Collective Communication¶
Collective routines are defined as coordinated communication or synchronization operations performed by a group of PEs.
NVSHMEM provides the following types of collective routines:
- Collective routines that operate on active sets use a set of parameters to determine which PEs will participate and what resources are used to perform operations.
- Collective routines that accept no active set parameters implicitly operate on all PEs.
Concurrent accesses to symmetric memory by an NVSHMEM collective routine and any other means of access—where at least one updates the symmetric memory—results in undefined behavior. Since PEs can enter and exit collectives at different times, accessing such memory remotely may require additional synchronization.
Active-set-based collectives¶
The active-set-based collective routines require all PEs in the active set to simultaneously call the routine. A PE that is not in the active set calling the collective routine results in undefined behavior.
The active set is defined by the arguments PE_start, logPE_stride,
and PE_size. PE_start specifies the starting PE number and is the
lowest numbered PE in the active set. The stride between successive PEs
in the active set is 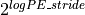 and logPE_stride must
be greater than or equal to zero. PE_size specifies the number of PEs
in the active set and must be greater than zero. The active set must
satisfy the requirement that its last member corresponds to a valid PE
number, that is
and logPE_stride must
be greater than or equal to zero. PE_size specifies the number of PEs
in the active set and must be greater than zero. The active set must
satisfy the requirement that its last member corresponds to a valid PE
number, that is
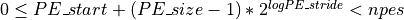 .
.
All PEs participating in the active-set-based collective routine must provide the same values for these arguments. If any of these requirements are not met, the behavior is undefined.
Another argument important to active-set-based collective routines is pSync, which is a symmetric work array. All PEs participating in an active-set-based collective must pass the same pSync array. Every element of the pSync array must be initialized to NVSHMEM_SYNC_VALUE before it is used as an argument to any active-set-based collective routine. On completion of such a collective call, the pSync is restored to its original contents. The user is permitted to reuse a pSync array if all previous collective routines using the pSync array have completed on all participating PEs. One can use a synchronization collective routine such as nvshmem_barrier to ensure completion of previous active-set-based collective routines. The nvshmem_barrier and shmem_sync routines allow the same pSync array to be used on consecutive calls as long as the PEs in the active set do not change.
All collective routines defined by NVSHMEM are blocking. The collective routines return on completion. The active-set-based collective routines defined by NVSHMEM are:
- nvshmem_barrier
- nvshmem_sync
- nvshmem_alltoall{32, 64}
- nvshmem_broadcast{32, 64}
- nvshmem_collect{32, 64}
- nvshmem_TYPENAME_{and, or, xor, max, min, sum, prod}_to_all
Implicit active set collectives¶
Some NVSHMEM collective routines implicitly operate on all PEs. These routines include:
- nvshmem_sync_all, which synchronizes all PEs in the computation.
- nvshmem_barrier_all, which synchronizes all PEs in the computation and ensures completion of all local and remote memory updates.
- NVSHMEM memory-management routines, which imply one or more calls to a routine equivalent to nvshmem_barrier_all.
NVSHMEM_BARRIER_ALL¶
-
void
nvshmem_barrier_all(void)¶
-
void
nvshmemx_barrier_all_on_stream(void, cudaStream_t stream)¶
-
__device__ void
nvshmem_barrier_all(void)
-
__device__ void
nvshmemx_barrier_all_block(void)¶
-
__device__ void
nvshmemx_barrier_all_warp(void)¶
Description
The nvshmem_barrier_all routine is a mechanism for synchronizing all PEs at once. This routine blocks the calling PE until all PEs have called nvshmem_barrier_all. In a multithreaded NVSHMEM program, only the calling thread is blocked, however, it may not be called concurrently by multiple threads in the same PE.
Prior to synchronizing with other PEs, nvshmem_barrier_all ensures completion of all previously issued memory stores and remote memory updates issued NVSHMEMAMOs and RMA routine calls such as nvshmem_int_add, shmem_put32, nvshmem_put_nbi, and shmem_get_nbi.
Returns
None.
Notes
The nvshmem_barrier_all routine can be used to portably ensure that memory access operations observe remote updates in the order enforced by initiator PEs.
