Multi-Token Prediction (MTP)#
Multi-Token Prediction (MTP) extends the prediction scope to multiple future tokens at each position. On the one hand, an MTP objective densifies the training signals and may improve data efficiency. On the other hand, MTP may enable the model to pre-plan its representations for better prediction of future tokens. In this implementation of MTP, we sequentially predict additional tokens and keep the complete causal chain at each prediction depth. The following figure illustrates our implementation of MTP in DeepSeek-V3.
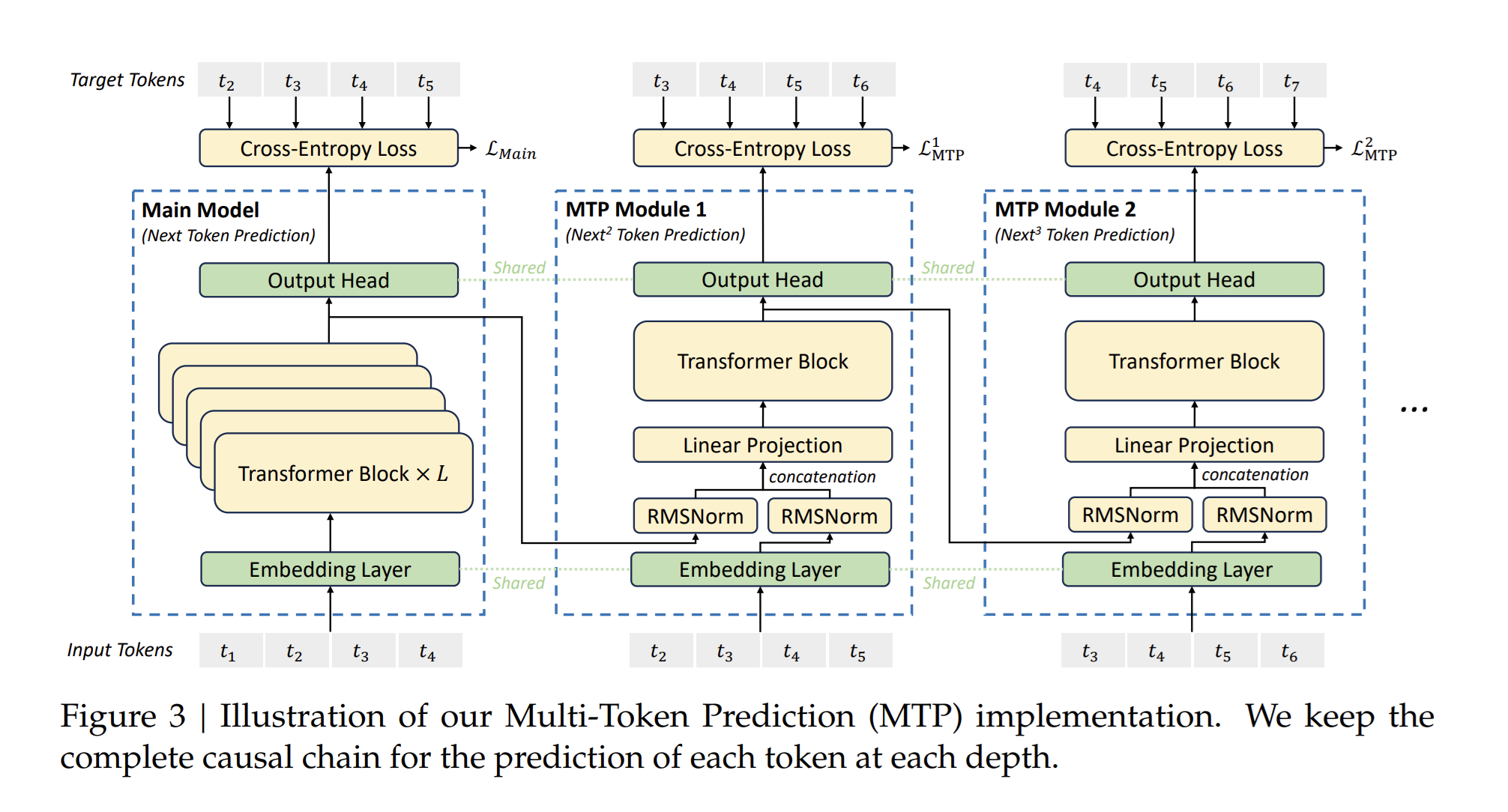
The k-th MTP module consists of a shared embedding layer, a projection matrix, a Transformer block, and a shared output head. For the i-th input token at the (k - 1)-th prediction depth, we first combine the representation of the i-th token and the embedding of the (i + K)-th token with the linear projection. The combined serves as the input of the Transformer block at the k-th depth to produce the output representation.
For more information, please refer to DeepSeek-V3 Technical Report
Precautions#
Please do not use Context Parallel (CP), or arbitrary AttnMaskType, or learned absolute position embedding type with MTP. These use cases are not yet supported.