> For clean Markdown of any page, append .md to the page URL.
> For a complete documentation index, see https://docs.nvidia.com/nvcf/llms.txt.
> For full documentation content, see https://docs.nvidia.com/nvcf/llms-full.txt.
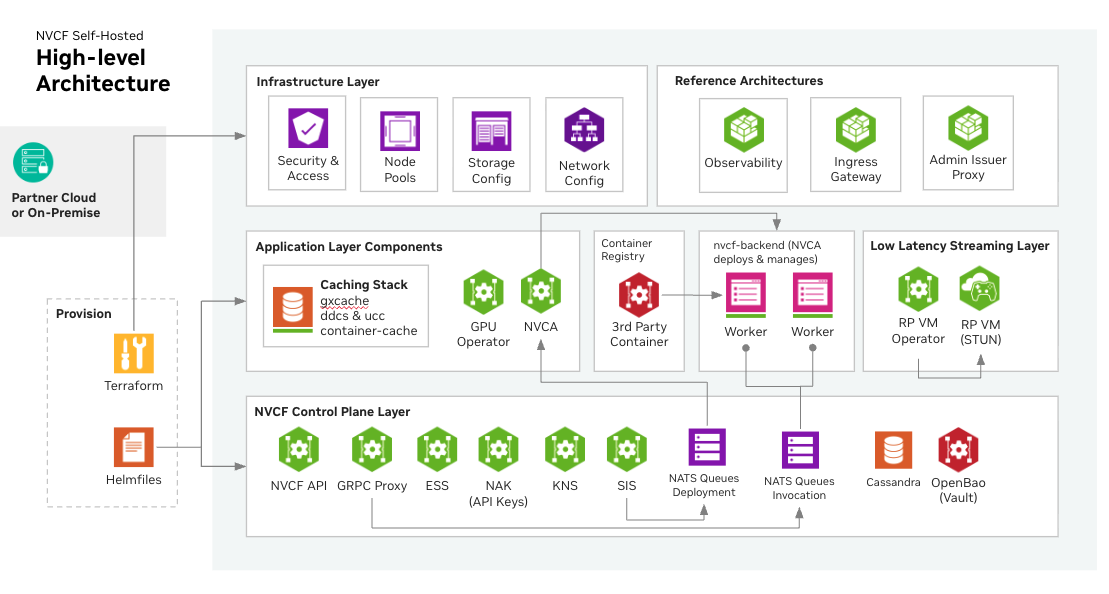
# Deployment
Self-hosted NVCF installation includes the core components required for NVCF inference. Additional optional components such as caching and low latency streaming support are also available.
For a full list of required artifacts, see [self-hosted-artifact-manifest](./manifest).
Want to try NVCF locally first? See [local-development](./local-development) for a guide to running
the full stack on your laptop using k3d.
## Overview
Installation steps are as follows:
1. **Mirror NVCF artifacts to your registry** — Choose your mirroring approach based on your deployment method:
- **Terraform with EKS/ECR (Recommended):** Use [Automated ECR Mirroring](./image-mirroring) by setting `create_sm_ecr_repos = true` in your Terraform configuration. This handles all image and Helm chart mirroring automatically.
- **All other deployments:** Follow the [manual mirroring instructions](./image-mirroring) to pull artifacts from NGC and push to your registry.
2. **Create a Kubernetes cluster** (Optional, can bring any existing Kubernetes cluster or create an EKS cluster from example Terraform, see [terraform-installation](./terraform-installation))
3. **Install NVCF Self-hosted Control Plane** (Required) — Choose your installation method:
- [helmfile-installation](./helmfile-installation) *(recommended)* — automated deployment using `helmfile`. **Use Helmfile < 1.2.0** (see [helmfile-installation](./helmfile-installation) prerequisites for details).
- [self-hosted-standalone-deployment](./standalone-deployment) — individual `helm install` commands, for fine-grained control or GitOps pipelines.
