NeMo QLoRA Guide
What is QLoRA?
Put simply, QLoRA is LoRA with quantized linear layers in the base model. The adapters are identical to those of LoRA and kept in higher precision (BF16) during QLoRA training. The base model is quantized with the NF4 data type made available through NVIDIA’s TensorRT-Model-Optimizer. This data format uses only 4.127 bits to store each floating point value, rather than 16 or 32 bits.
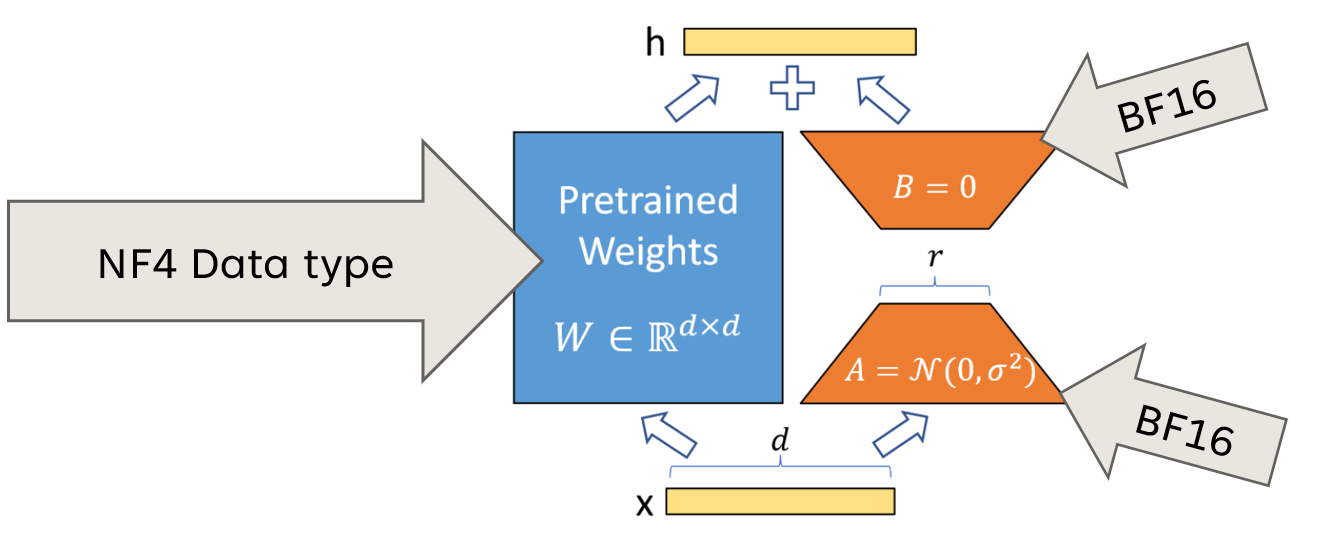
Compared to LoRA, QLoRA is
up to 60% more memory-efficient, allowing for fine-tuning large models with smaller/less GPUs and/or higher batch size.
able to achieve the same accuracy, although a different convergence recipe is required.
between 50% and 200% slower than LoRA.
You can read more about QLoRA in their paper.
How to run QLoRA in NeMo?
Note
QLoRA is available in the NeMo Framework 24.07 container.
You can enable QLoRA by setting the following flag in megatron_gpt_finetuning_config.yaml
model.peft.peft_scheme=qlora
To maximize the memory savings, set these three additional flags:
++model.dist_ckpt_load_on_device=False # load dist checkpoint on CPU
++model.use_cpu_initialization=True # initialize model on CPU
++model.peft.lora_tuning.target_modules=[all] # quantize all linear layers
The first two flags prevent memory spikes during model loading by loading the distributed checkpoint on CPU and initializing the blank model on CPU. The last flag is set because we want to quantize every linear layer to get the most memory savings. LoRA adapters are trained in BF16 to compensate for the corruption of the base model precision. Quantizing the base model without adding adapters will likely lead to very poor model accuracy. Thus, if you want to maximize memory savings, you need to apply the LoRA adapter to every linear layer. Remember that adapter weights only account for ~ 1% of the parameters of the linear layer to which they are applied.
You may need to adjust the learning rate and batch size to ensure convergence. The QLoRA paper suggests using a learning rate of 2e-4 for small models, 1e-4 for big (>33B) models, and a smaller batch size of 16 - 64 as opposed to 128 - 256 for LoRA. The LoRA rank has no impact on QLoRA convergence. See the QLoRA paper for more details.
model.global_batch_size=<adjusted batch size>
model.optim.lr=<adjusted learning rate>
With a small batch size, you can expect QLoRA to have a memory saving of around 50%. With a higher batch size, the memory savings is less because activations account for a higher proportion of GPU memory.
Because of this, with a small batch size, you can lower the total model parallel world size by a factor of 2 compared to LoRA; however, TP has to be kept to 1 for QLoRA. For example, if you need TP8 PP2 (model parallel size 16) to train a model with LoRA, then you should use TP1 PP8 (model parallel size 8) for QLoRA.
model.tensor_model_parallel_size=1
model.pipeline_model_parallel_size=<adjusted PP size>
You can monitor memory usage by setting this environment variable in the bash shell prior to training:
export NEMO_LOG_MEMORY_USAGE=1. The peak memory reserved will be logged to the logger of your choice
(e.g. WandB or tensorboard).
QLoRA Feature Matrix
Feature |
Status |
|---|---|
Data parallelism |
✓ |
Tensor parallelism |
✗ |
Pipeline parallelism |
✓ |
Sequence parallelism |
✗ |
Selective activation checkpointing |
✓ |
Gradient checkpointing |
✓ |
Partial gradient checkpointing |
✓ |
FP32/TF32 |
✓ |
AMP/FP16 |
✓ |
BF16 |
✓ |
TransformerEngine/FP8 |
✗ |
Multi-GPU |
✓ |
Multi-Node |
✓ |
Inference |
✓ |
Distributed Optimizer |
✗ |
Distributed Checkpoint |
✗ |
Fully Shared Data Parallel |
✗ |
Packed Sequence |
✓ |
QLoRA Evaluation
We provide two paths for QLoRA evaluation and inference. The two paths are mathematically identical, but are each suitable for different use cases.
1. Online Quantization for Framework Inference
The simplest way to evaluate is to use the same evaluation script as LoRA and set model.peft.peft_scheme=qlora.
This is referred to as “Online quantization” because the model is quantized after being loaded from disk.
Online quantization is suitable for framework inference.
2. Offline Quantization for QLoRA Deployment
For TensorRT inference and deployment, we need to quantize the base model offline and save it in the same format as an unquantized base model. For this, we provide an offline quantization script. The resulting model will have the same format as the input, but have weights compatible with adapters trained using QLoRA. This enables the TensorRT inference and deployment of QLoRA using the same code path as LoRA, making deployment workloads simpler and more general.