Additional Information
Troubleshooting
You can refer to the following documents for help with troubleshooting EVPN configurations:
- Troubleshooting EVPN
- EVPN Downstream VNI Configuration
- Troubleshooting EVPN Multihoming
- Verify EVPN-PIM
RDMA over Converged Ethernet (RoCE)
RoCE is a network protocol that leverages RDMA capabilities to accelerate communications between applications hosted on clusters of servers and storage arrays. RoCE is a remote memory management capability that allows server-to-server data movement directly between application memory without any CPU involvement. Both the transport processing and the memory translation and placement are performed by hardware resulting in lower latency, higher throughput, and better performance compared to software-based protocols.
With advances in data center convergence over reliable Ethernet, the ConnectX® Ethernet adapter cards family with its hardware offload support takes advantage of this efficient RDMA transport service over Ethernet to deliver ultra-low latency for performance-critical and transaction-intensive applications such as financial, database, storage, and content delivery networks.
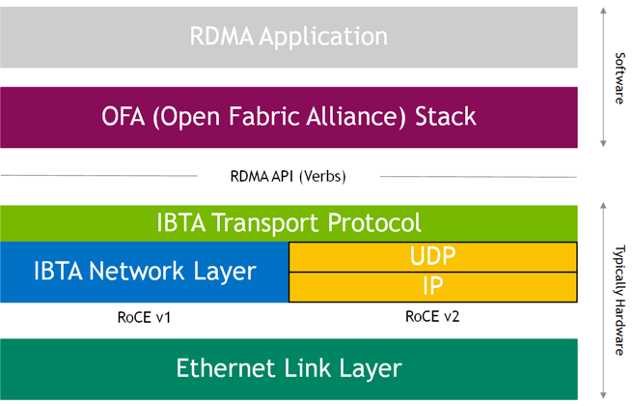
As originally implemented and standardized by the InfiniBand Trade Association (IBTA), RoCE was envisioned as an L2 protocol. Effectively the IBTA L1 and L2 fields are replaced by the corresponding Ethernet fields. Specifically at L2, the local routing header (LRH) is replaced by an Ethernet MAC header and frame check sequence. The EtherType field indicates the payload encapsulates the RoCE protocol which implements the IBTA protocol above L2. In addition, the IBTA network management (subnet manager) is replaced by standard Ethernet L2 management protocols.
This approach has the advantages that it is simple to implement, strictly layered, and preserves the application-level API verbs which sit above the channel interface. The disadvantage is the scalability limitations of an L2 Ethernet deployment caused by broadcast domains and the complexity of IP allocation constraints across a flat subnet. In addition, certain switches might forward RoCE packets on a slower exception path compared to the more common IP packets.
These limitations have driven the demand for RoCE to operate in L3 (routable) environments. A straightforward extension of the RoCE framework allows it to be readily transported across L3 networks. An L3 capable RoCE protocol simply continues up the stack and replaces the optional L3 global routing header (GRH) with the standard IP networking header and adds a UDP header as a stateless encapsulation of the L4 payload. This is a very natural extension of RoCE as the L3 header is already based on an IP address, therefore, this substitution is straightforward. In addition, the UDP encapsulation is a standard type of L4 packet and is forwarded efficiently by routers as a mainstream data path operation.
Figure 13 - RoCE
L2 Considerations
At the link level, lossless Ethernet L2 network can be achieved by using flow control. Flow control is achieved by either enabling global pause across the network, or by the use of PFC. PFC is a link level protocol that allows a receiver to assert flow control telling the transmitter to pause sending traffic for a specified priority. PFC supports flow control on individual priorities as specified in the class of service field of the 802.1Q VLAN tag. Therefore, it is possible for a single link to carry both lossless traffic to support RoCE and other best effort traffic on a lower priority class of service.
In a converged environment, lossy traffic shares the same physical link with lossless RoCE traffic. Typically, separate dedicated buffering and queue resources are allocated within switches and routers for the lossless and best-effort traffic classes that effectively isolate these flows from one another. Although global pause configuration is easier and might work nicely in a lab condition, PFC is recommended in an operational network to be able to differentiate between different flows. Otherwise, in case of congestion, important lossy traffic, such as control protocols, might be affected. You should run RoCE on a VLAN with priority enabled with PFC, and the control protocols (lossy) without flow control enabled on a different priority.
L3 Considerations
Operating RoCE at L3 requires that the lossless characteristics of the network are preserved across L3 routers that connect L2 subnets. The intervening L3 routers should be configured to transport L2 PFC lossless priorities across the L3 router between Ethernet interfaces on the respective subnets. This can typically be accomplished through standard router configuration mechanisms mapping the received L2 priority settings to the corresponding L3 DSCP QoS setting. The peer host should mark the RDMA packet with DSCP and L2 priority bits (802.1p or COS bits) (PCP). There are two ways for the router to extract the priority from the packet, either from the DSCP (in this case the packet could be untagged) or through PCP (in this case the packet must carry a VLAN (as the PCP is part of the VLAN tag). The router should keep the DSCP bits unchanged, and make sure the L2 PCP bits (if VLAN exists) are copied to the next network.
Instead of being constrained by L2 link-breaking protocols such as STP, L3 networks can implement forwarding algorithms that take much better advantage of available network connectivity. Advanced data center networks can utilize multi-path routing mechanisms for load balancing and improved utilization. One commonly used protocol to achieve these goals is ECMP. When using Reliable Connection RDMA (RC) the Source UDP port is scrambled per QP. This helps for the ECMP hash function to span different RDMA flows on different spines in a large L3 network.
