NVIDIA HPCG Benchmark#
x86 package folder structure#
hpcg.sh script in the root directory of the package to invoke the xhpcg executable.
NVIDIA HPCG benchmark in the folder ./hpcg-linux-x86_64 contains:
xhpcgexecutableSamples of Slurm batch-job scripts in sample-slurm directory
Samples of input files in sample-dat directory
README, RUNNING, and TUNING guides
aarch64 package folder structure#
hpcg-aarch64.sh script in the root directory of the package to invoke the xhpcg executable for NVIDIA Grace CPU.
NVIDIA HPCG Benchmark in the folder
./hpcg-linux-aarch64contains:xhpcgexecutable for NVIDIA Grace Hopper and NVIDIA Grace Blackwellxhpcg-cpuexecutable for NVIDIA Grace CPUSamples of Slurm batch-job scripts in sample-slurm directory
Sample input file in sample-dat directory
README, RUNNING, and TUNING guides
Running the NVIDIA HPCG Benchmarks on x86_64 with NVIDIA GPUs#
The NVIDIA HPCG Benchmark uses the same input format as the standard HPCG Benchmark. Please see the HPCG Benchmark for getting started with the HPCG software concepts and best practices.
The script hpcg.sh can be invoked on a command line or through a Slurm batch-script to launch the NVIDIA HPCG Benchmarks.
The script hpcg.sh accepts the following parameters:
--dat <string>path to hpcg.dat (Required)
--cuda-compatmanually enable CUDA forward compatibility (Optional)
--no-multinodeenable flags for no-multinode (no-network) execution (Optional)
--gpu-affinity <string>colon separated list of gpu indices (Optional)
--cpu-affinity <string>colon separated list of cpu index ranges (Optional)
--mem-affinity <string>colon separated list of memory indices (Optional)
--ucx-affinity <string>colon separated list of UCX devices (Optional)
--ucx-tls <string>UCX transport to use (Optional)
--exec-name <string>HPL executable file (Optional)
In addition, the script hpcg.sh alternatively to input file accepts the following parameters:
--nxspecifies the local (to an MPI process) X dimensions of the problem
--nyspecifies the local (to an MPI process) Y dimensions of the problem
--nzspecifies the local (to an MPI process) Z dimensions of the problem
--rtspecifies the number of seconds of how long the timed portion of the benchmark should run
--bactivates benchmarking mode to bypass CPU reference execution when set to one (–b 1)
--l2cmpactivates compression in GPU L2 cache when set to one (–l2cmp 1)
--ofactivates generating the log into textfiles, instead of console (–of=1)
--gssspecifies the slice size for the GPU rank (default is 4096)
--p2pspecifies the p2p comm mode: 0 MPI_CPU, 1 MPI_CPU_All2allv, 2 MPI_CUDA_AWARE, 3 MPI_CUDA_AWARE_All2allv, 4 NCCL. Default MPI_CPU
--npxspecifies the process grid X dimension of the problem
--npyspecifies the process grid Y dimension of the problem
--npzspecifies the process grid Z dimension of the problem
Notes:
Affinity example:
DGX-H100 and DGX-B200:
--mem-affinity 0:0:0:0:1:1:1:1 --cpu-affinity 0-13:14-27:28-41:42-55:56-69:70-83:84-97:98-111DGX-A100:
--mem-affinity 2:3:0:1:6:7:4:5 --cpu-affinity 32-47:48-63:0-15:16-31:96-111:112-127:64-79:80-95The NVIDIA HPCG benchmark requires one GPU per MPI process. Therefore, ensure that the number of MPI processes is set to match the number of available GPUs in the cluster.
- Multi-Instance GPU (MIG) technology can help improve HPCG benchmark performance on Nvidia Blackwell with dual-die design.
Use MIG to partition the Blackwell GPU into two instances. These two instances can be treated as stand-alone GPUs.
The following example shows a template script to run HPCG on a single DGX Blackwell node with 8 GPUs, partitioned into 16 MIG intances.
