Deploy NVIDIA NIM on Google Kubernetes Engine (GKE)#
NVIDIA NIM is a set of easy-to-use microservices designed to accelerate the deployment of generative AI models across the cloud, data center, and workstations. NIM makes it easy for you to self-host large language models (LLMs) in your own managed environments, while still providing you with industry standard APIs to build powerful copilots, chatbots, and AI assistants that can transform your business.
Google Kubernetes Engine (GKE) is a managed Kubernetes service that provides a scalable and secure platform for deploying, managing, and scaling containerized applications. GKE offers features such as automated upgrades and repairs, auto-scaling, cluster management, network security, and more.
There are two options to deploy NIM on GKE:
You can use the integrated NIM on GKE Kubernetes application — Use this when you want to quickly see a running example of a NIM deployed on GKE.
You can create your own cluster via Terraform and Helm — Use this when you prefer to have full control of your cluster and NIM deployment.
Integrated NIM on GKE Kubernetes Application#
NIM is integrated with GKE as a ready to deploy Kubernetes application that you can deploy and use in your own cluster. Use the documentation in this section to do the following:
Verify Prerequisites#
Before you can use the integrated NIM on GKE Kubernetes application, you need the following:
A Google Cloud Platform (GCP) account.
A billing method configured for your account.
A project that you have ownership in (or that already has a sufficiently privileged service account). The required service account roles are the following:
Artifact Registry Reader
Cloud Infrastructure Manager Admin
Cloud Infrastructure Manager Agent
Compute Network Admin
Kubernetes Engine Admin
Kubernetes Engine Node Service Account
Service Account Admin
Service Account User
Service Usage Admin
Storage Admin
Deploy NIM#
Use the following procedure to deploy NIM on GKE by using the integrated Kubernetes application.
Log in to the Google Cloud console.
Open the NVIDIA NIM page on GCP marketplace.
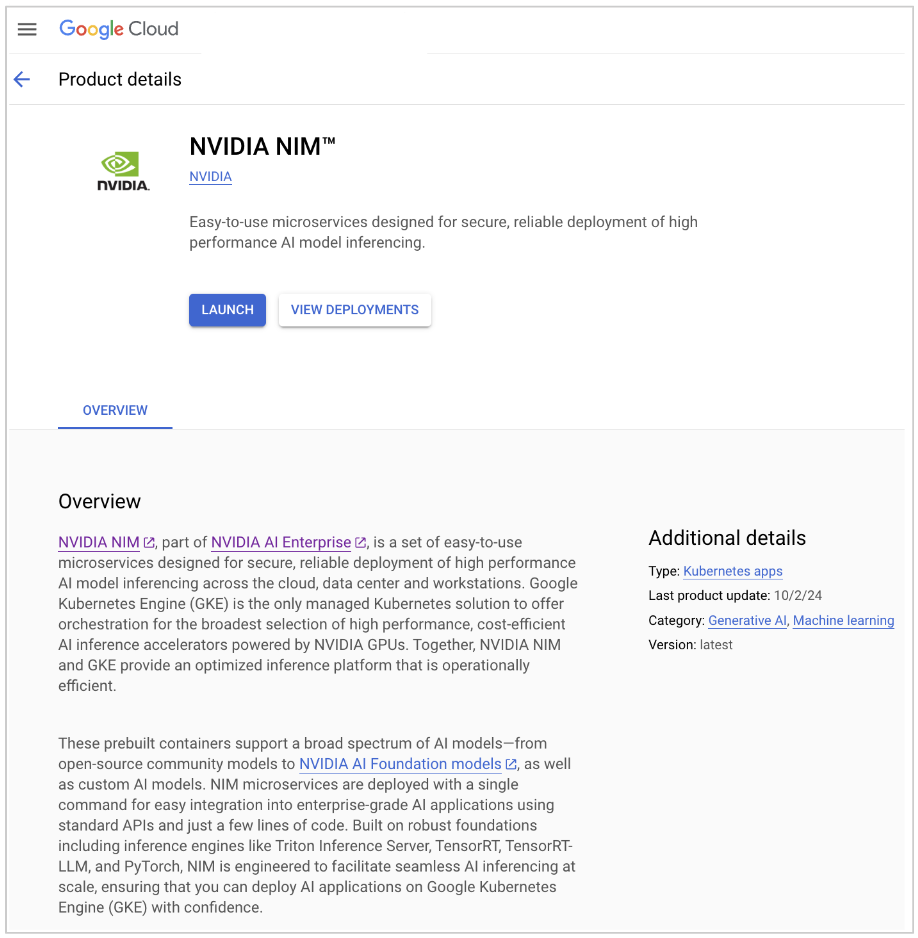
Click LAUNCH. The New NVIDIA NIM deployment page appears.
