Introduction#
This document describes the NVIDIA NIM for Cosmos WFM (World Foundation Models), which currently includes the Cosmos-Predict1 WFM, Cosmos-Transfer2.5 WFM, and Cosmos3 WFM.
Note
Refer to the NVIDIA NIM for VLMs site for Cosmos-Reason1, Cosmos-Reason2, and Cosmos3-Reasoner NIM documentation.
NVIDIA NIM allows IT and DevOps teams to self-host Cosmos in their own managed environments, while still providing developers with industry-standard APIs for building advanced AI-powered applications. Leveraging cutting-edge GPU acceleration and scalable deployment, NIM offers the fastest path to inference with unparalleled performance.
To discover other NIMs and APIs, visit the API catalog.
Architecture#
NIMs are packaged as container images on a model-family basis. Each NIM is its own Docker container with a model,
such as nvidia/cosmos-predict1-7b-text2world, nvidia/cosmos-predict1-7b-video2world, nvidia/cosmos-transfer2.5-2b,
and nvidia/cosmos3-generator (available on NGC as nvcr.io/nim/nvidia/cosmos3-generator:latest).
Models are automatically downloaded from NGC, leveraging a local
filesystem cache if available. Each NIM is built from a common base, so once a NIM has been downloaded,
additional NIMs can be downloaded quickly.
When a NIM is first deployed, it inspects the local hardware configuration and the available model versions in the model registry; it then automatically chooses the best version of the model for the available hardware.
NIMs are distributed as NGC container images through the NVIDIA NGC Catalog. A security scan report is available for each container in the NGC catalog, which provides a security rating of that image, a breakdown of CVE severity by package, and links to detailed information on the CVEs.
The NIM for Cosmos WFM sets up a Triton Inference Server that handles the model serving and inference operations. This architecture provides the following:
HTTP API: A RESTful interface for making inference requests, checking model health, and retrieving metadata
Resource Management: Efficient GPU memory utilization and compute scheduling
Monitoring: Built-in metrics and observability endpoints
Applications can interact with the NIM through either the HTTP API or gRPC interface, depending on their specific requirements. The API Reference provides detailed information on available endpoints and request formats.
Pipeline Architecture#
The Cosmos-Predict1-7B model family features two NVIDIA NIMs:
Cosmos-Predict1-7B-Text2World: Performs text-to-world generation.Cosmos-Predict1-7B-Video2World: Performs both image-to-world and video-to-world generation (an image can be represented as single frame video).
The Cosmos-Transfer model family features one NVIDIA NIM:
Cosmos-Transfer2.5-2B: A more efficient and lightweight model for video-to-video style transfer, with enhanced control capabilities and faster inference times.
The Cosmos3 model family features two NVIDIA NIMs — Cosmos3-Generator and Cosmos3-Reasoner
(documented separately). This guide covers Cosmos3-Generator:
Cosmos3-Generator: A generative world foundation model. The container image bundles two model sizes — 8B (nano, default) and 32B (super) — selected at boot viaNIM_MODEL_SIZE=nano|super; both sizes share the same HTTP API contract and support text-to-video (T2V) and image-to-video (I2V) generation modes. Text-only generation lives inCosmos3-Reasoner; it is documented separately.
Model Architecture for Cosmos-Predict1-7B#
Cosmos-Predict1-7B is a specialized Transformer model designed for video denoising within the latent space. The model architecture consists of the following components:
Transformer Backbone: A deep network of interleaved self-attention, cross-attention, and feedforward layers
Cross-Attention Mechanism: Enables text conditioning throughout the denoising process by attending to text embeddings.
Adaptive Layer Normalization: Applied before each layer to incorporate temporal information for denoising
Temporal Modeling: Special attention mechanisms to handle the temporal aspects of video generation
Latent Space Processing: Works in a compressed latent space for efficient video generation.
The pipeline processes inputs sequentially:
Text/visual input is processed through the text/visual components.
Safety checks are performed on the input.
The core model generates the video frames.
