Chart
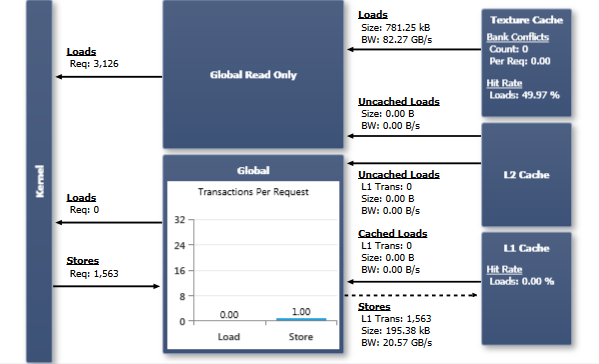
Global Read Only
Devices of compute capability 3.5 support reading global memory through the same cache used by the texture pipeline. As the texture cache offers very different coalescing rules over the data cache, using this memory path may improve performance - especially for highly non-uniform memory access patterns. For kernels that are limited by the memory bandwidth to and from the data cache, routing some traffic through the global read only data path can additionally benefit performance as the texture cache is a separate physical unit with a separate data path; however, note that the global read only memory accesses share the texture cache with any traffic generated through texture fetches.
If targeted for an applicable compute device, the compiler will automatically use global read only data accesses wherever suitable. Add the const __restrict__ type qualifiers for pointers to memory that qualify for global read only accesses or use the __ldg() intrinsic for explicit control. To verify which data path is used for individual memory accesses inspect the Source View page. Global read only memory accesses will show up as LDG instructions; global memory reads through the data cache are represented as LD instructions.
The chart layout depends on the architecture of the device. For first-generation Kepler devices that do not support the global read-only data path, the upper portion of the chart is greyed out. For Maxwell and Pascal devices, L1 and Tex caches are combined into a single unit. See the CUDA documentation for deeper explanations of the memory hierarchy, and how it differs across the various architectures.
Global
When a warp executes an instruction that accesses generic global memory (LD or ST assembly instructions), it coalesces the memory accesses of the threads within the warp into one or more of these memory transactions depending on the size of the word accessed by each thread and the distribution of the memory addresses across the threads. In general, the more transactions are necessary, the more unused words are transferred in addition to the words accessed by the threads, reducing the instruction throughput accordingly. In addition, each memory transaction requires the assembly instruction to be repeatedly issued again; causing instruction replays if more than one transaction is required to fulfill the request of a warp. More details on instruction replays and their performance implications are described in the context of the Instruction Statistics experiment.
The Transactions Per Request chart shows the average number of L1 transactions required per executed global memory instruction, separately for load and store operations. Lower numbers are better; the target for a single memory operation on a full warp is 1 transaction for a 4byte access, 2 transactions for a 8byte access, and 4 transactions for a 16byte access. How many transactions are actually required varies with the access pattern of the memory operation and is also dependent on the compute capability of the target device. The CUDA C Programming Guide provides detailed information on the coalescing rules for each compute architecture (Compute Capability 3.x, Compute Capability 5.x, Compute Capability 6.x).