Data Center Digital Twin (NVIDIA Air)
The NVIDIA approach to NetDevOps and CI/CD for networks starts with a Digital Twin of a complete data center network that can be hosted on the NVIDIA AIR (air.nvidia.com) platform or on your own private or public cloud.
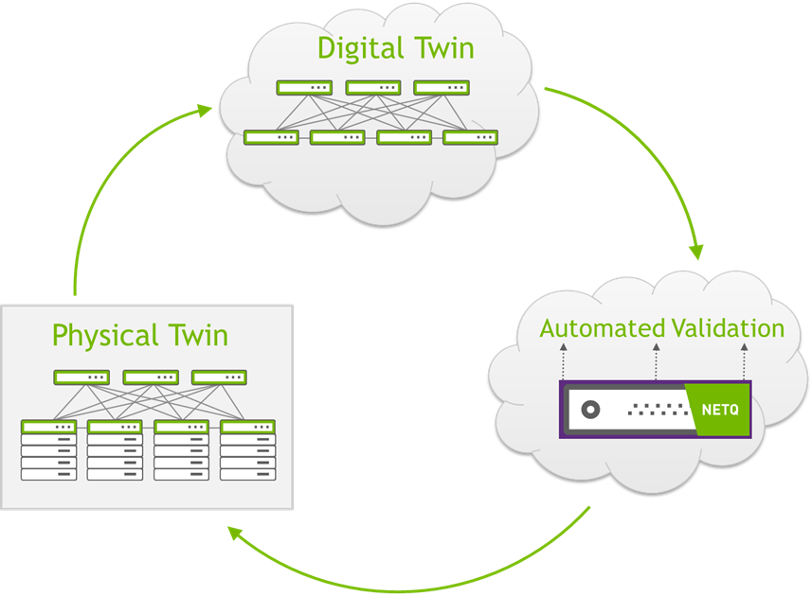
This Digital Twin has logical instances of every switch and cable, as well as many servers, which enables it to be used for validating security policy compliance, automation process, monitoring tools, interoperability, and upgrade procedures. No other vendor can match this functionality. Our SE’s can create a clone of your existing environment of 100+ switches in minutes.
When the physical equipment gets installed, cabled, and powered on, the entire data center network can be up and running in minutes - reducing the time to production by 95%. But now this environment is software-defined and hardware-accelerated in a way that is ready for the CI/CD operational model where the network infrastructure is treated as code because that Digital Twin doesn’t go away after the production network is running.
Instead, any change requests get implemented in the Digital Twin first, where it can be verified that the security, automation, monitoring, and upgrade processes are still in compliance. Only after the functionality has been verified do the changes get pushed into the production environment. This verification process improves security and speeds up change requests, and has been shown to decrease unplanned data center downtime by 64%, according to a 2021 IDC report.
The demo marketplace on NVIDIA Air has some fully configured pre-built labs that demonstrate best-practice configuration.
- EVPN L2 Extension
- EVPN Centralized Routing
- EVPN Symmetric Routing
- EVPN Multihoming
Automation
Cumulus switches are the only ones that provide a true choice in automation - you can automate with the CLI or API, or use Linux methods (by creating flat files) with any tool of your choice, by natively treating Cumulus Linux like any other Linux server. Every other implementation uses Expect scripts or “Ansible Agents” that provide a subset of the full power of a native Ansible solution.
Production Ready Automation (PRA)
The Production Ready Automation package from NVIDIA provides several examples of a fully operationalized, automated data center and includes:
- A standard reference topology for all examples.
- A variety of golden standard EVPN-VXLAN architecture reference configurations.
- A full Vagrant and libvirt simulation of the NVIDIA reference topology (cldemo2) that provides the foundational physical infrastructure and bootstrap configuration to support and demonstrate Cumulus Linux features and technologies.
- Best practice Ansible automation and infrastructure as code (IaC).
- Working examples of Continuous Integration and Continuous Deployment (CI/CD) using GitLab.
- CI/CD testing powered by NetQ Cloud.
You can use this Production Ready Automation package as a learning resource and as a starting template to implement these features, technologies, and operational workflows in your Cumulus Linux network environments. NVIDIA currently provides three officially supported demo solutions to overlay and provision the reference topology. These demos are EVPN-VXLAN environments and each performs tenant routing in a different style.
The golden standard demos and the underlying base reference topology are officially hosted on GitLab in the Golden Turtle folder of the Cumulus Consulting GitLab group.
- EVPN L2 Only is an EVPN-VXLAN environment with only an L2 extension.
- EVPN Centralized Routing is an EVPN-VXLAN environment with an L2 extension between tenants with inter-tenant routing on a centralized (fw) device.
- EVPN Symmetric Mode is an EVPN-VXLAN environment with an L2 extension, L3 VXLAN routing, and VRFs for multi-tenancy.
For more detailed information about IP addressing and included features, refer to the README page of the demo.
NetDevOps (CI/CD)
NVIDIA Spectrum offers the cloud-scale operational models and actionable visibility needed to enable Accelerated Ethernet. The Cumulus Linux network operating system is built on a standardized Linux stack, which integrates natively with automation and monitoring toolsets. With Cumulus Linux, you can tap into increased operational efficiency by reducing time-to-production by up to 95 percent, and spending 36 percent less IT time “keeping the lights on”. In addition, NVIDIA Air enables you to build data center digital twins and simulate upgrades, automation, and policies first to deploy with confidence. NVIDIA NetQ provides unparalleled visibility into the inner workings of the network, including the switch and DPU, providing cloud-scale insight and validation to reduce mean time to innocence and keep your network operations on track.