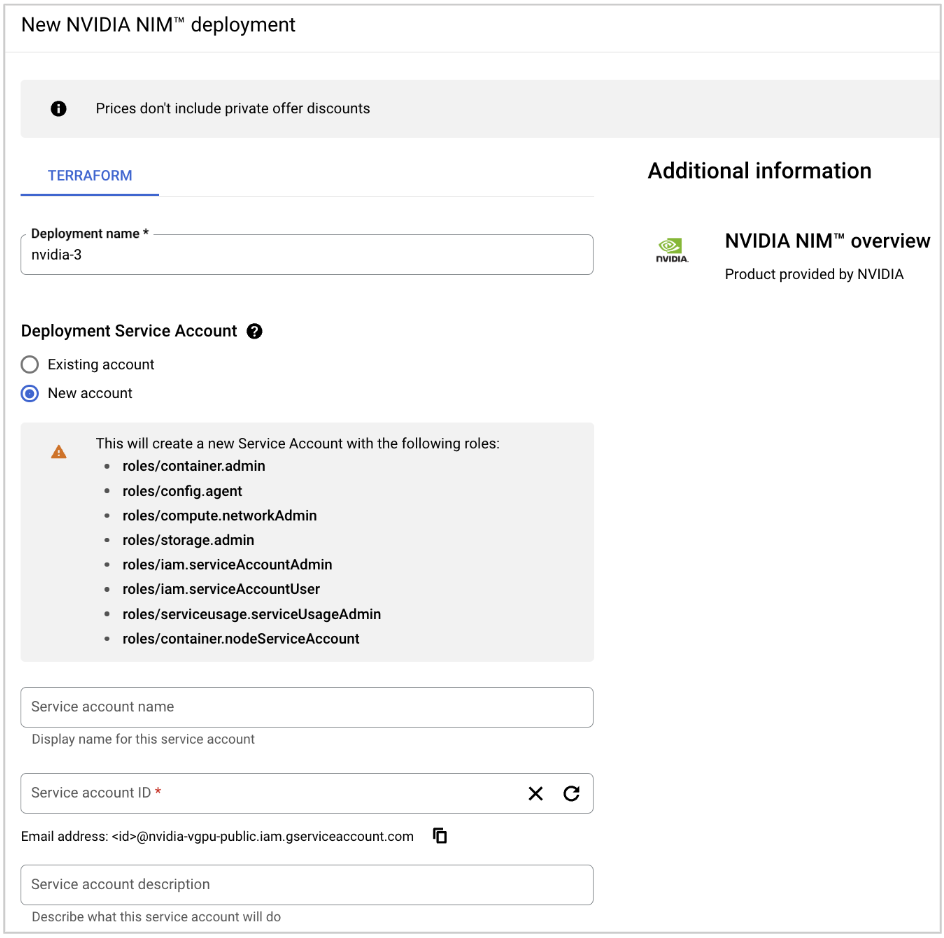
Enter a Deployment name.
For Deployment Service Account, choose an existing account or create a new one, and provide all account details.
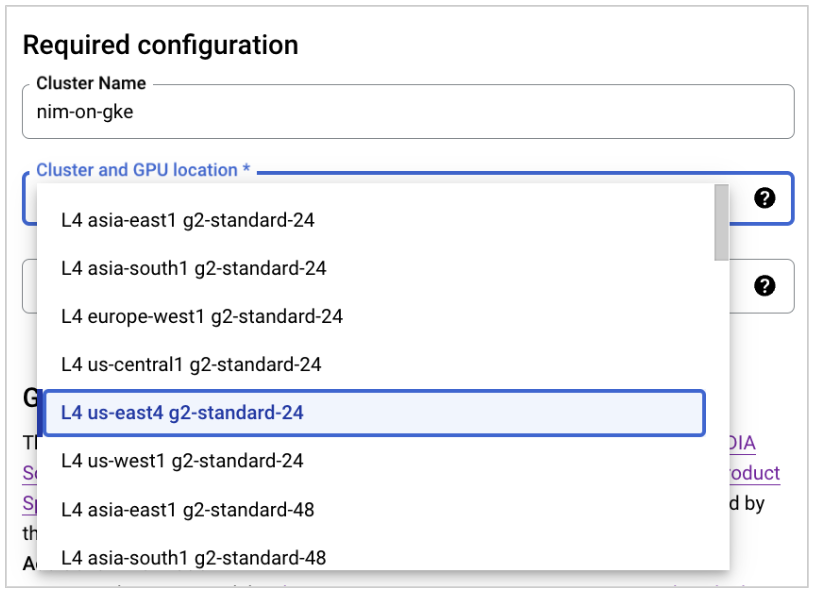
For Cluster and GPU location, select the appropriate region and GPU.
