Introduction#
NVIDIA VILA NIM for Vision Language Models (VLMs), also known as NIM for VLMs, brings the power of state-of-the-art VLMs to enterprise applications, providing unmatched natural language and multimodal understanding capabilities.
NVIDIA NIMs make it easy for IT and DevOps teams to self-host vision language models (VLMs) in your managed environments while still providing developers with industry-standard APIs that enable building powerful copilots, chatbots, and AI assistants that can transform your business. Leveraging NVIDIA’s cutting-edge GPU acceleration and scalable deployment, NIMs offer the fastest path to inference with unparalleled performance.
NIM for VLMs models provide multi-image reasoning, in-context learning, visual chain-of-thought, and better world knowledge. This version of NIM for LLMs was trained on commercial images only for all three stages of training and supports single image inference.
High-Performance Features#
NIMs such as NIM for VLMs abstract away model inference internals such as execution engine and runtime operations. They are the most performant option available, whether with TRT-LLM, vLLM, or others. NIM for VLMs offers the following high-performance features:
Scalable Deployment that is performant and can quickly and seamlessly scale from a few users to millions.
Advanced Vision Language Model supports with pre-generated optimized engines for a diverse range of cutting-edge architectures.
AWQ TRT-LLM optimized quantization enables the VILA-34b model running on a single GPU, and gets the best performance meanwhile keep almost no accuracy drop with TRT-LLM AWQ quantization.
OpenAI API-compatibility to easily incorporate the microservice into existing workflows and applications. Developers are provided an OpenAI API-compatible programming model and custom NVIDIA extensions for additional functionality.
Enterprise-Grade Security emphasizes security by using safetensors, constantly monitoring and patching CVEs in our stack and conducting internal penetration tests.
Architecture#
NIMs are packaged as container images on a model/model family basis. Each NIM is its own Docker container with a model, such as “nvidia-vila “. These containers include a runtime that runs on any NVIDIA GPU with sufficient GPU memory, but some model/GPU combinations are optimized. NIMs automatically download the model from NGC, leveraging a local filesystem cache if available. Each NIM is built from a common base, so once a NIM has been downloaded, additional NIMs can be quickly downloaded.
When a NIM is first deployed, it inspects the local hardware configuration and the available model versions in the model registry and automatically chooses the best version of the model for the available hardware. For a subset of NVIDIA GPUs (see Support Matrix), NIMs download the optimized TRT engine and runs an inference using the TRT-LLM library. NIMs download a non-optimized model for all other NVIDIA GPUs and runs it using the vLLM library.
NIMs are distributed as NGC container images through the NVIDIA NGC Catalog. A security scan report is available for each container within the NGC catalog, which provides a security rating of that image, a breakdown of CVE severity by package, and links to detailed information on CVEs.
Use Cases#
Multimodal API visual assistants#
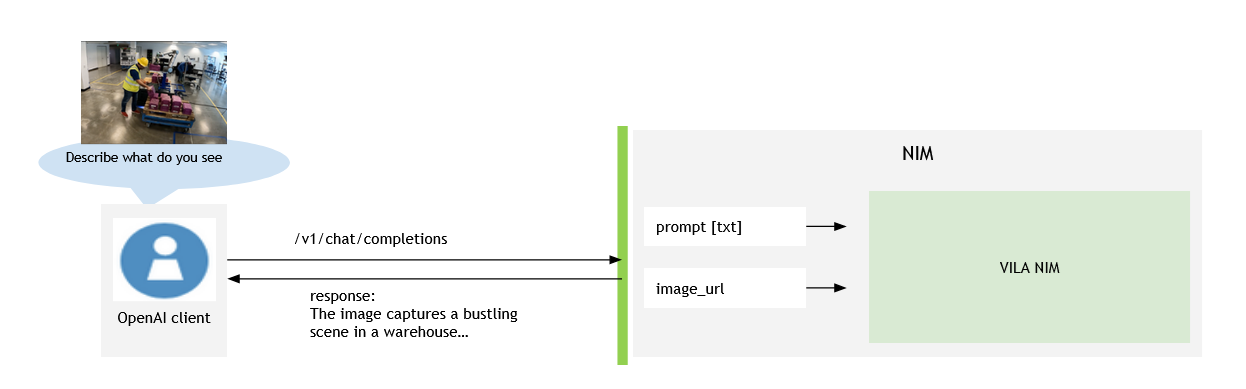
In a Multimodal visual assistant application, users can download the container and setup NIM for VLMs as an a OpenAI API-compatible assistant server. End users can use the OpenAI client SDK to ask questions, such as a summary, about a specific image. The following diagram depicts the NIM for VLMs client and server architecture.
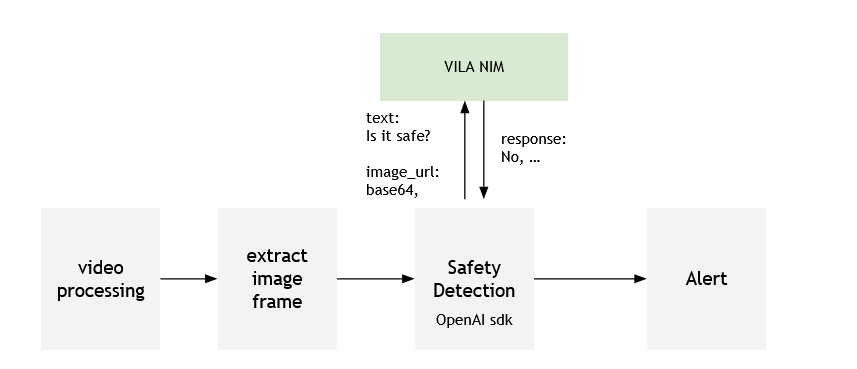
With the OpenAI API-compatible visual assistant server users can extend NIM for VLMs with other CV features into anomaly detection or safety alert in a workspace. For example, for the safety alert case in a warehouse or factory, customers with CV-based video processing can extract pictures, and send them to NIM for VLMs to detect whether the environment is safe. and based on that answer, whether to issue an alert.