Ordering APIs (nvshmem_fence, nvshmem_quiet, nvshmem_barrier, and nvshmem_barrier_all) issued on the CPU and the GPU only order communication operations that were issued from the CPU and the GPU, respectively. To ensure completion of GPU-side operations from the CPU, the developer must ensure completion of the CUDA kernel from which the GPU-side operations were issued, using operations like cudaStreamSynchronize or cudaDeviceSynchronize. Stream-based quiet or barrier operations have the effect of a barrier being executed on the GPU in stream order, ensuring completion and ordering of only GPU-side operations.
NVSHMEM_BARRIER¶
-
void
nvshmem_barrier(int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
void
nvshmemx_barrier_on_stream(int PE_start, int logPE_stride, int PE_size, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_barrier(int PE_start, int logPE_stride, int PE_size, long *pSync)
-
__device__ void
nvshmemx_barrier_block(int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
__device__ void
nvshmemx_barrier_warp(int PE_start, int logPE_stride, int PE_size, long *pSync)¶
- PE_start [IN]
- The lowest PE number of the active set of PEs.
- logPE_stride [IN]
- The log (base 2) of the stride between consecutive PE numbers in the active set.
- PE_size [IN]
- The number of PEs in the active set.
- pSync [IN]
- Symmetric address of a work array of size at least NVSHMEM_BARRIER_SYNC_SIZE.
Description
nvshmem_barrier is a collective synchronization routine over an active set. Control returns from nvshmem_barrier after all PEs in the active set (specified by PE_start, logPE_stride, and PE_size) have called nvshmem_barrier.
As with all NVSHMEM collective routines, each of these routines assumes that only PEs in the active set call the routine. If a PE not in the active set calls an NVSHMEM collective routine, the behavior is undefined.
The values of arguments PE_start, logPE_stride, and PE_size must be the same value on all PEs in the active set. The same work array must be passed in pSync to all PEs in the active set.
nvshmem_barrier ensures that all previously issued stores and remote memory updates, including AMOs and RMA operations, done by any of the PEs in the active set are complete before returning.
The same pSync array may be reused on consecutive calls to nvshmem_barrier if the same active set is used.
Returns
None.
Notes
The nvshmem_barrier routine can be used to portably ensure that memory access operations observe remote updates in the order enforced by initiator PEs.
Ordering APIs (nvshmem_fence, nvshmem_quiet, nvshmem_barrier, and nvshmem_barrier_all) issued on the CPU and the GPU only order communication operations that were issued from the CPU and the GPU, respectively. To ensure completion of GPU-side operations from the CPU, the developer must ensure completion of the CUDA kernel from which the GPU-side operations were issued, using operations like cudaStreamSynchronize or cudaDeviceSynchronize. Stream-based quiet or barrier operations have the effect of a barrier being executed on the GPU in stream order, ensuring completion and ordering of only GPU-side operations.
NVSHMEM_SYNC¶
-
void
nvshmem_sync(int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
void
nvshmemx_sync_on_stream(int PE_start, int logPE_stride, int PE_size, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_sync(int PE_start, int logPE_stride, int PE_size, long *pSync)
-
__device__ void
nvshmemx_sync_block(int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
__device__ void
nvshmemx_sync_warp(int PE_start, int logPE_stride, int PE_size, long *pSync)¶
The lowest PE number of the active set of PEs.
The log (base 2) of the stride between consecutive PE numbers in the active set.
The number of PEs in the active set.
Symmetric address of a work array of size at least NVSHMEM_SYNC_SIZE.
Description
nvshmem_sync is a collective synchronization routine over an active set.
The routine registers the arrival of a PE at a synchronization point in the program. This is a fast mechanism for synchronizing all PEs that participate in this collective call. The routine blocks the calling PE until all PEs in the specified active set have called nvshmem_sync. In a multithreaded NVSHMEM program, only the calling thread is blocked.
Active-set-based sync routines operate over all PEs in the active set defined by the PE_start, logPE_stride, PE_size triplet.
As with all active set-based collective routines, each of these routines assumes that only PEs in the active set call the routine. If a PE not in the active set calls an active set-based collective routine, the behavior is undefined.
The values of arguments PE_start, logPE_stride, and PE_size must be equal on all PEs in the active set. The same work array must be passed in pSync to all PEs in the active set.
In contrast with the nvshmem_barrier routine, shmem_sync only ensures completion and visibility of previously issued memory stores and does not ensure completion of remote memory updates issued via NVSHMEM routines.
The same pSync array may be reused on consecutive calls to nvshmem_sync if the same active set is used.
Returns
Zero on successful local completion. Nonzero otherwise.
