Output Details#
The qualification tool will generate a number of detailed reports in addition to the high-level recommendations. The summary report goes to STDOUT and by default it outputs log/CSV files under ./rapids_4_spark_qualification_output/ that contain the processed applications. The output will go into your default filesystem and it supports both local filesystem and HDFS. Note that if you are on an HDFS cluster the default filesystem is likely HDFS for both the input and output. If you want to point to the local filesystem be sure to include prefix file: in the path.
The qualification tool generates a brief summary on the STDOUT, which also gets saved as a text file. The detailed report of the processed apps is saved as a set of CSV files that can be used for post-processing. The CSV reports include the estimated performance if the app is run on the GPU for each of the following: app execution; stages; and execs.
Starting with release “22.06”, the default is to generate the report into two different formats: text files; and HTML.
The tree structure of the output directory ${OUTPUT_FOLDER}/rapids_4_spark_qualification_output is as follows:
rapids_4_spark_qualification_output# 1 rapids_4_spark_qualification_output
2 ├── rapids_4_spark_qualification_output.csv
3 ├── rapids_4_spark_qualification_output.log
4 ├── rapids_4_spark_qualification_output_persql.log
5 ├── rapids_4_spark_qualification_output_persql.csv
6 ├── rapids_4_spark_qualification_output_execs.csv
7 ├── rapids_4_spark_qualification_output_stages.csv
8 ├── rapids_4_spark_qualification_output_mlfunctions.csv
9 ├── rapids_4_spark_qualification_output_mlfunctions_totalduration.csv
10 ├── rapids_4_spark_qualification_output_unsupportedOperators.csv
11 ├── rapids_4_spark_qualification_output_unsupportedOperatorsStageDuration.csv
12 ├── runtime.properties
13 ├── tuning
14 │ ├── app-001-0001.conf
15 │ └── app-001-0001.log
16 └── ui
17 ├── assets
18 │ ├── bootstrap/
19 │ ├── datatables/
20 │ ├── jquery/
21 │ ├── mustache-js/
22 │ └── spur/
23 ├── css
24 │ └── rapids-dashboard.css
25 ├── html
26 │ ├── application.html
27 │ ├── index.html
28 │ ├── raw.html
29 │ └── sql-recommendation.html
30 └── js
31 ├── app-report.js
32 ├── data-output.js
33 ├── per-sql-report.js
34 ├── qual-report.js
35 ├── raw-report.js
36 ├── ui-config.js
37 └── uiutils.js
For information on the files content and processing the Qualification report and the recommendation, please refer to Understanding the Qualification tool output and Output Formats sections below.
Tuning Output#
When the “--auto-tuner” argument is enabled, one notable addition is the creation of a new subdirectory within the output folder named “tuning”. Within this directory, each application will have two files:
<appi-id>.log: This file contains the recommendations and accompanying comments.<app-id>.conf: Here, you’ll find the combined Spark properties.
It’s worth noting that certain properties with sensitive information will be redacted in the combined results.
The Auto-Tuner output has 2 main sections:
Spark Properties: A list of Apache Spark configurations to tune the performance of the app. The list is the result of
diffbetween the existing app configurations and the recommended ones. Therefore, a recommendation matches the existing app configuration, it will not show up in the list.Comments: A list of messages to highlight properties that were missing in the app configurations, or the cause of failure to generate the recommendations.
Examples
1Spark Properties:
2
3–conf spark.executor.cores=16
4–conf spark.executor.instances=8
5–conf spark.executor.memory=32768m
6–conf spark.executor.memoryOverhead=7372m
7–conf spark.rapids.memory.pinnedPool.size=4096m
8–conf spark.rapids.sql.concurrentGpuTasks=2
9–conf spark.sql.files.maxPartitionBytes=512m
10–conf spark.sql.shuffle.partitions=200
11–conf spark.task.resource.gpu.amount=0.0625
12
13Comments:
14
15- ‘spark.executor.instances’ was not set.
16- ‘spark.executor.cores’ was not set.
17- ‘spark.task.resource.gpu.amount’ was not set.
18- ‘spark.rapids.sql.concurrentGpuTasks’ was not set.
19- ‘spark.executor.memory’ was not set.
20- ‘spark.rapids.memory.pinnedPool.size’ was not set.
21- ‘spark.executor.memoryOverhead’ was not set.
22- ‘spark.sql.files.maxPartitionBytes’ was not set.
23- ‘spark.sql.shuffle.partitions’ was not set.
24- ‘spark.sql.adaptive.enabled’ should be enabled for better
25 performance.
1Spark Properties:
2
3--conf spark.executor.instances=8
4--conf spark.sql.shuffle.partitions=200
5
6Comments:
7
8- 'spark.sql.shuffle.partitions' was not set.
1Cannot recommend properties. See Comments.
2
3Comments:
4- java.io.FileNotFoundException: File worker-info.yaml does not exist
5- 'spark.executor.memory' should be set to at least 2GB/core.
6- 'spark.executor.instances' should be set to (gpuCount * numWorkers).