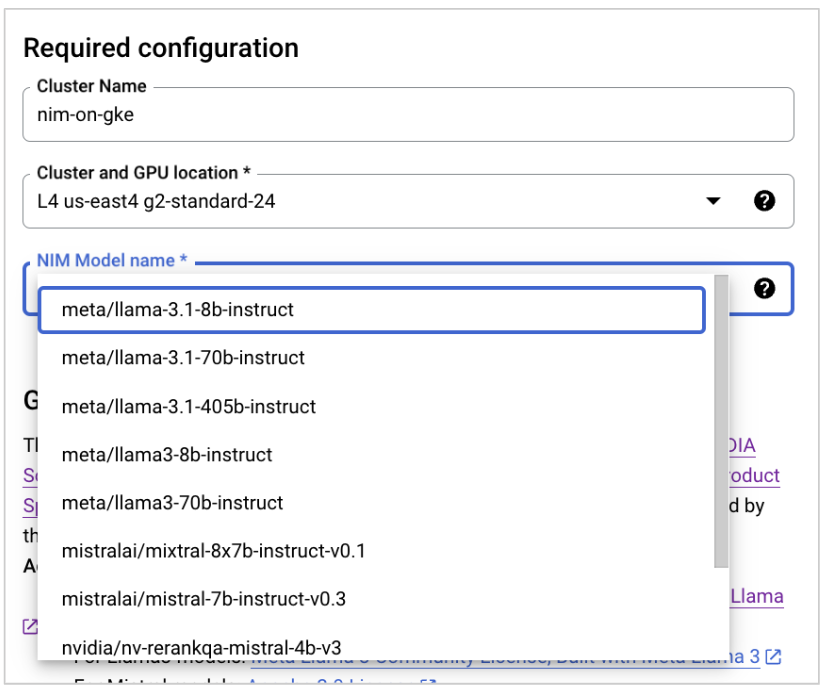
For NIM Model name, select the model that you want to use.
Read and agree to the Terms and Conditions.
Click Deploy. The deployment takes approximately 15-20 minutes depending on the NIM Model and cluster parameters.
Test Your NIM#
Navigate to the Google Cloud Kubernetes Engine Clusters page.
Connect to the new cluster by choosing Connect from the option menu.
Get credentials for the GKE cluster by running the following code.
1gcloud container clusters get-credentials $CLUSTER --region $REGION --project $PROJECT
Set up port forwarding to the NIM container by running the following code.
1kubectl -n nim port-forward service/my-nim-nim-llm 8000:8000 &
Run inference requests against the NIM endpoint as shown in the following code. For more information, see nim-deploy/cloud-service-providers/google-cloud/gke/README.md. on GitHub.
Caution
Make sure the URL and the model name are correct in the code.
1curl -X GET 'http://localhost:8000/v1/health/ready' 2 3curl -X GET 'http://localhost:8000/v1/models' 4 5curl -X 'POST' \ 6 'http://localhost:8000/v1/chat/completions' \ 7 -H 'accept: application/json' \ 8 -H 'Content-Type: application/json' \ 9 -d '{ 10"messages": [ 11 { 12 "content": "You are a polite and respectful chatbot helping people plan a vacation.", 13 "role": "system" 14 }, 15 { 16 "content": "What should I do for a 4 day vacation in Spain?", 17 "role": "user" 18 } 19], 20"model": "meta/llama-3.1-8b-instruct", 21"max_tokens": 4096, 22"top_p": 1, 23"n": 1, 24"stream": false, 25"stop": "\n", 26"frequency_penalty": 0.0 27}'
Note
For reranking models, use the following call:
1# rerank-qa 2curl -X 'POST' \ 3'http://localhost:8000/v1/ranking' \ 4-H 'accept: application/json' \ 5-H 'Content-Type: application/json' \ 6-d '{ 7"query": {"text": "which way should i go?"}, 8"model": "nvidia/nv-rerankqa-mistral-4b-v3", 9"passages": [ 10{ 11"text": "two roads diverged in a yellow wood, and sorry i could not travel both and be one traveler, long i stood and looked down one as far as i could to where it bent in the undergrowth;" 12}, 13{ 14"text": "then took the other, as just as fair, and having perhaps the better claim because it was grassy and wanted wear, though as for that the passing there had worn them really about the same," 15}, 16{ 17"text": "and both that morning equally lay in leaves no step had trodden black. oh, i marked the first for another day! yet knowing how way leads on to way i doubted if i should ever come back." 18} 19] 20}'
Note
For embedding models, use the following call:
1# embed 2curl -X "POST" \ 3"http://localhost:8000/v1/embeddings" \ 4-H 'accept: application/json' \ 5-H 'Content-Type: application/json' \ 6-d '{ 7"input": ["Hello world"], 8"model": "nvidia/nv-embedqa-e5-v5", 9"input_type": "query" 10}'
(Optional) You can also load test and get performance metrics, such as throughput and latency of the deployed model, by using the NVIDIA Gen-AI performance tool. For more information, see NIM for LLM Benchmarking Guide.
Release Resources#
After you are done with your NIM, use the following procedure to release resources.
Navigate to the Solution deployments page.
Click the three dots next to your deployment, and then click Delete.
Create Your Own Cluster via Terraform and Helm#
If you prefer to have full control of your cluster and NIM deployment, you can leverage Terraform scripts and Helm charts. Follow the instructions in the GitHub project nim-deploy/cloud-service-providers/google-cloud/gke.