Memory Model¶
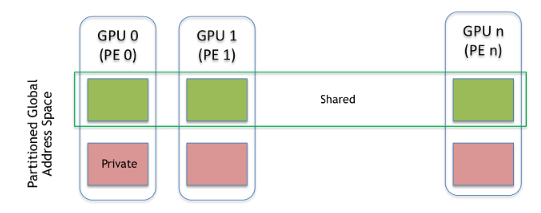
NVSHMEM Memory Model
An NVSHMEM program consists of data objects that are private to each PE and data objects that are remotely accessible by all PEs. Private data objects are stored in the local memory of each PE and can only be accessed by the PE itself; these data objects cannot be accessed by other PEs via NVSHMEM routines. Private data objects follow the memory model of C. Remotely accessible objects, however, can be accessed by remote PEs using NVSHMEM routines. Remotely accessible data objects are called Symmetric Data Objects. Each symmetric data object has a corresponding object with the same name, type, and size on all PEs where that object is accessible via the NVSHMEMAPI [1].
In NVSHMEM, GPU memory allocated by NVSHMEM memory management routines is symmetric. See Section Memory Management for information on allocating symmetric memory.
NVSHMEM dynamic memory allocation routines (e.g., nvshmem_malloc)
allow collective allocation of Symmetric Data Objects on a special
memory region called the Symmetric Heap. The Symmetric Heap is created
during the execution of a program at a memory location determined by the
NVSHMEM library. The Symmetric Heap may reside in different memory
regions on different PEs. Figure NVSHMEM Memory Model shows an example
NVSHMEM memory layout, illustrating the location of remotely accessible
symmetric objects and private data objects.
Pointers to Symmetric Objects¶
Symmetric data objects are referenced in NVSHMEM operations through the local pointer to the desired remotely accessible object. The address contained in this pointer is referred to as a symmetric address. Every symmetric address is also a local address that is valid for direct memory access; however, not all local addresses are symmetric. Manipulation of symmetric addresses passed to NVSHMEM routines—including pointer arithmetic, array indexing, and access of structure or union members—are permitted as long as the resulting local pointer remains within the same symmetric allocation or object. Symmetric addresses are only valid at the PE where they were generated; using a symmetric address generated by a different PE for direct memory access or as an argument to an NVSHMEM routine results in undefined behavior.
Symmetric addresses provided to typed interfaces must be naturally
aligned based on their type and any requirements of the underlying
architecture. Symmetric addresses provided to fixed-size NVSHMEM
interfaces (e.g., nvshmem_put32) must also be aligned to the given
size. Symmetric objects provided to fixed-size NVSHMEM interfaces must
have storage size equal to the bit-width of the given operation [2].
Because C/C++ structures may contain implementation-defined padding,
the fixed-size interfaces should not be used with C/C++ structures.
The “mem” interfaces (e.g., nvshmem_putmem) have no alignment
requirements.
The nvshmem_ptr routine allows the programmer to query a local
address to a remotely accessible data object at a specified PE. The
resulting pointer is valid for direct memory access; however, providing
this address as an argument of an NVSHMEM routine that requires a
symmetric address results in undefined behavior.
Ordering of Operations¶
Blocking operations in NVSHMEM that read data (for example, get or
atomic fetch-and-add) are expected to return data according to the order
in which the operations are performed. For example, consider a program
that performs atomic fetch-and-add of the value 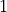 to the
symmetric variable
to the
symmetric variable 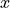 on PE 0.
on PE 0.
a = nvshmem_int_fadd(x, 1, 0);
b = nvshmem_int_fadd(x, 1, 0);
In this example, the OpenSHMEM specification guarantees that
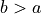 . However, this strong ordering can incur significant
overheads on weakly ordered architectures by requiring memory barriers
to be performed before any such operation returns. NVSHMEM relaxes this
requirement in order to provide a more efficient implementation on
NVIDIA GPUs. Thus, NVSHMEM does not guarantee .