7- 'spark.task.resource.gpu.amount' should be set to Max(1, (numCores / gpuCount)).
8- 'spark.rapids.sql.concurrentGpuTasks' should be set to Max(4, (gpuMemory / 8G)).
9- 'spark.rapids.memory.pinnedPool.size' should be set to 2048m.
10- 'spark.sql.adaptive.enabled' should be enabled for better performance.
Understanding the Qualification Tool Output#
For each processed Spark application, the Qualification tool generates two main fields to help quantify the expected acceleration of migrating a Spark application or query to GPU.
Estimated GPU Duration: predicted runtime of the app if it was run on GPU. It is the sum of the accelerated operator durations and ML functions duration(if applicable) along with durations that could not run on GPU because they are unsupported operators or not SQL/Dataframe.
Estimated Speed-up: the estimated speed-up is simply the original CPU duration of the app divided by the estimated GPU duration. That will estimate how much faster the application would run on GPU.
The lower the estimated GPU duration, the higher the “Estimated Speed-up”. The processed applications or queries are ranked by the “Estimated Speed-up”. Based on how high the estimated speed-up, the tool classifies the applications into the following different categories:
Strongly RecommendedRecommendedNot RecommendedNot Applicable: indicates that the app has job or stage failures.
As mentioned before, the tool does not guarantee the applications or queries with the highest recommendation will actually be accelerated the most. Please refer to Supported operators guide.
In addition to the recommendation, the Qualification tool reports a set of metrics in tasks of SQL Dataframe operations within the scope of: “Entire App”; “Stages”; and “Execs”. The report is divided into three main levels. The fields of each level are described in details in the following sections: Detailed App Report, Stages report, and Execs report. Then we describe the output formats and their file locations in Output Formats section.
There is an option to print a report at the SQL query level in addition to the application level.
Detailed App Report#
The report represents the entire app execution, including unsupported operators and non-SQL operations.
Recommendation: recommendation based on
Estimated Speed-up Factor, where an app can be “Strongly Recommended”, “Recommended”, “Not Recommended”, or “Not Applicable”. The latter indicates that the app has job or stage failures.SQL DF duration: wall-Clock time duration that includes only SQL-Dataframe queries.
GPU Opportunity: wall-Clock time that shows how much of the SQL duration and ML functions(if applicable) can be accelerated on the GPU.
Estimated GPU Time Saved: estimated wall-Clock time saved if it was run on the GPU.
SQL Dataframe Task Duration: amount of time spent in tasks of SQL Dataframe operations.
Executor CPU Time Percent: this is an estimate at how much time the tasks spent doing processing on the CPU vs waiting on IO. This is not always a good indicator because sometimes the IO that is encrypted and the CPU has to do work to decrypt it, so the environment you are running on needs to be taken into account.
SQL Ids with Failures: SQL Ids of queries with failed jobs.
Unsupported Read File Formats and Types: looks at the Read Schema and reports the file formats along with types which may not be fully supported. Example:
JDBC[*]. Note that this is based on the current version of the plugin and future versions may add support for more file formats and types.Unsupported Write Data Format: reports the data format which we currently don’t support, i.e. if the result is written in JSON or CSV format.
Complex Types: looks at the Read Schema and reports if there are any complex types(array, struct or maps) in the schema.
Nested Complex Types: nested complex types are complex types which contain other complex types (Example:
array<struct<string,string>>). Note that it can read all the schemas for DataSource V1. The Data Source V2 truncates the schema, so if you see “...”, then the full schema is not available. For such schemas we read until...and report if there are any complex types and nested complex types in that.Potential Problems: some UDFs and nested complex types. Please keep in mind that the tool is only able to detect certain issues.
Longest SQL Duration: the maximum amount of time spent in a single task of SQL Dataframe operations.
NONSQL Task Duration Plus Overhead: Time duration that does not span any running SQL task.
Unsupported Task Duration: sum of task durations for any unsupported operators.
Supported SQL DF Task Duration: sum of task durations that are supported by RAPIDS GPU acceleration.
Task Speedup Factor: the average speed-up of all stages.
App Duration Estimated: True or False indicates if we had to estimate the application duration. If we had to estimate it, the value will be
Trueand it means the event log was missing the application finished event, so we will use the last job or sql execution time we find as the end time used to calculate the duration.Unsupported Execs: reports all the execs that are not supported by GPU in this application. Note that an Exec name may be printed in this column if any of the expressions within this Exec is not supported by GPU. If the resultant string exceeds maximum limit (25), then … is suffixed to the STDOUT and full output can be found in the CSV file.
Unsupported Expressions: reports all expressions not supported by GPU in this application.
Read Schema: shows the datatypes and read formats. This field is only listed when the argument
--report-read-schemais passed to the CLI.Estimated Frequency: application executions per month assuming uniform distribution, default frequency is daily (30 times per month) and minimum frequency is monthly (1 time per month). For a given log set, determines a logging window using the earliest start time and last end time of all logged applications. Counts the number of executions of a specific
App Nameover the logging window and converts the frequency to per month (30 days). Applications that are only ran once are assigned the default frequency.