Notes
The nvshmem_sync routine can be used to portably ensure that memory access operations observe remote updates in the order enforced by the initiator PEs, provided that the initiator PE ensures completion of remote updates with a call to nvshmem_quiet prior to the call to the nvshmem_sync routine.
NVSHMEM_SYNC_ALL¶
-
void
nvshmem_sync_all(void)¶
-
void
nvshmemx_sync_all_on_stream(void, cudaStream_t stream)¶
-
__device__ void
nvshmem_sync_all(void)
-
__device__ void
nvshmemx_sync_all_block(void)¶
-
__device__ void
nvshmemx_sync_all_warp(void)¶
Description
This routine blocks the calling PE until all PEs in the world team have called nvshmem_sync_all.
In a multithreaded NVSHMEM program, only the calling thread is blocked.
In contrast with the nvshmem_barrier_all routine, nvshmem_sync_all only ensures completion and visibility of previously issued memory stores and does not ensure completion of remote memory updates issued via NVSHMEM routines.
Returns
None.
Notes
The nvshmem_sync_all routine is equivalent to calling nvshmem_team_sync on the world team.
NVSHMEM_ALLTOALL¶
-
void
nvshmem_alltoall32(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
void
nvshmemx_alltoall32_on_stream(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_alltoall32(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)
-
__device__ void
nvshmemx_alltoall32_block(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
__device__ void
nvshmemx_alltoall32_warp(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
void
nvshmem_alltoall64(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
void
nvshmemx_alltoall64_on_stream(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_alltoall64(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)
-
__device__ void
nvshmemx_alltoall64_block(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
__device__ void
nvshmemx_alltoall64_warp(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
- dest [OUT]
- Symmetric address of a data object large enough to receive the combined total of nelems elements from each PE in the active set. The type of dest should match that implied in the SYNOPSIS section.
- source [IN]
- Symmetric address of a data object that contains nelems elements of data for each PE in the active set, ordered according to destination PE. The type of source should match that implied in the SYNOPSIS section.
- nelems [IN]
- The number of elements to exchange for each PE. For nvshmem_alltoallmem, elements are bytes; for nvshmem_alltoall{32,64}, elements are 4 or 8 bytes, respectively.
Description
The nvshmem_alltoall routines are collective routines. Each PE participating in the operation exchanges nelems data elements with all other PEs participating in the operation. The size of a data element is:
- 32 bits for nvshmem_alltoall32
- 64 bits for nvshmem_alltoall64
The data being sent and received are stored in a contiguous symmetric data object. The total size of each PE’s source object and dest object is nelems times the size of an element times N, where N equals the number of PEs participating in the operation. The source object contains N blocks of data (where the size of each block is defined by nelems) and each block of data is sent to a different PE.
The same dest and source arrays, and same value for nelems must be passed by all PEs that participate in the collective.
Given a PE i that is the 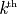 PE
participating in the operation and a PE j that is the
PE
participating in the operation and a PE j that is the
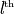 PE participating in the
operation,
PE participating in the
operation,
PE i sends the block of its
source object to the block of
the dest object of PE j.
Active-set-based collective routines operate over all PEs in the active set defined by the PE_start, logPE_stride, PE_size triplet.
As with all active-set-based collective routines, this routine assumes that only PEs in the active set call the routine. If a PE not in the active set calls an active-set-based collective routine, the behavior is undefined.
The values of arguments PE_start, logPE_stride, and PE_size must be equal on all PEs in the active set. The same pSync work array must be passed to all PEs in the active set.
Before any PE calls a nvshmem_alltoall routine, the following conditions must be ensured:
- The dest data object on all PEs in the active set is ready to accept the nvshmem_alltoall data.
- For active-set-based routines, the pSync array on all PEs in the active set is not still in use from a prior call to a nvshmem_alltoall routine.
Otherwise, the behavior is undefined.
Upon return from a nvshmem_alltoall routine, the following is true for the local PE:
- Its dest symmetric data object is completely updated and the data has been copied out of the source data object.
- For active-set-based routines, the values in the pSync array are restored to the original values.
Returns
Zero on successful local completion. Nonzero otherwise.
