Exporting the Model¶
The Transfer Learning Toolkit includes the tlt-export command to export and prepare
TLT models for Deploying to DeepStream. The tlt-export
command optionally generates the calibration cache for TensorRT INT8 engine calibration.
Exporting the model decouples the training process from inference and allows conversion to TensorRT engines outside the TLT environment. TensorRT engines are specific to each hardware configuration and should be generated for each unique inference environment. This may be interchangeably referred to as .trt or .engine file. The same exported TLT model may be used universally across training and deployment hardware. This is referred to as the .etlt file or encrypted TLT file. During model export TLT model is encrypted with a private key. This key is required when you deploy this model for inference.
INT8 Mode Overview¶
TensorRT engines can be generated in INT8 mode to improve performance, but require a calibration
cache at engine creation-time. The calibration cache is generated using a calibration tensor
file, if tlt-export is run with the --data_type flag set to int8.
Pre-generating the calibration information and caching it removes the need for calibrating the
model on the inference machine. Moving the calibration cache is usually much more convenient than
moving the calibration tensorfile, since it is a much smaller file and can be moved with the
exported model. Using the calibration cache also speeds up engine creation as building the
cache can take several minutes to generate depending on the size of the Tensorfile and the model
itself.
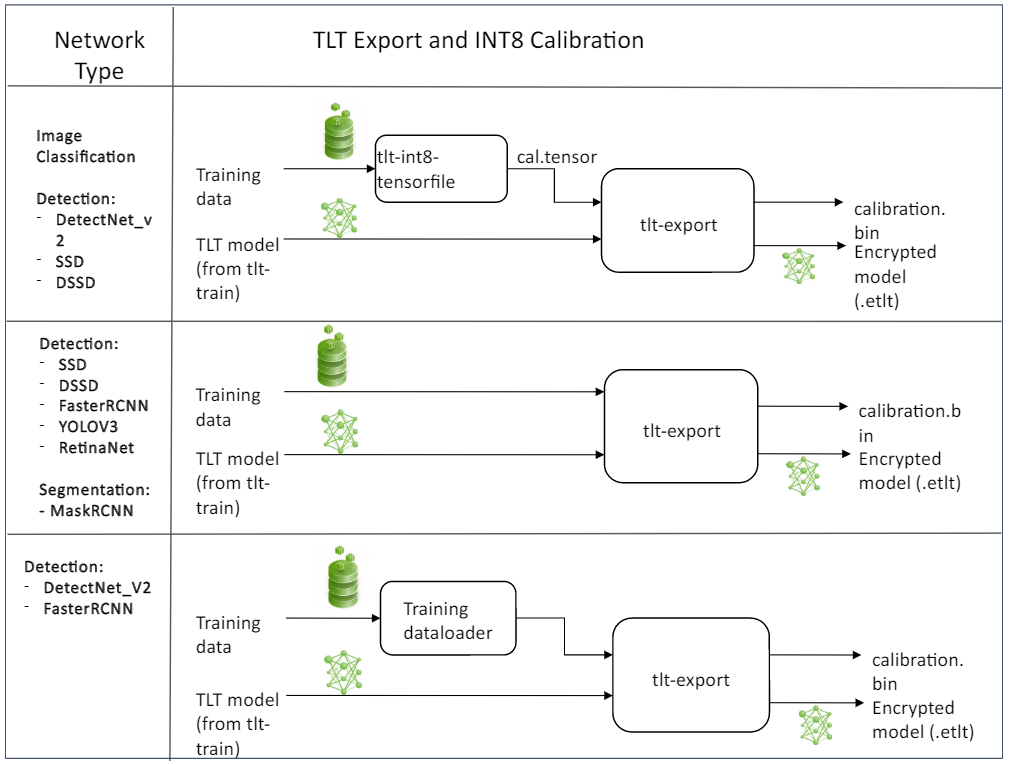
The export tool can generate INT8 calibration cache by ingesting training data using either of these options:
Option 1: Providing a calibration tensorfile generated using the
tlt-int8-tensorfilecommand. For image classification, and detection using Detectnet_v2, SSD and DSSD, the recommendation is to use this option, because thetlt-int8-tensorfilecommand uses the data generators to produce the training data. This helps easily generate a representative subsample of the training dataset.Option 2: Pointing the tool to a directory of images that you want to use to calibrate the model. For this option, make sure to create a sub-sampled directory of random images that best represent your training dataset. For FasterRCNN, YOLOV3 and RetinaNet detection architecture, only option 2 is supported.