Note
The Qualification tool won’t catch all UDFs, and some of the UDFs can be handled with additional steps. Please refer to Supported operators guide for more details on UDF.
By default, the applications and queries are sorted in descending order by the following fields:
Recommendation
Estimated GPU Time Saved
End Time
Stages Report#
For each stage used in SQL operations, the Qualification tool generates the following information:
App ID
Stage ID
Average Speedup Factor: the average estimated speed-up of all the operators in the given stage.
Stage Task Duration: amount of time spent in tasks of SQL Dataframe operations for the given stage.
Unsupported Task Duration: sum of task durations for the unsupported operators. For more details, see the Supported operators guide.
Stage Estimated: True or False indicates if we had to estimate the stage duration.
Execs Report#
The Qualification tool generates a report of the “Exec” in the “SparkPlan” or “Executor Nodes” along with the estimated acceleration on the GPU. Please refer to the Supported operators guide for more details on limitations on UDFs and unsupported operators.
App ID
SQL ID
Exec Name: example
Filter,HashAggregateExpression Name
Task Speedup Factor: it is simply the average acceleration of the operators based on the original CPU duration of the operator divided by the GPU duration. The tool uses historical queries and benchmarks to estimate a speed-up at an individual operator level to calculate how much a specific operator would accelerate on GPU.
Exec Duration: wall-Clock time measured since the operator starts till it is completed.
SQL Node Id
Exec Is Supported: whether the Exec is supported by RAPIDS or not. Please refer to the Supported operators guide.
Exec Stages: an array of stage IDs
Exec Children
Exec Children Node Ids
Exec Should Remove: whether the Op is removed from the migrated plan.
Parsing Expressions within each Exec
The Qualification tool looks at the expressions in each Exec to provide a fine-grained assessment of RAPIDS’ support.
Note that it is not possible to extract the expressions for each available Exec: - some Execs do not take any expressions, and - some execs may not show the expressions in the eventlog.
The following table lists the exec’s name and the status of parsing their expressions where: - “Expressions Unavailable” marks the Execs that do not show expressions in the eventlog - “Fully Parsed” marks the Execs that have their expressions fully parsed by the Qualification tool - “In Progress” marks the Execs that are still being investigated; therefore, a set of the marked Execs may be fully parsed in future releases.
Exec |
Expressions Unavailable |
Fully Parsed |
In Progress |
|---|---|---|---|
AggregateInPandasExec |
☑️ |
||
AQEShuffleReadExec |
☑️ |
||
ArrowEvalPythonExec |
☑️ |
||
BatchScanExec |
☑️ |
||
BroadcastExchangeExec |
☑️ |
||
BroadcastHashJoinExec |
☑️ |
||
BroadcastNestedLoopJoinExec |
☑️ |
||
CartesianProductExec |
☑️ |
||
CoalesceExec |
☑️ |
||
CollectLimitExec |
☑️ |
||
CreateDataSourceTableAsSelectCommand |
☑️ |
||
CustomShuffleReaderExec |
☑️ |
||
DataWritingCommandExec |
☑️ |
||
ExpandExec |
☑️ |
||
FileSourceScanExec |
☑️ |
||
FilterExec |
☑️ |
||
FlatMapGroupsInPandasExec |
☑️ |
||
GenerateExec |
☑️ |
||
GlobalLimitExec |
☑️ |
||
HashAggregateExec |
☑️ |
||
InMemoryTableScanExec |
☑️ |
||
InsertIntoHadoopFsRelationCommand |
☑️ |
||
LocalLimitExec |
☑️ |
||
MapInPandasExec |
☑️ |
||
ObjectHashAggregateExec |
☑️ |
||
ProjectExec |
☑️ |
||
RangeExec |
☑️ |
||
SampleExec |
☑️ |
||
ShuffledHashJoinExec |
☑️ |
||
ShuffleExchangeExec |
☑️ |
||
SortAggregateExec |
☑️ |
||
SortExec |
☑️ |
||
SortMergeJoinExec |
☑️ |
||
SubqueryBroadcastExec |
☑️ |
||
TakeOrderedAndProjectExec |
☑️ |
||
UnionExec |
☑️ |
||
WindowExec |
☑️ |
||
WindowInPandasExec |
☑️ |
MLFunctions Report#
The Qualification tool generates a report if there are SparkML or Spark XGBoost functions used in the eventlog. The functions in “spark.ml.” or “spark.XGBoost.” packages are displayed in the report.
App ID
Stage ID
ML Functions: List of ML functions used in the corresponding stage.
Stage Task Duration: amount of time spent in tasks containing ML functions for the given stage.
MLFunctions Total Duration Report#
The Qualification tool generates a report of total duration across all
App ID
_Stage_Ids : Stage Id’s corresponding to the given ML function.
ML Function Name: ML function name supported on GPU.
Total Duration: total duration across all stages for the corresponding ML function.
