resnet10/resnet10_dynamic_batch.onnx \
--trt-mode 0
Notes
- Boost the clock before running performance.
$ sudo ~/jetson_clocks.sh
- To change the batch size, use the
Channel-numoption. For information on opening more than 16 video devices, see the following NVIDIA® DevTalk topic:
- If the mode or any other parameter is changed, run the following command.
$ rm trtModel.cache
- The log shows the performance results with the following syntax:
Inference Performance(ms per batch):xx Wait from decode takes(ms per batch):xx
- To verify the result and scale the rectangle parameters, enter the following commands:
$ cp result*.txt /usr/src/jetson_multimedia_api/samples/02_video_dec_cuda $ cd /usr/src/jetson_multimedia_api/samples/02_video_dec_cuda $ ./video_dec_cuda ../../data/Video/sample_outdoor_car_1080p_10fps.h264 H264 --bbox-file result0.txt $ ./video_dec_cuda ../../data/Video/sample_outdoor_car_1080p_10fps.h264 H264 --bbox-file result1.txt
Flow
The data pipeline is as follow:
Input video file -> Decoder -> VIC -> TensorRT Inference -> Plain text file with Bounding Box info
Operation Flow
The sample does the following:
- Encodes the input video stream.
- Performs one-channel video decodeVIC, which does the following:
- Converts the buffer layout from block linear to pitch linear.
- Scales the image resolution to the resolution that TensorRT requires.
- Uses TensorRT to perform object identification and adds a bounding box to the object identified in the original frame.
- Converts the image from YUV to RGB format and saves it in a file.
The following block diagram shows the video decoder pipeline and memory sharing between different engines. This memory sharing also applies to other L4T Multimedia samples.
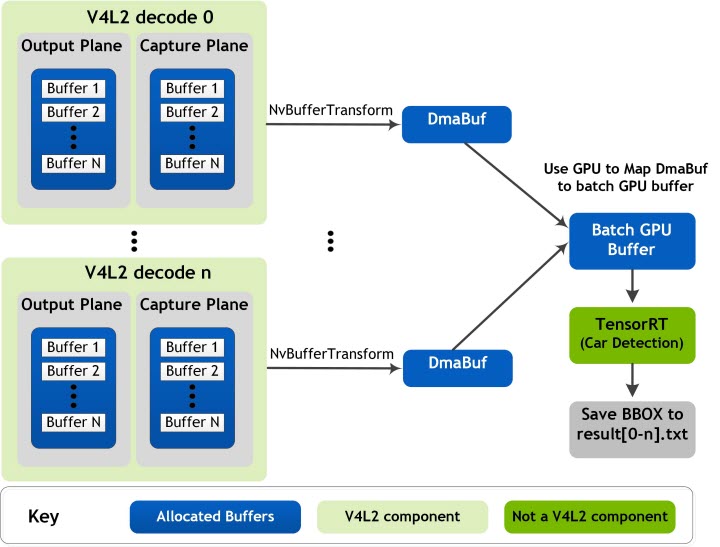
Key Structure and Classes
This sample uses the following key structures and classes:
The global structure context_t manages all the resources in the application.
| Element | Description |
|---|---|
| NvVideoDecoder | Contains all video decoding-related elements and functions. |
| NvVideoConverter | Contains elements and functions for video format conversion. |
| EGLDisplay | Specifies the EGLImage used for CUDA processing. |
| conv_output_plane_buf_queue | Specifies the output plane queue for video conversion. |
| TRT_Context | Specifies interfaces for loading ONNXmodel/Caffemodel and performing inference. |
Key Thread
| Member | Description |
|---|---|
| decCaptureLoop | Gets buffers from dec capture plane and push to converter, and handle resolution change. |
| Conv outputPlane dqThread | Returns the buffers dequeued from converter output plane to decoder capture plane. |
| Conv captuerPlane dqThread | Gets buffers from conv capture plane and push to the TensorRT buffer queue. |
| trtThread | Specifies the CUDA process and inference characteristics. |
Programming Notes
To display and verify the results and to scale the rectangle parameters, use the 02_video_dec_cuda sample as follows:
$ ./video_dec_cuda <in-file> <in-format> --bbox-file result.txt
The sample does the following:
- Saves the resulting normalized rectangle within [0,1].
- Supports in-stream resolution changes.
Uses the default file:
resnet10_dynamic_batch.onnx
In this directory:
$SDKDIR/data/Model/resnet10
Performs end-of-stream (EOS) processesing as follows:
a. Completely reads the file.
b. Pushes a null
v4l2bufto decoder.c. Waits for all output plane buffers to return.
d. Sets
get_eos:decCap thread exit
e. Ends the TensorRT thread.
f. Sends EOS to the converter:
conv output plane dqThread callback return false conv output plane dqThread exit conv capture plane dqThread callback return false conv capture plane dqThread exit
g. Deletes the decoder:
deinit output plane and capture plane buffers
h. Deletes the converter:
unmap capture plane buffers
Command Line Options
./video_dec_trt [Channel-num] <in-file1> <in-file2> ... <in-format> [options]
| Option | Description |
|---|---|
--trt-onnxmodel | Sets ONNX model file name. |
--trt-deployfile | Sets deploy file name.(Will be deprecated as TensorRT is deprecating Caffe Parser) |
--trt-modelfile | Sets the model file name.(Will be deprecated as TensorRT is deprecating Caffe Parser) |
--trt-mode <int> | Specifies to use float16 or not[0-2], where <int> is one of the following:
|
--trt-enable-perf | Enables performance measurement. |