Option 3: Using the training data loader to load the training images for INT8 calibration. This option is supported for DetectNet_v2 and FasterRCNN. This option is now the recommended approach to support multiple image directories by leveraging the training dataset loader. This also ensures two important aspects of data during calibration:
Data pre=processing in the INT8 calibration step is the same as in the training process
The data batches are sampled randomly across the entire training dataset, thereby improving the accuracy of the int8 model.
NVIDIA plans to eventually deprecate the Option 1 and only support Option 2 and 3.
FP16/FP32 Model¶
The calibration.bin is only required if you need to run inference at INT8 precision. For
FP16/FP32 based inference, the export step is much simpler. All that is required is to provide
a model from the tlt-train step to tlt-export to convert into an encrypted tlt
model.

Generating an INT8 tensorfile Using the tlt-int8-tensorfile Command¶
The INT8 tensorfile is a binary file that contains the preprocessed training samples, which maybe used to calibrate the model. In this release, TLT only supports calibration tensorfile generation for SSD, DSSD, DetectNet_v2 and classification models.
The sample usage for the tlt-int8-tensorfile command to generate a calibration
tensorfile is defined as below:
tlt-int8-tensorfile {classification, detectnet_v2} [-h]
-e <path to training experiment spec file>
-o <path to output tensorfile>
-m <maximum number of batches to serialize>
[--use_validation_set]
Positional Arguments¶
classificationdetectnet_v2ssddssd
Required Arguments¶
-e, --experiment_spec_file: Path to the experiment spec file (Only required for SSD and FasterRCNN)-o, --output_path: Path to the output tensorfile that will be created-m, --max_batches: Number of batches of input data to be serialized
Optional Argument¶
--use_validation_set: Flag to use validation dataset instead of training set.
Here’s a sample command to invoke the tlt-int8-tensorfile command for a classification
model.
tlt-int8-tensorfile classification -e $SPECS_DIR/classification_retrain_spec.cfg \
-m 10 \
-o $USER_EXPERIMENT_DIR/export/calibration.tensor
Exporting the Model Using tlt-export¶
Here’s an example of the command line arguments of the tlt-export command:
tlt-export [-h] {classification, detectnet_v2, ssd, dssd, faster_rcnn, yolo, retinanet}
-m <path to the .tlt model file generated by tlt train>
-k <key>
[-o <path to output file>]
[--cal_data_file <path to tensor file>]
[--cal_image_dir <path to the directory images to calibrate the model]
[--cal_cache_file <path to output calibration file>]
[--data_type <Data type for the TensorRT backend during export>]
[--batches <Number of batches to calibrate over>]
[--max_batch_size <maximum trt batch size>]
[--max_workspace_size <maximum workspace size]
[--batch_size <batch size to TensorRT engine>]
[--experiment_spec <path to experiment spec file>]
[--engine_file <path to the TensorRT engine file>]
[--verbose Verbosity of the logger]
[--force_ptq Flag to force PTQ]
Required Arguments¶
export_module: Which model to export, can beclassification,detectnet_v2,faster_rcnn,ssd,dssd,yolo, orretinanet. This is a positional argument.-m, --model: Path to the .tlt model file to be exported usingtlt-export.-k, --key: Key used to save the.tltmodel file.-e, --experiment_spec: Path to the spec file, this argument is required for faster_rcnn,ssd,dssd,yolo,retinanet.
Optional Arguments¶
-o, --output_file: Path to save the exported model to. The default is./<input_file>.etlt.--data_type: Desired engine data type, generates calibration cache if in INT8 mode. The options are: {fp32, fp16, int8} The default value is fp32. If using int8, following INT8 arguments are required.-s, --strict_type_constraints: A Boolean flag to indicate whether or not to apply the TensorRT strict_type_constraints when building the TensorRT engine. Note this is only for applying the strict type of INT8 mode.
INT8 Export Mode Required Arguments¶
--cal_data_file: tensorfile generated from tlt-int8-tensorfile for calibrating the engine. This can also be an output file if used with--cal_image_dir.--cal_image_dir: Directory of images to use for calibration.
Note
--cal_image_dir parameter for images and applies the necessary preprocessing
to generate a tensorfile at the path mentioned in the --cal_data_file
parameter, which is in turn used for calibration. The number of batches in the
tensorfile generated is obtained from the value set to the --batches parameter,
and the batch_size is obtained from the value set to the --batch_size
parameter. Be sure that the directory mentioned in --cal_image_dir has at least
batch_size * batches number of images in it. The valid image extensions are .jpg,
.jpeg, and .png. In this case, the input_dimensions of the calibration tensors
are derived from the input layer of the .tlt model.