Output Formats#
The Qualification tool generates the output as CSV/log files. Starting from “22.06”, the default is to generate the report into two different formats: CSV/log files; and HTML.
HTML Report#
Starting with release “22.06”, the HTML report is generated by default under the output directory ${OUTPUT_FOLDER}/rapids_4_spark_qualification_output/ui. The HTML report is disabled by passing --no-html-report as described in the Qualification tool options section above. To browse the content of the html report:
For HDFS or remote node, copy the directory of
${OUTPUT_FOLDER}/rapids_4_spark_qualification_output/uito your local node.Open
rapids_4_spark_qualification_output/ui/index.htmlin your local machine’s web-browser (Chrome/Firefox are recommended).
The HTML view renders the detailed information into tables that allow following features:
searching
ordering by specific column
exporting table into CSV file
interactive filter by recommendations and/or user-name.
By default, all tables show 20 entries per page, which can be changed by selecting a different page-size in the table’s navigation bar.
The following sections describe the HTML views.
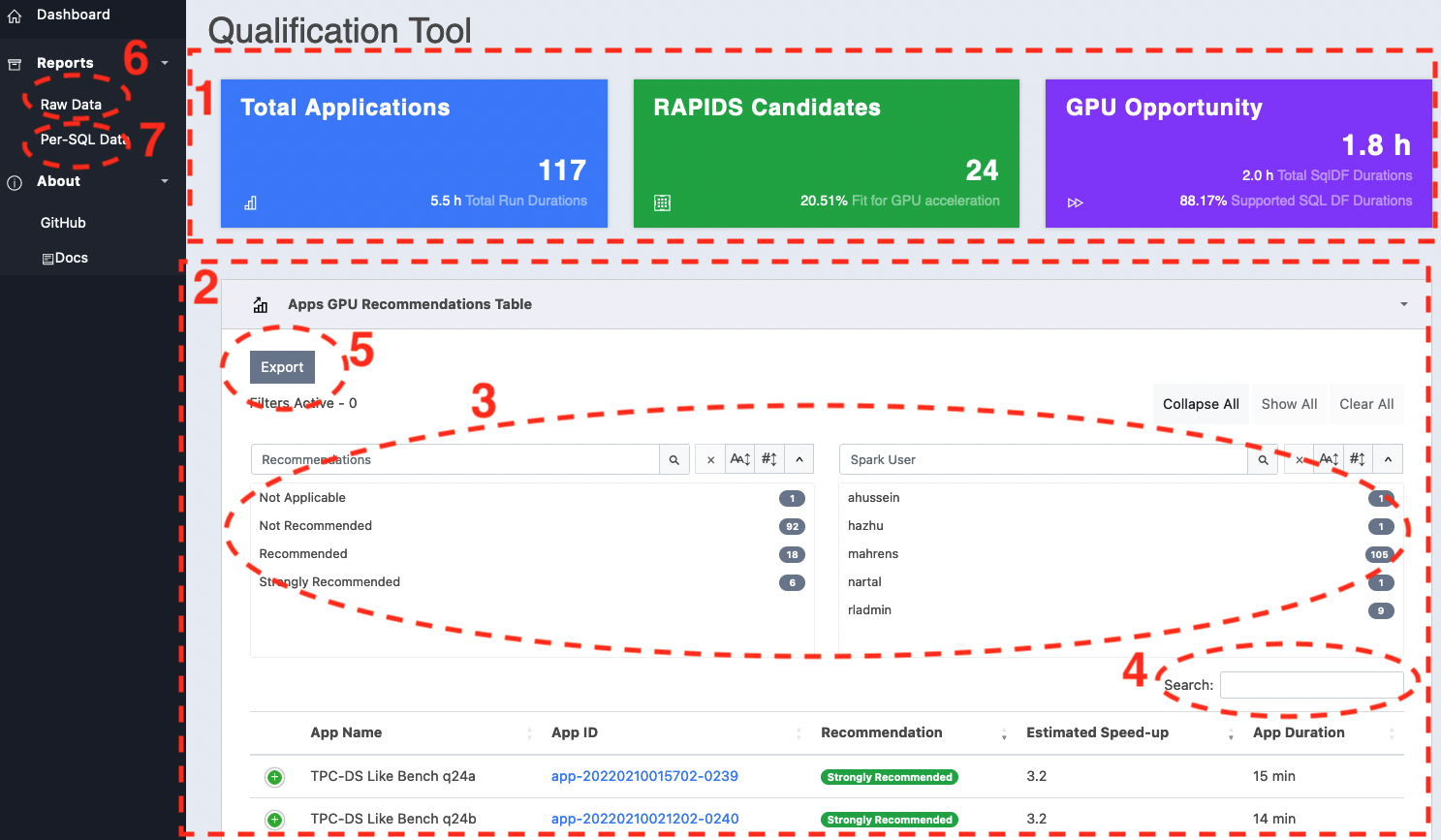
Application Recommendations Summary#
index.html shows the summary of the estimated GPU performance. The “GPU Recommendations Table” lists the processed applications ranked by the “Estimated GPU Speed-up” along with the ability to search, and filter the results. By clicking the “App ID” link of a specific app, you navigate to the details view of that app which is described in App-Details View section.
