Important
NeMo 2.0 is an experimental feature and currently released in the dev container only: nvcr.io/nvidia/nemo:dev. Please refer to NeMo 2.0 overview for information on getting started.
GPT#
Released in 2018, OpenAI’s Generative Pre-trained Transformer 1 (GPT-1) set the tone for the LLM ecosystem with its decoder-only transformer architecture. Since the original release, OpenAI has released consistent improvements on the model in terms of data scale, network scale, and more. The documentation is compatible with both GPT-1 and GPT-2. You can use the NVIDIA NeMo™ framework to effectively train and scale GPT models to billions of parameters. This deep learning (DL) software stack is optimized for DGX SuperPOD configurations using NVIDIA InfiniBand technology to provide efficient on-premises compute for training and inferring complex workloads.
The model parallelism techniques of the NeMo Framework enable the efficient training of large models that do not fit in the memory of a single GPU. In the training tasks use both tensor (intra-layer) and pipeline (inter-layer) model parallelism. Tensor model parallelism partitions individual transformer layers over multiple devices. Pipeline model parallelism stripes layers of a model over multiple devices. For more details, refer to the paper Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM.
Two new techniques, sequence parallelism and selective activation recomputation, yield up to ~30% faster training time for GPT models ranging from 20B to 1T parameters.
Sequence parallelism expands tensor-level model parallelism by noticing that the regions of a transformer layer that have not previously been parallelized are independent along the sequence dimension. By splitting these layers along the sequence dimension it can distribute the computing load, and most importantly the activation memory, for these regions across the tensor parallel devices.
Selective activation recomputation improves performance in cases where memory constraints force the model to recompute some but not all of the activations. For more details, refer to the paper Reducing Activation Recomputation in Large Transformer Models.
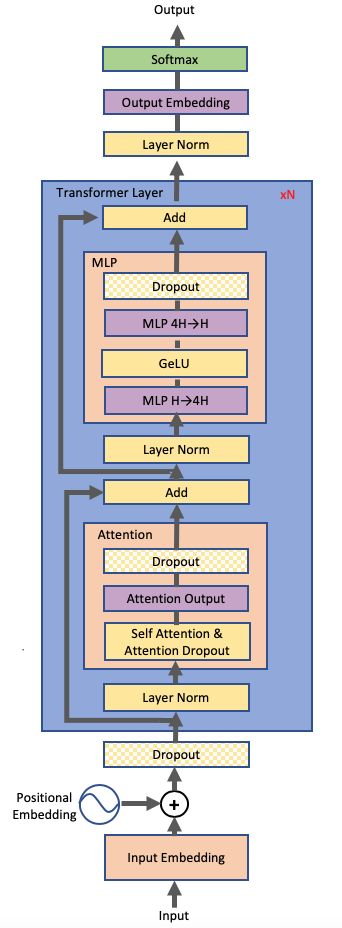
GPT Architecture#
In the Figure above, the 5B variant includes 24 transformer layers, a hidden size of 4096, and 32 attention heads. The sequence length is 2048, and the optimizer is Adam. This variant usestensor parallelism of 2.
Feature |
Status |
|---|---|
Data parallelism |
✓ |
Tensor parallelism |
✓ |
Pipeline parallelism |
✓ |
Interleaved Pipeline Parallelism Sched |
✓ |
Sequence parallelism |
✓ |
Selective activation checkpointing |
✓ |
Gradient checkpointing |
✓ |
Partial gradient checkpointing |
✓ |
FP32/TF32 |
✓ |
AMP/FP16 |
✗ |
BF16 |
✓ |
TransformerEngine/FP8 |
✓ |
Multi-GPU |
✓ |
Multi-Node |
✓ |
Inference |
N/A |
Slurm |
✓ |
Base Command Manager |
✓ |
Base Command Platform |
✓ |
Distributed data preprcessing |
✓ |
NVfuser |
✗ |
P-Tuning and Prompt Tuning |
✓ |
IA3 and Adapter learning |
✓ |
Distributed Optimizer |
✓ |
Distributed Checkpoint |
✓ |
Fully Shared Data Parallel |
✓ |
Torch Distributed Checkpoint |
✓ |