INT8 Export Optional Arguments¶
--cal_cache_file: Path to save the calibration cache file. The default value is./cal.bin.--batches: Number of batches to use for calibration and inference testing.The default value is 10.--batch_size: Batch size to use for calibration. The default value is 8.--max_batch_size: Maximum batch size of TensorRT engine. The default value is 16.--max_workspace_size: Maximum workspace size of TensorRT engine. The default value is: 1073741824 = 1<<30)--experiment_spec: The experiment_spec for training/inference/evaluation. This is used to generate the graphsurgeon config script for FasterRCNN from the experiment_spec, only useful for FasterRCNN. This when used with DetectNet_v2 and FasterRCNN also sets up the dataloader based calibrator to leverage the training dataloader to calibrate the model.--engine_file: Path to the serialized TensorRT engine file. Note that this file is hardware specific, and cannot be generalized across GPUs. Useful to quickly test your model accuracy using TensorRT on the host. As TensorRT engine file is hardware specific, you cannot use this engine file for deployment unless the deployment GPU is identical to training GPU.--force_ptq: A boolean flag to force post training quantization on the exported etlt model.
Note
When exporting a model trained with QAT enabled, the tensor scale factors to calibrate
the activations are peeled out of the model and serialized to a TensorRT readable cache file
defined by the cal_cache_file argument. However, do note that the current version of
QAT doesn’t natively support DLA int8 deployment in the Jetson. Inorder to deploy
this model on a Jetson with DLA int8, please use the --force_ptq flag to use
TensorRT post training quantization to generate the calibration cache file.
Exporting a Model¶
Here’s a sample command to export a DetectNet_v2 model in INT8 mode. This command shows option 1;
uses --cal_data_file option with the calibration.tensor generated using
tlt-int8-tensorfile command.
tlt-export detectnet_v2 \
-m $USER_EXPERIMENT_DIR/experiment_dir_retrain/weights/resnet18_detector_pruned.tlt \
-o $USER_EXPERIMENT_DIR/experiment_dir_final/resnet18_detector.etlt \
-k $KEY \
--cal_data_file $USER_EXPERIMENT_DIR/experiment_dir_final/calibration.tensor \
--data_type int8 \
--batches 10 \
--cal_cache_file $USER_EXPERIMENT_DIR/experiment_dir_final/calibration.bin
--engine_file $USER_EXPERIMENT_DIR/experiment_dir_final/resnet_18.engine
Here’s an example log of a successful export:
Using TensorFlow backend.
2018-11-02 18:59:43,347 [INFO] iva.common.tlt-export: Loading model from resnet10_kitti_multiclass_v1.tlt
2018-11-02 18:59:47,572 [INFO] tensorflow: Restoring parameters from /tmp/tmp8crUBp.ckpt
INFO:tensorflow:Froze 82 variables.
2018-11-02 18:59:47,701 [INFO] tensorflow: Froze 82 variables.
Converted 82 variables to const ops.
2018-11-02 18:59:48,123 [INFO] iva.common.tlt-export: Converted model was saved into resnet10_kitti_multiclass_v1.etlt
2018-11-02 18:59:48,123 [INFO] iva.common.tlt-export: Input node: input_1
2018-11-02 18:59:48,124 [INFO] iva.common.tlt-export: Output node(s): ['output_bbox/BiasAdd', 'output_cov/Sigmoid']
Here’s a sample command using the --cal_image_dir option for a FasterRCNN model using
option 2.
tlt-export faster_rcnn \
-m $USER_EXPERIMENT_DIR/data/faster_rcnn/frcnn_kitti_retrain.epoch12.tlt \
-o $USER_EXPERIMENT_DIR/data/faster_rcnn/frcnn_kitti_retrain.int8.etlt \
-e $SPECS_DIR/frcnn_kitti_retrain_spec.txt \
--key $KEY \
--cal_image_dir $USER_EXPERIMENT_DIR/data/KITTI/val/image_2 \
--data_type int8 \
--batch_size 8 \
--batches 10 \
--cal_data_file $USER_EXPERIMENT_DIR/data/faster_rcnn/cal.tensorfile \
--cal_cache_file $USER_EXPERIMENT_DIR/data/faster_rcnn/cal.bin \
--engine_file $USER_EXPERIMENT_DIR/data/faster_rcnn/detection.trt