Example Workload: Large MoE LLM Inference#
This implementation addressed multiple challenges often faced during the deployment of LLMs.
Difficult UX: User experience is critical for distributed inference runtimes because managing large-scale inference systems is already complex, and poor usability further complicates matters. Developers need a clear, intuitive way to define, optimize, and update inference execution without wrestling with low-level infrastructure details. Without simple UX, inference runtimes remain inaccessible, prone to errors, and inefficient, hindering model deployment and innovation. A modern distributed inference stack must consider usability at its core—empowering developers to scale AI effortlessly for agentic workflows while ensuring correctness and performance.
GPU underutilization: Traditional monolithic inference pipelines often leave GPUs idle due to the imbalance between prefill and decode stages. Prefill (which generates large prompt embeddings) is highly compute-intensive, while decode (which generates tokens) is latency-sensitive. A disaggregated approach that separates prefill and decode ensures optimal GPU utilization and increases overall throughput (DistServe).
Expensive KV cache re-computation: When requests aren’t efficiently routed, KV caches (intermediate states of the transformer model) often get flushed and recomputed, leading to wasted computation cycles and increased latency. KV-aware request routing eliminates redundant KV cache regeneration, significantly boosting efficiency. (DeepSeek)
Memory bottlenecks: Large-scale inference workloads demand extensive KV cache storage, which can quickly overwhelm GPU memory capacity. KV cache offloading across memory hierarchies (HBM, DDR, NVMe or remote storage) enables models to scale beyond GPU memory limits and speeds up latency. (Mooncake, AIBrix, LMCache)
Fluctuating demand and inefficient GPU allocation: Inference workloads are use-case specific and dynamic—demand surges inherently cause unpredictability, yet traditional serving stacks allocate GPUs statically. Dynamic GPU scheduling ensures that resources are allocated based on real-time demand, preventing over-provisioning and improving utilization (AzureTrace)
Inefficient data transfer: Distributed inference workloads introduce unique and highly dynamic communication patterns that differ fundamentally from training. Unlike training, where worker roles remain largely static, inference requires real-time worker scaling, dynamic load balancing, and adaptive memory management—necessitating a communication layer that can efficiently handle these evolving requirements. Contemporary libraries are built for static, synchronous operations and lack the dynamicity needed for inference serving. While UCX provides high-performance networking, it requires deep networking expertise to configure correctly, making it impractical for broad inference use cases. Developers need a library optimized for inference workloads that can abstract heterogeneous memory (remote memory or storage) and dynamically select the best transport mechanism via a unified API.
To address the growing demands of distributed inference serving, NVIDIA built Dynamo. Dynamo tackles key challenges in scheduling, memory management, and data transfer. It employs KV-aware routing for optimized decoding, leveraging existing KV caches. For efficient global memory management at scale, it strategically stores and evicts KV caches across multiple memory tiers—GPU, CPU, SSD, and object storage—enhancing both time-to-first-token and overall throughput. Dynamo features NIXL (NVIDIA Inference tranXfer Library), a new data transfer engine designed for dynamic scaling and low-latency storage access.
Architecture Overview (Dynamo)#
Core Design Philosophy#
NVIDIA Dynamo builds upon the success of NVIDIA Triton Inference Server™, introducing a modular architecture specifically optimized for distributed generative AI inference. The framework supports all major LLM frameworks including NVIDIA TensorRT-LLM, vLLM, and SGLang.