. However, this strong ordering can incur significant
overheads on weakly ordered architectures by requiring memory barriers
to be performed before any such operation returns. NVSHMEM relaxes this
requirement in order to provide a more efficient implementation on
NVIDIA GPUs. Thus, NVSHMEM does not guarantee .
Where such ordering is required, programmers can use an
nvshmem_fence operation to enforce ordering for blocking operations
(for example, between the two statements above). Non-blocking operations
are not ordered by calls to nvshmem_fence. Instead, they must be
completed using the nvshmem_quiet operation. The completion
semantics of fetching operations remain unchanged from the OpenSHMEM
specification: the result of the get or AMO is available for any
dependent operation that appears after it, in program order.
Atomicity Guarantees¶
NVSHMEM contains a number of routines that perform atomic operations on symmetric data objects, which are defined in Section Atomic Memory Operations. The atomic routines guarantee that concurrent accesses by any of these routines to the same location, and using the same datatype (specified in Tables Standard AMO Types and Names and Extended AMO Types and Names) will be exclusive. Exclusivity is also guaranteed when the target PE performs a wait or test operation on the same location and with the same datatype as one or more atomic operations.
NVSHMEM atomic operations do not guarantee exclusivity in the following scenarios, all of which result in undefined behavior.
- When concurrent accesses to the same location are performed using NVSHMEM atomic operations using different datatypes.
- When atomic and non-atomic NVSHMEM operations are used to access the same location concurrently.
- When NVSHMEM atomic operations and non-NVSHMEM operations (e.g., load and store operations) are used to access the same location concurrently.
Differences Between NVSHMEM and OpenSHMEM¶
Ordering of Blocking Fetching Operations¶
Blocking operations in OpenSHMEM that read data, for example, get or atomic fetch-and-add, are expected to return data based on the order in which the operations are performed. For example, consider a program that performs atomic set operations to update symmetric variables x and y on PE 0:
// Let: v_N represent symmetric variable v at PE N
// Input: x_0 = 0, y_0 = 0, i = 0, j = 0
if (nvshmem_my_pe() == 0) {
a = nvshmem_int_atomic_set(x, 1, 0);
nvshmem_quiet();
b = nvshmem_int_atomic_set(y, 1, 0);
}
i = nvshmem_int_atomic_fetch(y, 0);
j = nvshmem_int_atomic_fetch(x, 0);
// Allowed output: i = 1, j = 0
In this example, the OpenSHMEM specification guarantees that if i == 1 then j == 1. However, this strong ordering can incur significant overheads on weakly ordered architectures by requiring memory barriers to be performed before any fetching operation returns. NVSHMEM relaxes this requirement to provide a more efficient implementation that is aligned with the NVIDIA GPU memory model. As a result, NVSHMEM does not guarantee if i == 1 then j == 1.
Where this ordering is required, programmers can use an nvshmem_fence operation
to enforce ordering for blocking operations (for example, between the two
nvshmem_int_atomic_fetch statements above). Non-blocking operations are not ordered by calls to
nvshmem_fence. Instead, these operations must be completed by using the nvshmem_quiet
operation. The completion semantics of fetching operations remain unchanged
from the specification, which is the result of the get or AMO is available for any
dependent operation that appears after it, in program order.
Visibility Guarantees¶
On systems with both NVLink and InfiniBand, the NVSHMEM synchronization
operations including nvshmem_barrier, nvshmem_barrier_all, nvshmem_quiet,
nvshmem_wait_until_*, and nvshmem_test_* only guarantee visibility of
updates to the local PE’s symmetric objects. However, on systems with only
NVLink, these operations guarantee global visibility of updates to symmetric
objects.
| [1] | For efficiency reasons, the same offset (from an arbitrary memory address) for symmetric data objects might be used on all PEs. Further discussion about symmetric heap layout and implementation efficiency can be found in Section NVSHMEM_MALLOC, NVSHMEM_FREE, NVSHMEM_ALIGN |
| [2] | The bit-width of a byte is implementation-defined in C. The
CHAR_BIT constant in limits.h can be used to portably
calculate the bit-width of a C object. |