The summary report contains the following components:
Stats-Row: statistics card summarizing the following information:
“Total Applications”: total number of applications analyzed by the Qualification tool and the total execution time.
“RAPIDS Candidates”: marks the number applications that are either “Recommended”, or “Strongly Recommended”.
“GPU Opportunity”: shows the total of “GPU Opportunity” and “SQL DF duration” fields across all the apps.
GPU Recommendations Table: this table lists all the analyzed applications along with subset of fields that are directly involved in calculating the GPU performance estimate. Each row expands showing more fields by clicking on the control column.
The searchPanes with the capability to search the app list by selecting rows in the panes. The “Recommendations” and “Spark User” filters are cascaded which allows the panes to be filtered based on the values selected in the other pane.
Text Search field that allows further filtering, removing data from the result set as keywords are entered. The search box will match on multiple columns including: “App ID”, “App Name”, “Recommendation”
HTML5 export button saves the table to CSV file into the browser’s default download folder.
The
Raw Datalink in the left navigation bar redirects to a detailed report.The
Per-SQL Datalink in the left navigation bar redirects to a summary report that shows the per-SQL estimated GPU performance.
Qualification-HTML-Recommendation-View#
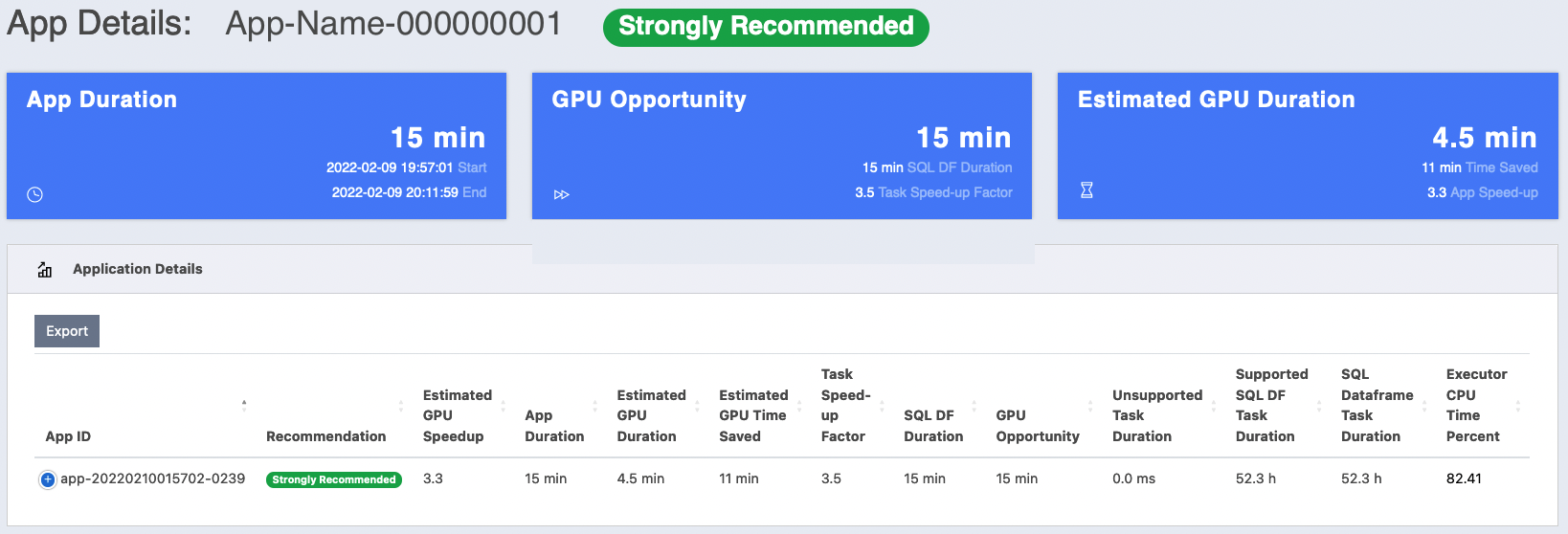
App-Details View#
When you click the “App ID” of a specific row in the “GPU Recommendations Table”, the browser navigates to this view which shows the metrics and estimated GPU performance for the given application. It contains the following main components:
Card title: contains the application name and the Recommendation.
Stats-Row: statistics card summarizing the following information:
“App Duration”: the total execution time of the app, marking the start and end time.
“GPU Opportunity”: the wall-Clock time that shows how much of the SQL duration can be accelerated on the GPU. It shows the actual wall-Clock time duration that includes only SQL-Dataframe queries including non-supported ops, dubbed “SQL DF Duration”. This is followed by “Task Speed-up Factor” which represents the average speed-up of all app stages.
“Estimated GPU Duration”: the predicted runtime of the app if it was run on GPU. For convenience, it calculates the estimated wall-clock time difference between the CPU and GPU executions. The original CPU duration of the app divided by the estimated GPU duration and displayed as “App Speed-up”.