Key Architectural Components#
1. Disaggregated Serving Architecture
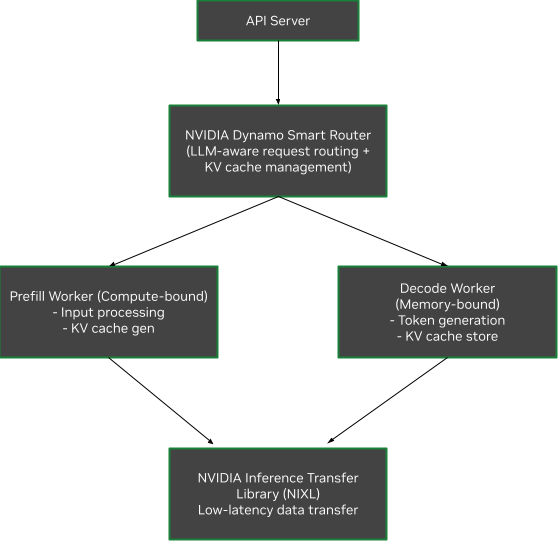
Disaggregated Serving Architecture#
2. NVIDIA Dynamo Planner
Continuously monitors GPU capacity metrics in distributed inference environments
Combines metrics with application SLOs (TTFT, inter-token latency)
Makes real-time decisions on disaggregated vs aggregated serving
Dynamic GPU worker allocation based on fluctuating demand
3. NVIDIA Dynamo Smart Router
Tracks KV cache across large fleets of GPUs
Hashes incoming requests and stores in Radix Tree
Minimizes KV cache recomputation through overlap scoring
Intelligent request routing considering cache hit rate and workload balance
4. NVIDIA Dynamo Distributed KV Cache Manager
Hierarchical caching across GPU, node, and cluster levels
KV cache offloading to cost-effective storage (CPU host memory, SSDs, networked storage)
Intelligent eviction policies balancing lookup latency vs recomputation costs
Framework-agnostic supporting PyTorch, SGLang, TensorRT-LLM, and vLLM
5. NVIDIA Inference Transfer Library (NIXL)
High-throughput, low-latency point-to-point communication library
Hardware-agnostic data movement API across memory hierarchies
Supports heterogeneous data paths (NVLink, InfiniBand, RoCE, Ethernet)
Optimized for inference data movement with nonblocking, noncontiguous transfers
Performance Characteristics#
DeepSeek-R1 Model Performance#
Deployment Environment: NVIDIA GB300 NVL72
Model Size: DeepSeek-R1 671B
Configuration: Disaggregated serving with EP4DP16 context, EP64DP3 generation
General Performance Gains#
Token/watt Improvement: 50x increase in requests served
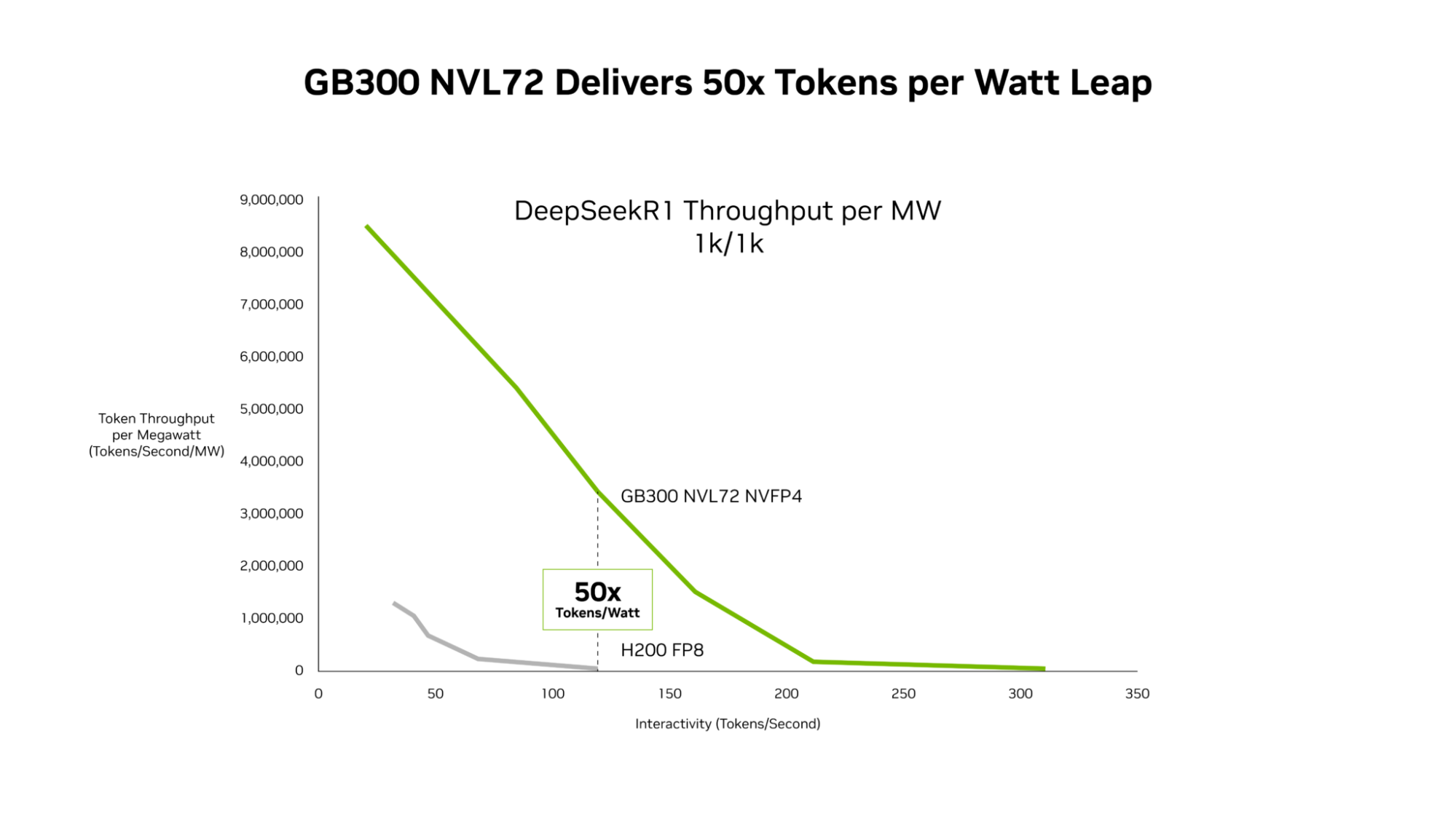
GB300 NVL72 Delivers up to 50x Better Performance for Low-Latency Workloads#
Improved TCO: 35x lower cost per million tokens compared with the Hopper platform.