NVSHMEM_BROADCAST¶
-
void
nvshmem_broadcast32(void *dest, const void *source, size_t nelems, int PE_root, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
void
nvshmemx_broadcast32_on_stream(void *dest, const void *source, size_t nelems, int PE_root, int PE_start, int logPE_stride, int PE_size, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_broadcast32(void *dest, const void *source, size_t nelems, int PE_root, int PE_start, int logPE_stride, int PE_size, long *pSync)
-
__device__ void
nvshmemx_broadcast32_block(void *dest, const void *source, size_t nelems, int PE_root, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
__device__ void
nvshmemx_broadcast32_warp(void *dest, const void *source, size_t nelems, int PE_root, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
void
nvshmem_broadcast64(void *dest, const void *source, size_t nelems, int PE_root, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
void
nvshmemx_broadcast64_on_stream(void *dest, const void *source, size_t nelems, int PE_root, int PE_start, int logPE_stride, int PE_size, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_broadcast64(void *dest, const void *source, size_t nelems, int PE_root, int PE_start, int logPE_stride, int PE_size, long *pSync)
-
__device__ void
nvshmemx_broadcast64_block(void *dest, const void *source, size_t nelems, int PE_root, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
__device__ void
nvshmemx_broadcast64_warp(void *dest, const void *source, size_t nelems, int PE_root, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
- dest [OUT]
- Symmetric address of destination data object. The type of dest should match that implied in the SYNOPSIS section.
- source [IN]
- Symmetric address of the source data object. The type of source should match that implied in the SYNOPSIS section.
- nelems [IN]
- The number of elements in source and dest arrays. For nvshmem_broadcastmem, elements are bytes; for nvshmem_broadcast{32,64}, elements are 4 or 8 bytes, respectively.
- PE_root [IN]
- Zero-based ordinal of the PE, with respect to the active set, from which the data is copied.
Description
NVSHMEM broadcast routines are collective routines over an active set. They copy the source data object on the PE specified by PE_root to the dest data object on the PEs participating in the collective operation. The same dest and source data objects and the same value of PE_root must be passed by all PEs participating in the collective operation.
For active-set-based broadcasts:
- The dest object is updated on all PEs other than the root PE.
- All PEs in the active set defined by the PE_start, logPE_stride, PE_size triplet must participate in the operation.
- Only PEs in the active set may call the routine. If a PE not in the active set calls an active-set-based collective routine, the behavior is undefined.
- The values of arguments PE_root, PE_start, logPE_stride, and PE_size must be the same value on all PEs in the active set.
- The value of PE_root must be between 0 and PE_size :math:`-` 1.
- The same pSync work array must be passed by all PEs in the active set.
Before any PE calls a broadcast routine, the following conditions must be ensured:
- The dest array on all PEs participating in the broadcast is ready to accept the broadcast data.
- For active-set-based broadcasts, the pSync array on all PEs in the active set is not still in use from a prior call to an NVSHMEM collective routine.
Otherwise, the behavior is undefined.
Upon return from a broadcast routine, the following are true for the local PE:
- For active-set-based broadcasts:
- If the current PE is not the root PE, the dest data object is updated.
- The values in the pSync array are restored to the original values.
- The source data object may be safely reused.
Returns
For active-set-based broadcasts, none.
Notes
Team handle error checking and integer return codes are currently undefined. Implementations may define these behaviors as needed, but programs should ensure portability by doing their own checks for invalid team handles and for NVSHMEM_TEAM_INVALID.
NVSHMEM_COLLECT¶
-
void
nvshmem_collect32(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
void
nvshmemx_collect32_on_stream(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_collect32(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)
-
__device__ void
nvshmemx_collect32_block(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
__device__ void
nvshmemx_collect32_warp(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
void
nvshmem_collect64(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
void
nvshmemx_collect64_on_stream(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_collect64(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)
-
__device__ void
nvshmemx_collect64_block(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
-
__device__ void
nvshmemx_collect64_warp(void *dest, const void *source, size_t nelems, int PE_start, int logPE_stride, int PE_size, long *pSync)¶
- dest [OUT]
- Symmetric address of an array large enough to accept the concatenation of the source arrays on all participating PEs. The type of dest should match that implied in the SYNOPSIS section.
- source [IN]
- Symmetric address of the source data object. The type of source should match that implied in the SYNOPSIS section.
- nelems [IN]
- The number of elements in source array. For nvshmem_[f]collectmem, elements are bytes; for nvshmem_[f]collect{32,64}, elements are 4 or 8 bytes, respectively.