Application Details: this table lists all the fields described previously in the Detailed App report section. Note that this table has more columns than can fit in a normal browser window. Therefore, the UI application dynamically optimizes the layout of the table to fit the browser screen. By clicking on the control column, the row expands to show the remaining hidden columns.
Stage Details Table: lists all the app stages with set of columns listed in Stages report section. The HTML5 export button saves the table to CSV file into the browser’s default download folder.
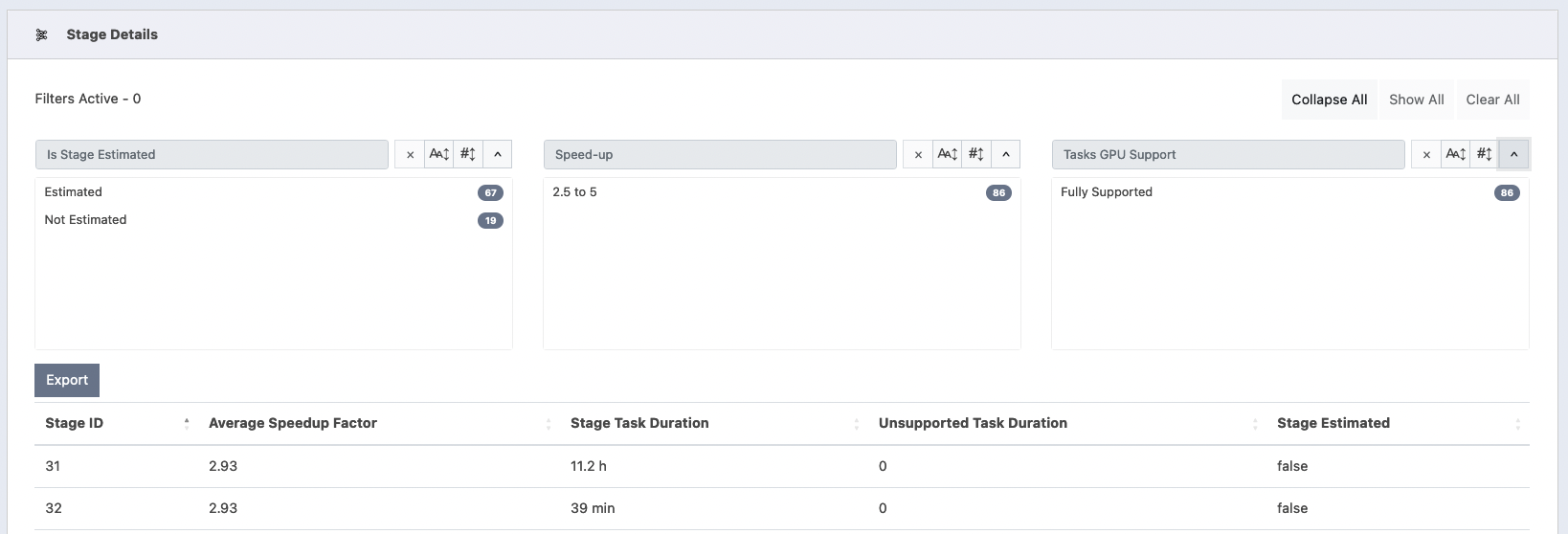
The table has cascaded searchPanes, which means that the table allows the panes to be filtered based on the values selected in the other panes.
There are three searchPanes:
“Is Stage Estimated”: it splits the stages into two groups based on whether the stage duration time was estimated or not.
“Speed-up”: groups the stages by their “average speed-up”. Each stage can belong to one of the following predefined speed-up ranges:
1.0 (No Speed-up);[1.0, 1.3];[1.3, 2.5];[2.5, 5]; and[5, ]. The search-pane does not show a range bucket if its count is 0.“Tasks GPU Support”: this filter can be used to find stages having all their execs supported by the GPU.
Execs Details Table: lists all the app Execs with set of columns listed in Execs report section. The HTML5 export button saves the table to CSV file into the browser’s default download folder.
