Chart
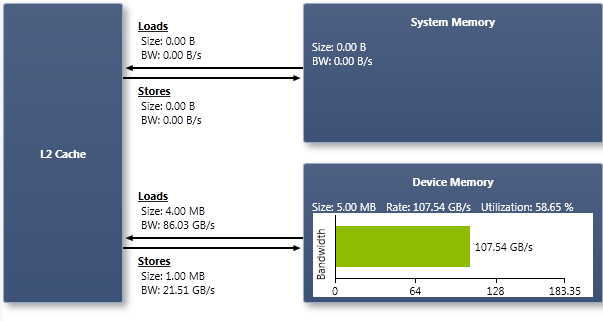
Buffers
All accesses to buffers from the GPU are routed through the L2 write-back cache. System memory can be accessed directly from a CUDA kernel using zero-copy, where the CUDA API is used to allocate system memory mapped into the CUDA device's address space. The Buffers chart shows the amount of data loaded and stored separately, and the sum of loads and stores in the System Memory and Device Memory regions, along with a percentage of overall bandwidth utilization.