DreamFusion
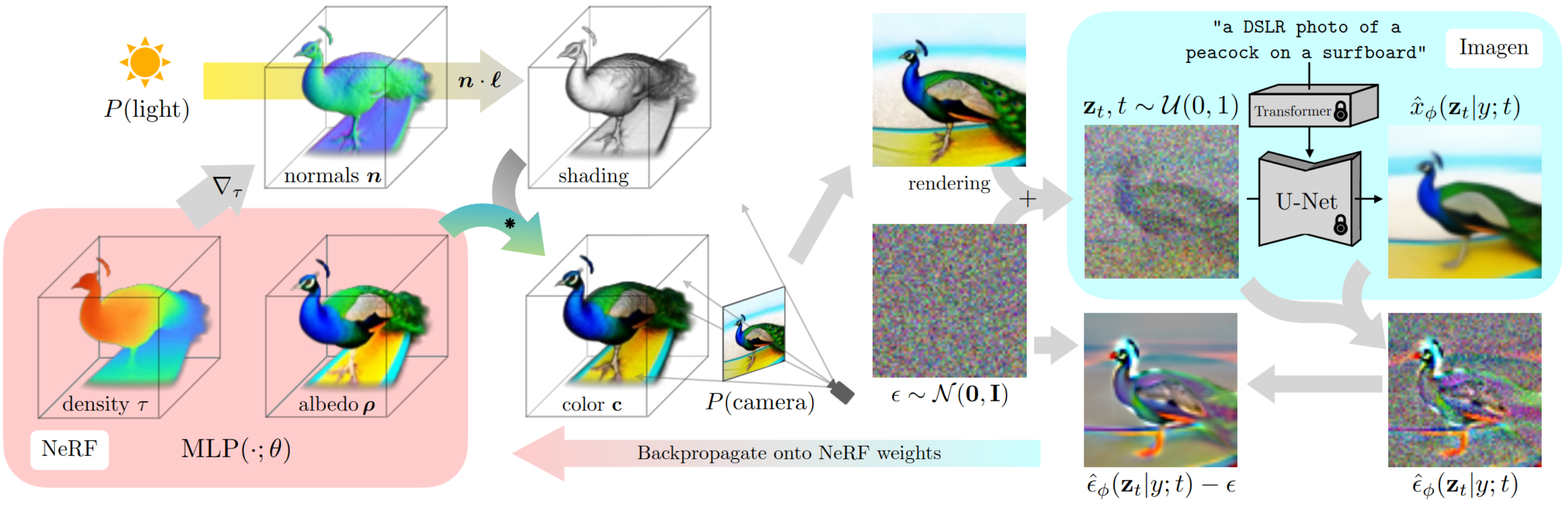
DreamFusion uses a pretrained text-to-image diffusion model to perform text-to-3D synthesis. The model uses a loss based on probability density distillation that enables the use of a 2D diffusion model as a prior for optimization of a parametric image generator.
Using this loss in a DeepDream-like procedure, the model optimizes a randomly-initialized 3D model (a Neural Radiance Field, or NeRF) via gradient descent such that its 2D renderings from random angles achieve a low loss. The resulting 3D model of the given text can be viewed from any angle, relit by arbitrary illumination, or composited into any 3D environment. This approach requires no 3D training data and no modifications to the image diffusion model, demonstrating the effectiveness of pretrained image diffusion models as priors.
Remarks
Notable differences from the paper:
We use Stable Diffusion for the guidance model, while the paper uses Imagen.
The nerf model is trained in latent space for the first 20,000 iterations, then on the RGB space for the remainder of the training run.
The NeRF and renderer implementations are different from the paper, we provide multiple backends for each.
The training schedule, learning rates, optimizer and hyperparameters are also different from the paper.
This model is based on a number of research papers and open-source projects, including:
Feature |
Training |
|---|---|
Data parallelism |
Yes |
Tensor parallelism |
No |
Sequence parallelism |
No |
Activation checkpointing |
Yes |
FP32/TF32 |
Yes |
AMP/BF16 |
Yes |
BF16 O2 |
No |
TransformerEngine/FP8 |
No |
Multi-GPU |
Yes |
Multi-Node |
No |
Inference deployment |
N/A |
SW stack support |
Slurm DeepOps/Base Command Manager/Base Command Platform |
NVfuser |
No |
Distributed Optimizer |
No |
TorchInductor |
Yes |
Flash Attention |
Yes |
TorchNGP renderer |
Yes |
NerfAcc renderer |
Yes |
TCNN NeRF backend |
Yes |
HuggingFace Stable Diffusion backend |
Yes |
NeMo Stable Diffusion backend |
Yes |
NeMo-TRT Stable Diffusion backend |
Yes |
GUI |
No |