Post-processing safety checks and face blurring are applied.
The final video, meeting all quality and safety requirements, is produced.
Model Architecture for Cosmos-Transfer2.5-2B#
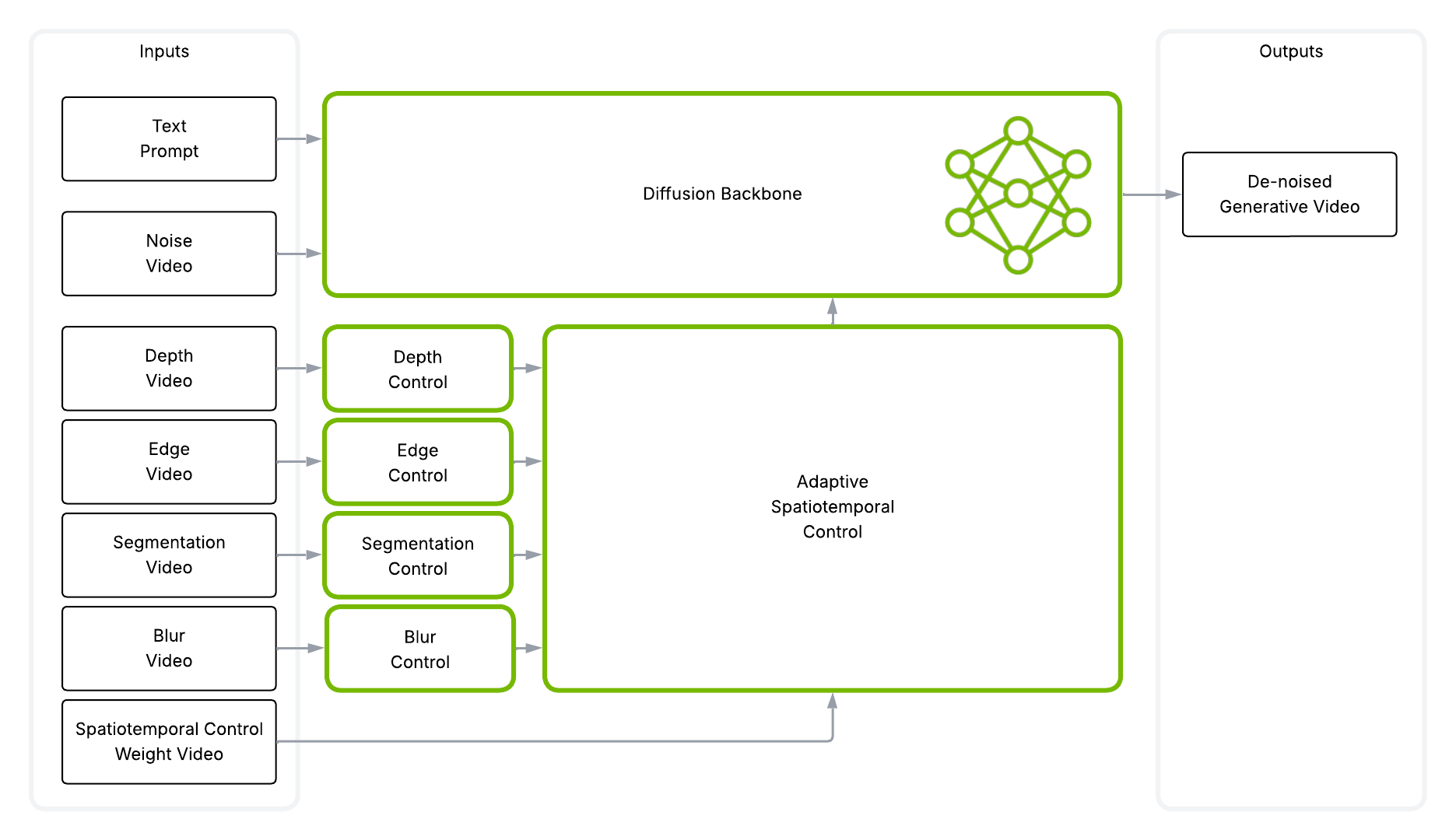
Cosmos-Transfer2.5-2B is a newer, more efficient model that builds upon the Cosmos-Transfer1 architecture with several key improvements:
Compact Architecture: Contains only 2B parameters, compared to 7B for Transfer1, offering significantly faster inference times while maintaining high-quality outputs.