4. **Install Low Latency Streaming** (Optional, for streaming workloads, see [self-hosted-lls-installation](./lls-installation))
5. **Install Optional GPU Cluster Enhancements** (Optional, such as caching components, see [self-hosted-optional-enhancements](./optional-enhancements))
6. **Configure the NVIDIA Cluster Agent** (Optional, for GPU clusters that run functions; see [self-managed-clusters](./self-managed-clusters))
## Kubernetes Cluster Requirements
### Cluster Version
- Any official supported Kubernetes version
- Support for dynamic persistent volume provisioning
### Required Operators and Components
**NVIDIA GPU Operator**
Required for GPU workload scheduling. The GPU Operator automates the management of all NVIDIA software components needed to provision GPUs in Kubernetes, including:
- NVIDIA device drivers
- Kubernetes device plugin for GPU discovery
- GPU feature discovery for node labeling
- Container runtime integration (containerd, CRI-O, or Docker)
- Monitoring and telemetry tools
See [NVIDIA GPU Operator documentation](https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/) for installation instructions.
**Fake GPU Operator for Development/Testing:**
For environments without actual GPU hardware, install the fake GPU operator to simulate
GPU resources. See [fake-gpu-operator](./fake-gpu-operator) for full instructions.
**Network Policies**
Your cluster must support Kubernetes Network Policies if network isolation is required.
**Persistent Storage**
A StorageClass must be configured for persistent volumes. Common options:
- Amazon EKS: `gp3` (default)
- Local development: `local-path`
- Other platforms: Any CSI-compatible storage class
Some cloud providers have minimum PVC size requirements. For example, AWS EBS gp3 volumes have a 1Gi minimum.
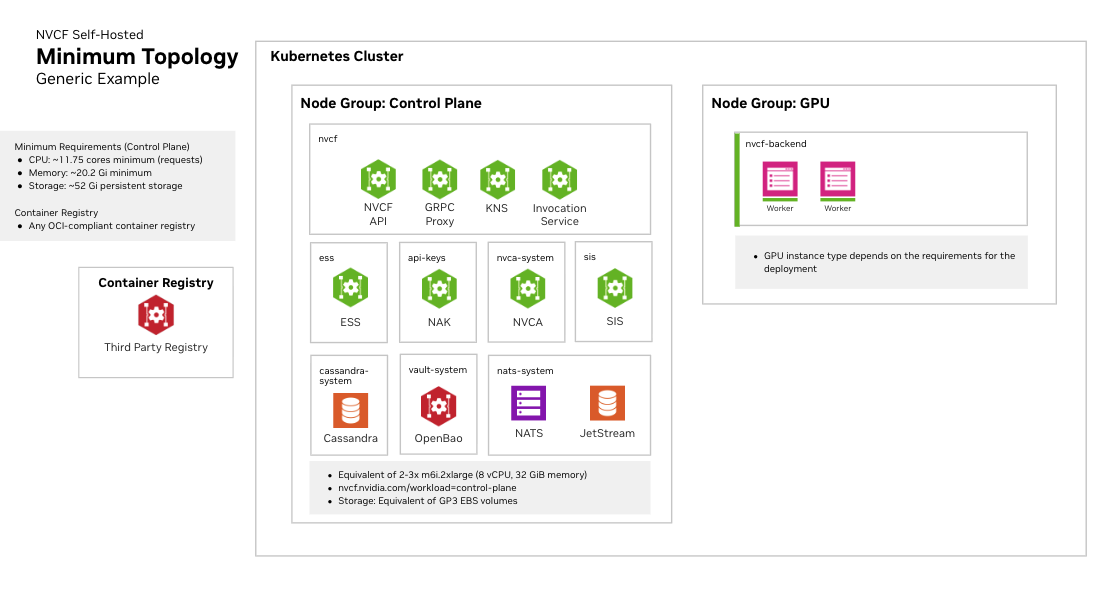
### Cluster Sizing and Storage
See [infrastructure-sizing](./infrastructure-sizing) for node pool specifications, storage
recommendations, and three recommended sizing tiers (Development, Minimal HA,
and Production).