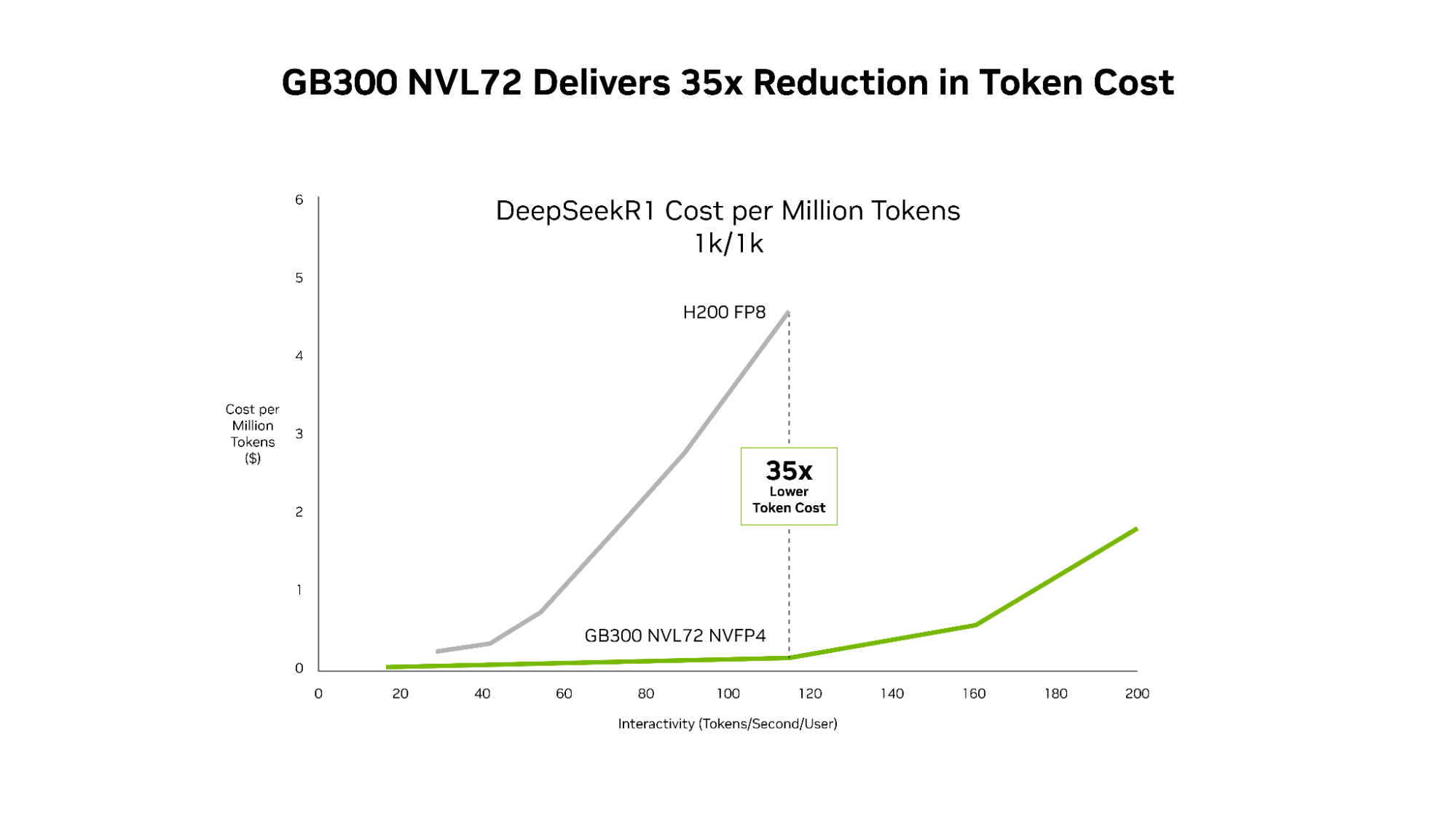
NVIDIA GB300 NVL72 and the codesigned software stack including NVIDIA Dynamo and TensorRT-LLM deliver 35x lower cost per token compared with the NVIDIA Hopper platform.#
Compute Performance: 1.5x higher NVFP4 compute performance and 2x faster attention processing compared with the GB200 platform.