Description
NVSHMEMcollect routines perform a collective operation to concatenate nelems data items from the source array into the dest array, over an active set in processor number order. The resultant dest array contains the contribution from PEs as follows:
- For an active set, the data from PE PE_start is first, then the contribution from PE PE_start + PE_stride second, and so on.
The collected result is written to the dest array for all PEs that participate in the operation. The same dest and source arrays must be passed by all PEs that participate in the operation.
The collect routines allow nelems to vary from PE to PE.
Active-set-based collective routines operate over all PEs in the active set defined by the PE_start, logPE_stride, PE_size triplet. As with all active-set-based collective routines, each of these routines assumes that only PEs in the active set call the routine. If a PE not in the active set and calls this collective routine, the behavior is undefined.
The values of arguments PE_start, logPE_stride, and PE_size must be the same value on all PEs in the active set. The same pSync work array must be passed by all PEs in the active set.
Upon return from a collective routine, the following are true for the local PE:
- The dest array is updated and the source array may be safely reused.
- For active-set-based collective routines, the values in the pSync array are restored to the original values.
Returns
Zero on successful local completion. Nonzero otherwise.
Notes
The collective routines operate on active PE sets that have a non-power-of-two PE_size with some performance degradation. They operate with no performance degradation when nelems is a non-power-of-two value.
NVSHMEM_REDUCTIONS¶
| TYPE | TYPENAME | |||
|---|---|---|---|---|
| short | short | AND, OR, XOR | MAX, MIN | SUM, PROD |
| int | int | AND, OR, XOR | MAX, MIN | SUM, PROD |
| long | long | AND, OR, XOR | MAX, MIN | SUM, PROD |
| long long | longlong | AND, OR, XOR | MAX, MIN | SUM, PROD |
| float | float | MAX, MIN | SUM, PROD | |
| double | double | MAX, MIN | SUM, PROD | |
| double _Complex | complexd | SUM, PROD | ||
| float _Complex | complexf | SUM, PROD |
AND¶
Performs a bitwise AND reduction across a set of PEs.
-
void
nvshmem_TYPENAME_and_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
void
nvshmemx_TYPENAME_and_to_all_on_stream(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_TYPENAME_and_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)
-
__device__ void
nvshmemx_TYPENAME_and_to_all_block(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
__device__ void
nvshmemx_TYPENAME_and_to_all_warp(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
where TYPE is one of the integer types supported for the AND operation and has a corresponding TYPENAME as specified by Table Reduction Types, Names and Supporting Operations.
OR¶
Performs a bitwise OR reduction across a set of PEs.
-
void
nvshmem_TYPENAME_or_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
void
nvshmemx_TYPENAME_or_to_all_on_stream(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_TYPENAME_or_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)
-
__device__ void
nvshmemx_TYPENAME_or_to_all_block(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
__device__ void
nvshmemx_TYPENAME_or_to_all_warp(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
where TYPE is one of the integer types supported for the OR operation and has a corresponding TYPENAME as specified by Table Reduction Types, Names and Supporting Operations.
XOR¶
Performs a bitwise exclusive OR (XOR) reduction across a set of PEs.
-
void
nvshmem_TYPENAME_xor_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
void
nvshmemx_TYPENAME_xor_to_all_on_stream(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_TYPENAME_xor_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)
-
__device__ void
nvshmemx_TYPENAME_xor_to_all_block(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
__device__ void
nvshmemx_TYPENAME_xor_to_all_warp(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
where TYPE is one of the integer types supported for the XOR operation and has a corresponding TYPENAME as specified by Table Reduction Types, Names and Supporting Operations.
MAX¶
Performs a maximum-value reduction across a set of PEs.
-
void
nvshmem_TYPENAME_max_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
void
nvshmemx_TYPENAME_max_to_all_on_stream(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_TYPENAME_max_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)
-
__device__ void
nvshmemx_TYPENAME_max_to_all_block(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
__device__ void
nvshmemx_TYPENAME_max_to_all_warp(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
where TYPE is one of the integer or real types supported for the MAX operation and has a corresponding TYPENAME as specified by Table Reduction Types, Names and Supporting Operations.
MIN¶
Performs a minimum-value reduction across a set of PEs.
-
void
nvshmem_TYPENAME_min_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
void
nvshmemx_TYPENAME_min_to_all_on_stream(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_TYPENAME_min_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)
-
__device__ void
nvshmemx_TYPENAME_min_to_all_block(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
__device__ void
nvshmemx_TYPENAME_min_to_all_warp(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
where TYPE is one of the integer or real types supported for the MIN operation and has a corresponding TYPENAME as specified by Table Reduction Types, Names and Supporting Operations.