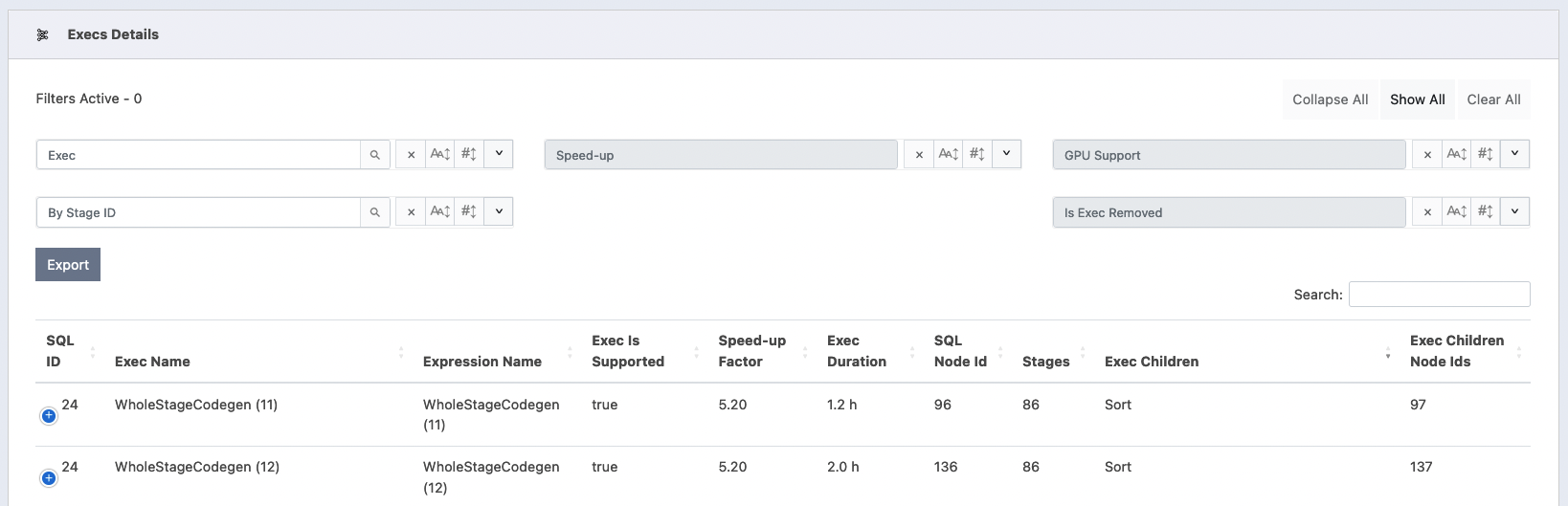
The table has cascaded searchPanes, which means that the table allows the panes to be filtered based on the values selected in the other panes.
There are three searchPanes:
“Exec”: filters the rows by exec name. This filter also allows text searching by typing into the filter-title as a text input.
“Speed-up”: groups the stages by their “average speed-up”. Each stage can belong to one of the following predefined speed-up ranges:
1.0 (No Speed-up);]1.0, 1.3[;[1.3, 2.5[;[2.5, 5[; and[5, _]. The search-pane does not show a range bucket if its count is 0.“GPU Support”: filters the execs whether an exec is supported by GPU or not.
“Stage ID”: filters rows by the stage ID. It also allows text-searching by typing into the filter-title as a text input.
“Is Exec Removed”: filters rows that were removed from the migrated plan.
SQL Details Table: lists Per-SQL GPU recommendation. The HTML5 export button saves the table to CSV file into the browser’s default download folder. The rows in the table can be filtered by “SQL Description”, “SQL ID”, or “Recommendation”.
Raw Data#
raw.html displays all the fields listed in “Detailed App Report” in more readable format. Columns representing “time duration” are rounded to nearest “ms”, “seconds”, “minutes”, and “hours”. The search box will match on multiple columns including: “App ID”, “App Name”, “Recommendation”, “User Name”, “Unsupported Write Data Format”, “Complex Types”, “Nested Complex Types”, and “Read Schema”. The detailed table can also be exported as a CSV file into the browser’s default download folder.
Note that this table has more columns than can fit in a normal browser window. Therefore, the UI application dynamically optimizes the layout of the table to fit the browser screen. By clicking on the control column, the row expands to show the remaining hidden columns.
Per-SQL Data#
sql-recommendation.html displays a summary of the estimate GPU performance for each query. Note that the SQL queries across all the apps are combined in a single view; therefore, the “SQL ID” field may not be unique.
Text and CSV files#
The Qualification tool generates a set of log/CSV files in the output folder ${OUTPUT_FOLDER}/rapids_4_spark_qualification_output. The content of each file is summarized in the following two sections.
Application Report Summary#
The Qualification tool generates a brief summary that includes the projected application’s performance if the application is run on the GPU. Beside sending the summary to STDOUT, the Qualification tool generates text as rapids_4_spark_qualification_output.log
The summary report outputs the following information: “App Name”, “App ID”, “App Duration”, “SQL DF duration”, “GPU Opportunity”, “Estimated GPU Duration”, “Estimated GPU Speed-up”, “Estimated GPU Time Saved”, and “Recommendation”.
1+------------+--------------+----------+----------+-------------+-----------+-----------+-----------+--------------------+-------------------------------------------------------+
2| App Name | App ID | App | SQL DF | GPU | Estimated | Estimated | Estimated | Recommendation | Unsupported Execs |Unsupported Expressions|
3| | | Duration | Duration | Opportunity | GPU | GPU | GPU | | | |
4| | | | | | Duration | Speedup | Time | | | |
5| | | | | | | | Saved | | | |
6+============+==============+==========+==========+=============+===========+===========+===========+====================+=======================================================+
7| appName-01 | app-ID-01-01 | 898429| 879422| 879422| 273911.92| 3.27| 624517.06|Strongly Recommended| | |
8+------------+--------------+----------+----------+-------------+-----------+-----------+-----------+--------------------+-------------------------------------------------------+
9| appName-02 | app-ID-02-01 | 9684| 1353| 1353| 8890.09| 1.08| 793.9| Not Recommended|Filter;SerializeFromObject;S...| hex |
10+------------+--------------+----------+----------+-------------+-----------+-----------+-----------+--------------------+-------------------------------------------------------+
In the above example, two application event logs were analyzed. “app-ID-01-01” is “Strongly Recommended” because Estimated GPU Speedup is ~3.27. On the other hand, the estimated acceleration running “app-ID-02-01” on the GPU is not high enough; hence the app is not recommended.