Enhanced Control Modalities: Supports four primary control types:
edge: Edge detection control with adjustable threshold presets (“very_low”, “low”, “medium”, “high”, “very_high”) for fine-tuned edge sensitivity
depth: Depth estimation control for preserving 3D spatial structure
vis: Visual/blur control with preset blur strength options for maintaining scene aesthetics
seg: Segmentation control for structural consistency and style matching
Flexible Resolution Support: Supports multiple processing resolutions (256p, 480p, 512p, 720p). The output video resolution is determined by the input video resolution.
Conditional Frame Control: Allows specification of conditioning frames (0, 1, or 2) from the input video for better temporal consistency.
Simplified API: Provides streamlined parameter names (e.g.
guidanceinstead ofguidance_scaleandnum_stepsfor diffusion steps).
The Cosmos-Transfer2.5-2B model shares the same text processing pipeline and safety guardrails as other Cosmos models, ensuring consistent quality and safe outputs across the family.
Note
Transfer2.5-2B requires at least one control modality (edge, depth, vis, or seg) be specified in each inference request. This ensures the model has sufficient guidance for the video transformation process.
Model Architecture for Cosmos3-Generator#
Cosmos3 is a Mixture-of-Transformer (MoT) world foundation model with two cooperating towers that share latent representations and are trained jointly:
A Reasoner (vision-language) tower that grounds the prompt in the visual concept space.
A Generator (world simulator) tower that produces the video frames.
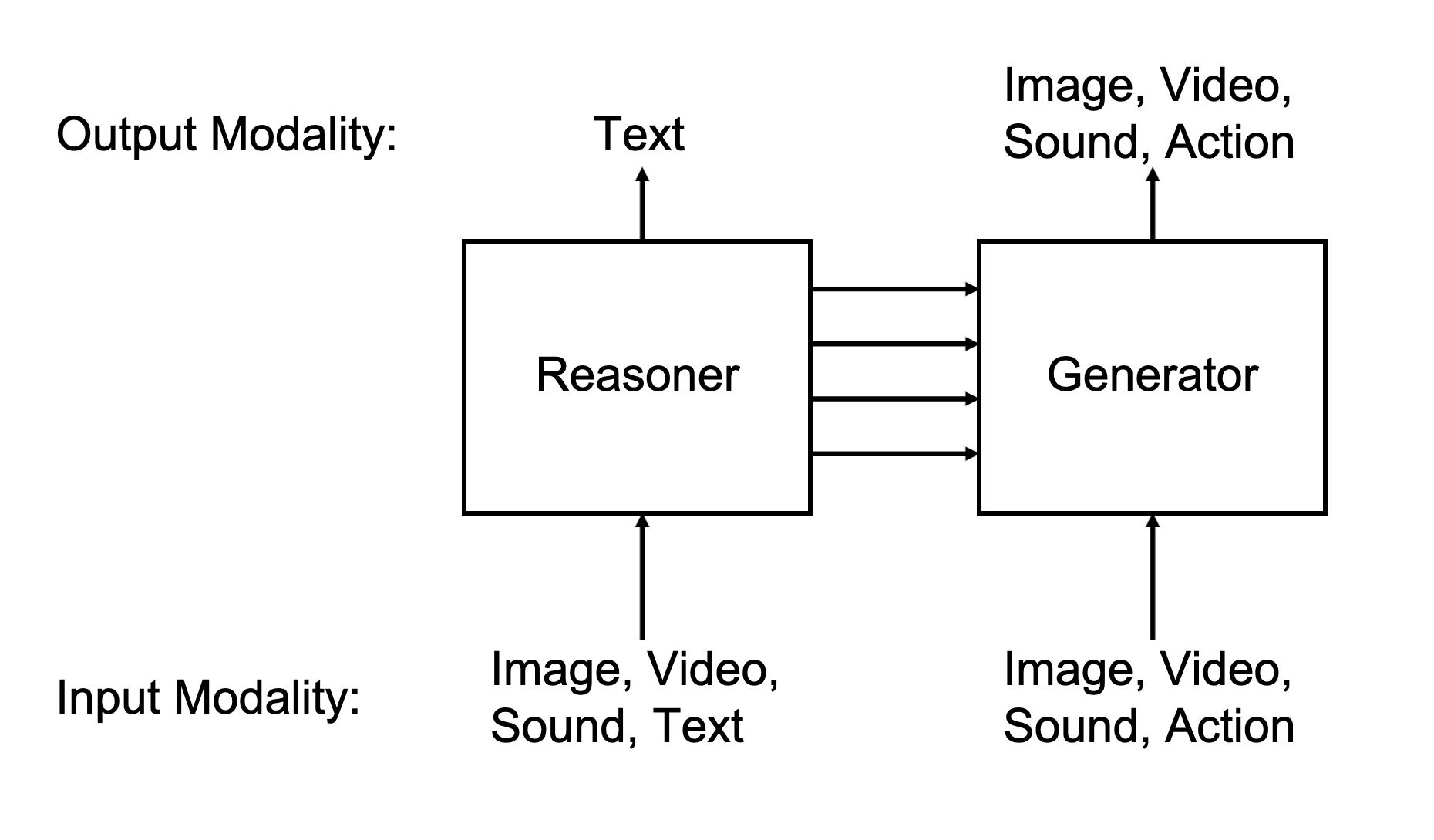
Mixture-of-Transformer architecture. Left tower: Reasoner (vision-language). Right tower: Generator (world simulator).
The Cosmos3-Generator NIM exposes the Generator path which uses Reasoner tower to understand the user input and Generator tower to generate the output modality such as video; the Reasoner path is exposed by the