# Note: sudo access is needed to configure MIG # Activate MIG on each GPU and partition each GPU into two instances for i in {0..7} do sudo nvidia-smi -i $i -mig 1 sudo nvidia-smi mig -i $i -cgi 9,9 -C done # Make the 16 instances visible export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 #Run HPCG with 16 GPUs/node ... # Deactivate MIG and instances for i in {0..7} do sudo nvidia-smi mig -i $i -dci sudo nvidia-smi mig -i $i -dgi sudo nvidia-smi -i $i -mig 0 done
Examples:
Run NVIDIA HPCG on nodes 16 with 4 GPUs (or 8 nodes with 8 GPUs) using script parameters on x86:
srun -N 16 --ntasks-per-node=4 --cpu-bind=none --mpi=pmix \ ./hpcg.sh --nx 256 --ny 256 --nz 256 --rt 2
Running the NVIDIA HPCG Benchmarks on NVIDIA Grace Hopper, NVIDIA Grace Blackwell, and NVIDIA Grace CPU systems#
The NVIDIA HPCG Benchmark uses the same input format as the standard HPCG Benchmark. Please see the HPCG Benchmark for getting started with the HPCG software concepts and best practices.
NVIDIA HPCG Benchmark supports CPU-only, GPU-only and heterogeneous execution modes
The script hpcg-aarch64.sh can be invoked on a command line or through a Slurm batch-script to launch the NVIDIA HPCG Benchmarks.
The script hpcg-aarch64.sh accepts the following parameters:
--dat <string>path to HPL.dat (Required)
--cuda-compatmanually enable CUDA forward compatibility (Optional)
--no-multinodeenable flags for no-multinode (no-network) execution (Optional)
--gpu-affinity <string>colon separated list of gpu indices (Optional)
--cpu-affinity <string>colon separated list of cpu index ranges (Optional)
--mem-affinity <string>colon separated list of memory indices (Optional)
--ucx-affinity <string>colon separated list of UCX devices (Optional)
--ucx-tls <string>UCX transport to use (Optional)
--exec-name <string>HPL executable file (Optional)
In addition, instead of an input file, the script hpcg-aarch64.sh`` accepts the following parameters:
--nxspecifies the local (to an MPI process) X dimensions of the problem
--nyspecifies the local (to an MPI process) Y dimensions of the problem
--nzspecifies the local (to an MPI process) Z dimensions of the problem
--rtspecifies the number of seconds of how long the timed portion of the benchmark should run
--bactivates benchmarking mode to bypass CPU reference execution when set to one (–b=1)
--l2cmpactivates compression in GPU L2 cache when set to one (–l2cmp=1)
--ofactivates generating the log into textfiles, instead of console (–of=1)
--gssspecifies the slice size for the GPU rank (default is 4096)
--cssspecifies the slice size for the CPU rank (default is 8)
--p2pspecifies the p2p comm mode: 0 MPI_CPU, 1 MPI_CPU_All2allv, 2 MPI_CUDA_AWARE, 3 MPI_CUDA_AWARE_All2allv, 4 NCCL. Default MPI_CPU
The following parameters controls the NVIDIA HPCG benchmark on NVIDIA Grace Hopper and NVIDIA Grace Blackwell systems:
--exmspecifies the execution mode. 0 is GPU-only, 1 is Grace-only, and 2 is heterogeneous. Default is 0
--ddmspecifies the direction that GPU and Grace will not have the same local dimension. 0 is auto, 1 is X, 2 is Y, and 3 is Z. Default is 0. Note that the GPU and Grace local problems can differ in one dimension only
--g2cspecifies the value of different dimensions of the GPU and Grace local problems. Depends on--ddmand--lpmvalues
--lpmcontrols the meaning of the value provided for--g2cparameter. Applicable when--exmis 2 and depends on the different local dimension specified by--ddmValue Explanation:
0 means nx/ny/nz are GPU local dims and g2c value is the ratio of GPU dim to Grace dim. For example,
--nx 128 --ny 128 --nz 128 --ddm 2 --g2c 8means the different Grace dim (Y in this example) is 1/8 the different GPU dim. GPU local problem is 128x128x128 and Grace local problem is 128x16x1281 means nx/ny/nz are GPU local dims and g2c value is the absolute value for the different dim for Grace. For example,
--nx 128 --ny 128 --nz 128 --ddm 3 --g2c 64``means the different Grace dim (Z in this example) is 64. GPU local problem is 128x128x128 and Grace local problem is 128x128x642 assumes a local problem formed by combining a GPU and a Grace problems. The value 2 means the sum of the different dims of the GPU and Grace is combined in the different dimension value.
--g2c``is the ratio. For example,--ddm 1 --nx 1024 --g2c 8, then GPU X dim is 896 and Grace X dim is 1283 assumes a local problem formed by combining a GPU and a Grace problems. The value 3 means the sum of the different dims of the GPU and Grace is combined in the different dimension value.