SUM¶
Performs a sum reduction across a set of PEs.
-
void
nvshmem_TYPENAME_sum_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
void
nvshmemx_TYPENAME_sum_to_all_on_stream(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_TYPENAME_sum_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)
-
__device__ void
nvshmemx_TYPENAME_sum_to_all_block(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
__device__ void
nvshmemx_TYPENAME_sum_to_all_warp(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
where TYPE is one of the integer, real, or complex types supported for the SUM operation and has a corresponding TYPENAME as specified by Table Reduction Types, Names and Supporting Operations.
PROD¶
Performs a product reduction across a set of PEs.
-
void
nvshmem_TYPENAME_prod_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
void
nvshmemx_TYPENAME_prod_to_all_on_stream(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync, cudaStream_t stream)¶
-
__device__ void
nvshmem_TYPENAME_prod_to_all(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)
-
__device__ void
nvshmemx_TYPENAME_prod_to_all_block(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
-
__device__ void
nvshmemx_TYPENAME_prod_to_all_warp(TYPE *dest, const TYPE *source, int nreduce, int PE_start, int logPE_stride, int PE_size, TYPE *pWrk, long *pSync)¶
where TYPE is one of the integer, real, or complex types supported for the PROD operation and has a corresponding TYPENAME as specified by Table Reduction Types, Names and Supporting Operations.
| TYPE | TYPENAME | |||
|---|---|---|---|---|
| short | short | AND, OR, XOR | MAX, MIN | SUM, PROD |
| int | int | AND, OR, XOR | MAX, MIN | SUM, PROD |
| long | long | AND, OR, XOR | MAX, MIN | SUM, PROD |
| long long | longlong | AND, OR, XOR | MAX, MIN | SUM, PROD |
| float | float | MAX, MIN | SUM, PROD | |
| double | double | MAX, MIN | SUM, PROD | |
| long double | longdouble | MAX, MIN | SUM, PROD | |
| double _Complex | complexd | SUM, PROD | ||
| float _Complex | complexf | SUM, PROD |
- dest [OUT]
- Symmetric address of an array, of length nreduce elements, to receive the result of the reduction routines. The type of dest should match that implied in the SYNOPSIS section.
- source [IN]
- Symmetric address of an array, of length nreduce elements, that contains one element for each separate reduction routine. The type of source should match that implied in the SYNOPSIS section.
- nreduce [IN]
- The number of elements in the dest and source arrays.
Description
NVSHMEM reduction routines are collective routines over an active set that compute one or more reductions across symmetric arrays on multiple PEs. A reduction performs an associative binary routine across a set of values.
The nreduce argument determines the number of separate reductions to perform. The source array on all PEs participating in the reduction provides one element for each reduction. The results of the reductions are placed in the dest array on all PEs participating in the reduction.
The source and dest arguments must either be the same symmetric address, or two different symmetric addresses corresponding to buffers that do not overlap in memory. That is, they must be completely overlapping or completely disjoint.
Active-set-based sync routines operate over all PEs in the active set defined by the PE_start, logPE_stride, PE_size triplet.
As with all active set-based collective routines, each of these routines assumes that only PEs in the active set call the routine. If a PE not in the active set calls an active set-based collective routine, the behavior is undefined.
The values of arguments nreduce, PE_start, logPE_stride, and PE_size must be equal on all PEs in the active set. The same pWrk and pSync work arrays must be passed to all PEs in the active set.
Before any PE calls a reduction routine, the following conditions must be ensured:
- The dest array on all PEs participating in the reduction is ready to accept the results of the reduction.
- If using active-set-based routines, the pWrk and pSync arrays on all PEs in the active set are not still in use from a prior call to a collective NVSHMEM routine.
Otherwise, the behavior is undefined.
Upon return from a reduction routine, the following are true for the local PE:
- The dest array is updated and the source array may be safely reused.
- If using active-set-based routines, the values in the pSync array are restored to the original values.
The complex-typed interfaces are only provided for sum and product reductions. When the C translation environment does not support complex types [1], an NVSHMEM implementation is not required to provide support for these complex-typed interfaces.
Returns
Zero on successful local completion. Nonzero otherwise.
| [1] | That is, under C language standards prior to C or under C when __STDC_NO_COMPLEX__ is defined to 1 |