separate Cosmos3-Reasoner NIM. The same Generator container image serves both the 8B (nano)
and 32B (super) model sizes — the active size is selected at boot via
NIM_MODEL_SIZE=nano|super. Both sizes expose the same HTTP API contract; only the supported
hardware profiles and the achievable quality / latency differ. See
Cosmos3-Generator for per-size hardware requirements.
Generation modes#
The active generation mode is inferred automatically from the request fields:
Mode |
Required inputs |
Description |
|---|---|---|
TEXT2VIDEO (T2V) |
Non-empty |
Generate a video from a text prompt only. |
IMAGE2VIDEO (I2V) |
|
Generate a video conditioned on a first frame. Provided image will be the first frame of the resulting video. |
Safety and Guardrail Components#
The guardrail system implements multiple layers of safety checks to ensure responsible AI usage:
Text Blocklist: Filters out prohibited words and phrases before processing.
Text Guardrail: Analyzes the semantic content of prompts to prevent unsafe or inappropriate generations.
Video Guardrail: Examines generated video frames to detect and filter out inappropriate content.
Face Blur: Detects and blurs faces in generated videos to protect privacy.
These guardrails are designed to prevent the generation of harmful, violent, or otherwise inappropriate content.
Note
If your request is unexpectedly rejected by the guardrails, consider rephrasing your prompt or adjusting your input content.
The NVIDIA Developer Program#
Want to learn more about NIMs? Join the NVIDIA Developer Program to get free access to self-hosting NVIDIA NIMs and microservices on up to 16 GPUs on any infrastructure-cloud, data center, or personal workstation.
Once you join the free NVIDIA Developer Program, you can access NIMs through the NVIDIA API Catalog at any time. For enterprise-grade security, support, and API stability, select the option to access NIM through our free 90-day NVIDIA AI Enterprise Trial with a business email address.
Refer to the NVIDIA NIM FAQ for additional information.