GPU Optimized Layers and Functions#
PhysicsNeMo is a framework for scientific AI workloads on NVIDIA GPUs. It is designed to help scientists and practitioners continue focusing on delivering accurate model results quickly by including many optimizations for efficient computational performance.
Below are examples of operator-level optimizations in PhysicsNeMo.
Some are exposed as reusable layers in physicsnemo.nn.module, while
others are exposed as stateless functionals in physicsnemo.nn.functional
for direct use in model code and preprocessing pipelines.
When to use each API#
Use layers when you need stateful modules inside model definitions.
Use functionals when you need stateless operators (for example, neighborhood queries, interpolation, and geometry kernels) in custom pipelines or model internals.
In both cases, PhysicsNeMo provides optimized GPU execution paths where supported.
Warp Accelerated Ball Query#
The PhysicsNeMo DoMINO model takes inspiration from classic stencil-based
kernels in High Performance Computing and simulation codes. When learning
projections from one set of points to another, DoMINO uses a radius-based
selection. For each point in a set of queries, up to max_points
from points are returned. This operation is similar to the
query_ball_point function from
scipy.spatial.KDTree.
In PhysicsNeMo, you can access this capability via:
layer APIs used by existing models
the functional APIs
physicsnemo.nn.functional.radius_searchandphysicsnemo.nn.functional.knn
The functional variants provide backend dispatch so the same call pattern can
use accelerated implementations when available, with safe fallbacks when needed.
For radius search specifically, setting max_points enables static output
shapes that are easier to integrate with compilation flows.
These implementations can leverage accelerated backends including NVIDIA Warp library.
Interpolation and Geometry Functionals#
PhysicsNeMo also exposes optimized functionals for interpolation and geometry operations that are common in scientific ML pipelines:
physicsnemo.nn.functional.interpolationphysicsnemo.nn.functional.signed_distance_field
These APIs provide a stable functional surface while enabling backend-specific optimizations under the hood. For interpolation, both torch and Warp-backed implementations are available.
Transformer Engine Accelerated LayerNorm#
Many models, such as PhysicsNeMo’s implementation of MeshGraphNet, use
LayerNorm to normalize data in the model and accelerate training. While
accurate, for some instances of MeshGraphNet, the LayerNorm implementation
in PyTorch was accounting for more than 25% of the execution time. To
mitigate this, PhysicsNeMo provides an optimized wrapper to LayerNorm
that can take advantage of the more optimized version
of LayerNorm from
TransformerEngine
In MeshGraphNet, training up to 200k nodes and 1.2M edges in a single graph shows approximately 1/3 reduction in runtime. Also, using the PyTorch Geometric backend instead of DGL, almost halves the latency for the training iteration.
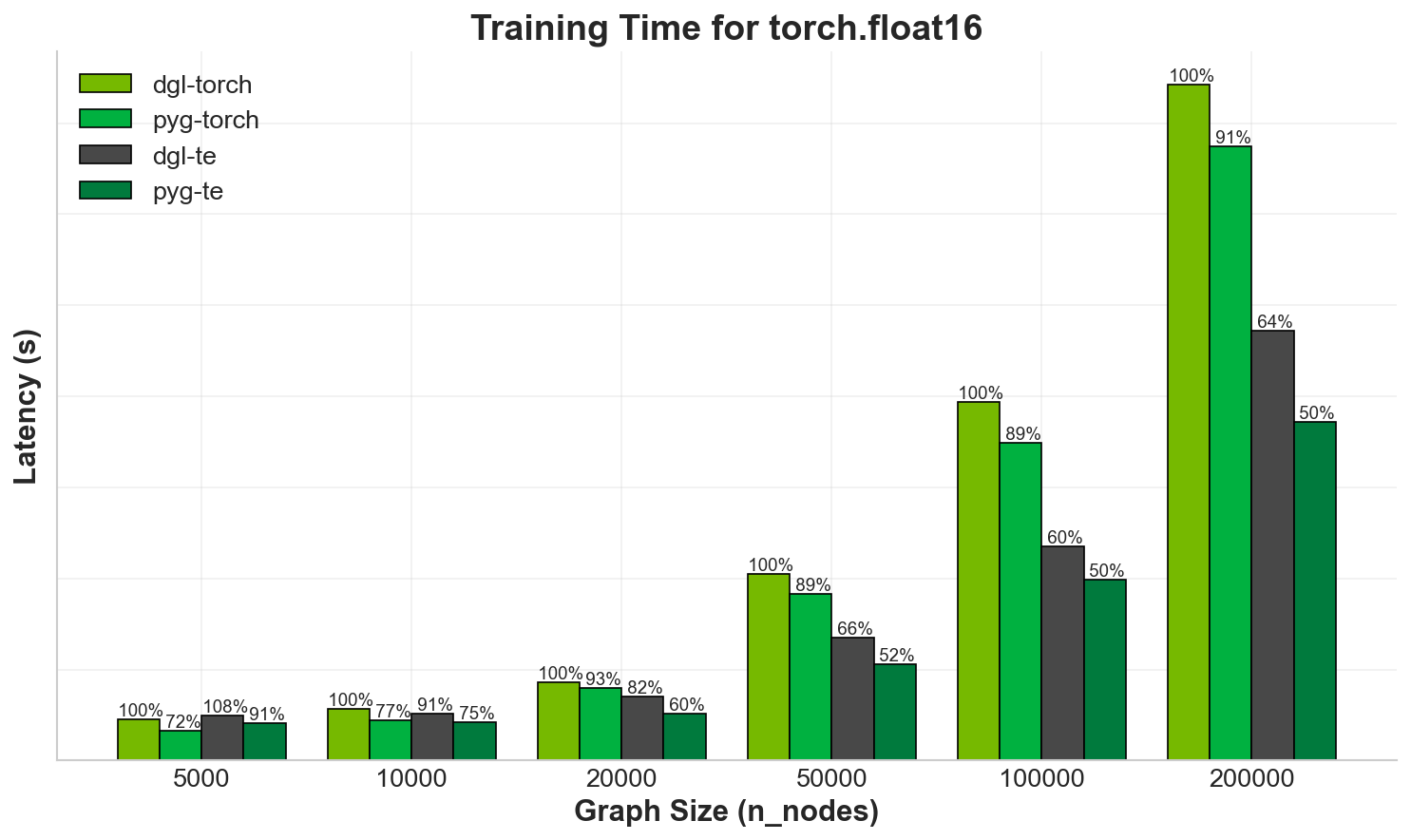
Fig. 13 Training time for MeshGraphNet comparing TransformerEngine LayerNorm
to PyTorch LayerNorm, as well as PyTorch Geometric and DGL backends. Values
are relative to DGL and torch.nn.LayerNorm, lower is better.#