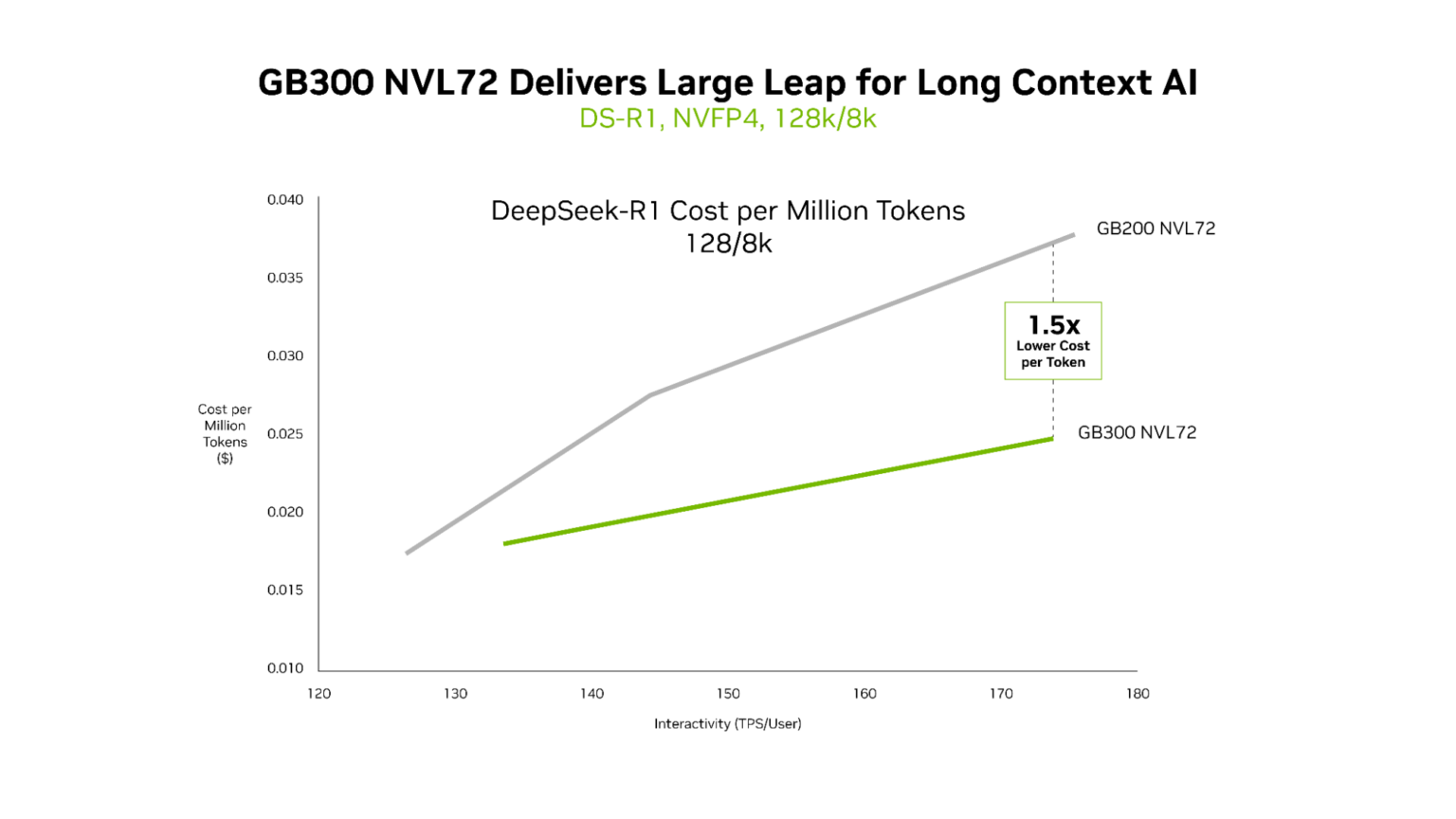
NVIDIA GB300 NVL72 is ideal for low-latency, long-context workloads.#
Technical Implementation Details#
Model Optimization#
The model was quantized to NVFP4 with NVIDIA Model Optimizer v0.23.0
Datasets:
Dataset |
Purpose |
Data collection method |
Labeling method |
|---|---|---|---|
cnn_dailymail |
Calibration Dataset |
Automated |
Unknown |
MMLU |
Evaluation Dataset |
Unknown |
N/A |
Prefill vs Decode Separation#
Prefill Phase:
Compute-bound operation
Processes user input to generate first output token
Optimized with low tensor parallelism to reduce communication overhead
Decode Phase:
Memory-bound operation
Generates subsequent tokens
Optimized with high tensor parallelism for improved memory operations
Cost Optimization Strategies#
Disaggregated Serving: Independent optimization of each phase
KV Cache Management: Tiered storage hierarchy reducing GPU memory requirements