--g2cis absolute. For example,--ddm 1 --nx 1024 --g2c 96then GPU X dim is 928 and Grace X dim is 96
Optional parameters of hpcg-aarch64.sh script:
--npxspecifies the process grid X dimension of the problem
--npyspecifies the process grid Y dimension of the problem
--npzspecifies the process grid Z dimension of the problem
Heterogenous (GPU-GRACE) execution mode in-depth#
The NVIDIA HPCG benchmark can run efficiently on heterogeneous systems comprising GPUs and Grace CPUs like NVIDIA Grace Hopper and NVIDIA Grace Blackwell. The approach involves assigning an MPI rank to each GPU and one or more MPI ranks to the Grace CPU. Given that the GPU performs significantly faster than the Grace CPU, the strategy is to allocate a larger local problem size to the GPU compared to the Grace CPU. This ensures that during MPI blocking communication steps like MPI_Allreduce, the GPU’s execution is not interrupted by the Grace CPU’s slower execution.
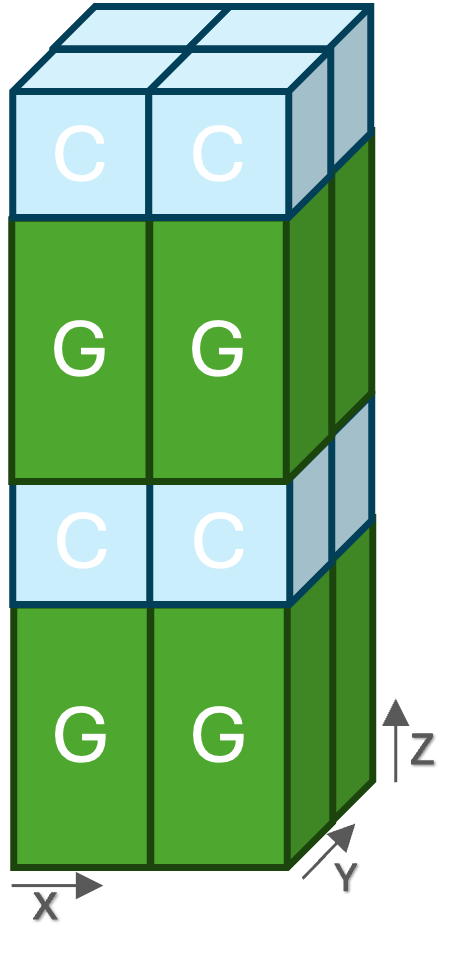
In the NVIDIA HPCG benchmark, the GPU and Grace local problems are configured to differ in only one dimension while keeping the other dimensions identical. This design enables proper halo exchange operations across the dimensions that remain identical between the GPU and Grace ranks. The image below depicts an example of this design. The GPU and Grace ranks have the same x and y dimensions, where the halo exchange takes place. The z dimension is different which enables assigning different local problems for the GPU and Grace ranks. The NVIDIA HPCG benchmark has the flexibility to choose the 3D shape of ranks choose the different dimension, and configure the sizes of GPU and Grace ranks.
Notes:
The NVIDIA HPCG benchmark requires one GPU per MPI process. Therefore, ensure that the number of MPI processes is set to match the number of available GPUs in the cluster.
It is recommended to bind MPI process to NUMA node on NVIDIA Grace CPU, for example:
./hpl-aarch64.sh --dat /my-dat-files/HPL.dat --cpu-affinity 0-71:72-143 --mem-affinity 0:1
Examples:
Run NVIDIA HPCG on two nodes of NVIDIA Grace CPU using custom parameters:
srun -N 2 --ntasks-per-node=4 --cpu-bind=none --mpi=pmix \ ./hpcg-aarch64.sh --exm 1 --nx 512 --ny 512 --nz 288 --rt 30 --cpu-affinity 0-35:36-71:72-107:108-143 --mem-affinity 0:0:1:1Run NVIDIA HPCG on two nodes NVIDIA Grace Hopper x4:
#GPU+Grace (Heterogeneous execution) #GPU rank has 8 OpenMP threads and Grace rank has 64 OpenMP threads srun -N 2 --ntasks-per-node=8 --cpu-bind=none --mpi=pmix \ ./hpcg-aarch64.sh --nx 256 --ny 1024 --nz 288 --rt 2 \ --exm 2 --ddm 2 --lpm 1 --g2c 64 \ --npx 4 --npy 4 --npz 1 \ --cpu-affinity 0-7:8-71:72-79:80-143:144-151:152-215:216-223:224-287 \ --mem-affinity 0:0:1:1:2:2:3:3where
--cpu-affinityis mapping to cores on the local node and--mem-affinityis mapping to NUMA-nodes on the local node.