Dynamic Scheduling: Resource allocation based on real-time workload demands
Request Routing: Minimizing computational costs through cache reuse
Integration Capabilities#
Framework Support: PyTorch, SGLang, NVIDIA TensorRT-LLM, vLLM
Networking: NVLink, InfiniBand (Quantum), Ethernet (Spectrum)
Storage: GPUDirect Storage, S3 integration
Deployment: Kubernetes compatible, available via NVIDIA NIM microservices
Reference Architecture#
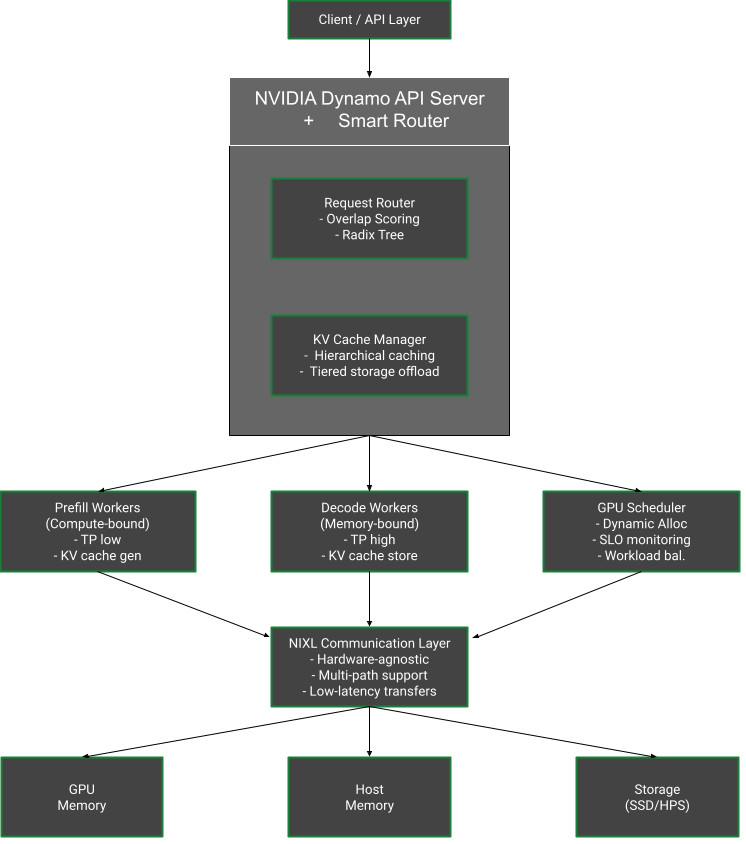
Reference Architecture#
Deployment Recommendations#
Scale-Out Strategy: Start with disaggregated serving for high-throughput workloads
Memory Hierarchy: Implement tiered KV cache management for cost optimization
Dynamic Allocation: Utilize Dynamo Planner for real-time resource optimization
Framework Integration: Leverage existing TensorRT-LLM or vLLM deployments
Network Optimization: Configure NVLink for intra-node, InfiniBand for inter-node communication