Per SQL Query Report Summary#
The Qualification tool has an option to generate a report at the per SQL query level. It generates a brief summary that includes the projected queries performance if the query is run on the GPU. Beside sending the summary to STDOUT, the Qualification tool generates text as rapids_4_spark_qualification_output_persql.log
The summary report outputs the following information: “App Name”, “App ID”, “SQL ID”, “SQL Description”, “SQL DF duration”, “GPU Opportunity”, “Estimated GPU Duration”, “Estimated GPU Speed-up”, “Estimated GPU Time Saved”, and “Recommendation”.
1+------------+--------------+----------+---------------+----------+-------------+-----------+-----------+-----------+--------------------+
2| App Name | App ID | SQL ID | SQL | SQL DF | GPU | Estimated | Estimated | Estimated | Recommendation |
3| | | | Description | Duration | Opportunity | GPU | GPU | GPU | |
4| | | | | | | Duration | Speedup | Time | |
5| | | | | | | | | Saved | |
6+============+==============+==========+===============+==========+=============+===========+===========+===========+====================+
7| appName-01 | app-ID-01-01 | 1| query41| 571| 571| 187.21| 3.05| 383.78|Strongly Recommended|
8+------------+--------------+----------+---------------+----------+-------------+-----------+-----------+-----------+--------------------+
9| appName-02 | app-ID-02-01 | 3| query44| 1116| 0| 1115.98| 1.0| 0.01| Not Recommended|
10+------------+--------------+----------+---------------+----------+-------------+-----------+-----------+-----------+--------------------+
Detailed App Report#
Entire App Report#
The first part of the detailed report is saved as rapids_4_spark_qualification_output.csv. The apps are processed and ranked by the Estimated GPU Speed-up. In addition to the fields listed in the “Report Summary”, it shows all the app fields. The duration(s) are reported are in milliseconds.
Per SQL Report#
The second file is saved as rapids_4_spark_qualification_output_persql.csv. This contains the per SQL query report in CSV format.
Sample output in text:
1+---------------+-----------------------+------+----------------+---------------+---------------+----------------------+---------------------+------------------------+--------------------+
2| App Name| App ID|SQL ID| SQL Description|SQL DF Duration|GPU Opportunity|Estimated GPU Duration|Estimated GPU Speedup|Estimated GPU Time Saved| Recommendation|
3+===============+=======================+======+================+===============+===============+======================+=====================+========================+====================+
4|NDS - Power Run|app-20220702220255-0008| 103| query87| 15871| 15871| 4496.03| 3.53| 11374.96|Strongly Recommended|
5|NDS - Power Run|app-20220702220255-0008| 106| query38| 11077| 11077| 3137.96| 3.53| 7939.03|Strongly Recommended|
6+---------------+-----------------------+------+----------------+---------------+---------------+----------------------+---------------------+------------------------+--------------------+
Stages Report#
The third file is saved as rapids_4_spark_qualification_output_stages.csv.
Sample output in text:
1+--------------+----------+-----------------+------------+---------------+-----------+
2| App ID | Stage ID | Average Speedup | Stage Task | Unsupported | Stage |
3| | | Factor | Duration | Task Duration | Estimated |
4+==============+==========+=================+============+===============+===========+
5| app-ID-01-01 | 25 | 2.1 | 23 | 0 | false |
6+--------------+----------+-----------------+------------+---------------+-----------+
7| app-ID-02-01 | 29 | 1.86 | 0 | 0 | true |
8+--------------+----------+-----------------+------------+---------------+-----------+
Execs Report#
The last file is saved rapids_4_spark_qualification_output_execs.csv. Similar to the app and stage information, the table shows estimated GPU performance of the SQL Dataframe operations.
Sample output in text:
1+--------------+--------+---------------------------+-----------------------+--------------+----------+----------+-----------+--------+----------------------------+---------------+-------------+
2| App ID | SQL ID | Exec Name | Expression Name | Task Speedup | Exec | SQL Node | Exec Is | Exec | Exec Children | Exec Children | Exec Should |
3| | | | | Factor | Duration | Id | Supported | Stages | | Node Ids | Remove |
4+==============+========+===========================+=======================+==============+==========+==========+===========+========+============================+===============+=============+
5| app-ID-02-01 | 7 | Execute CreateViewCommand | | 1.0 | 0 | 0 | false | | | | false |
6+--------------+--------+---------------------------+-----------------------+--------------+----------+----------+-----------+--------+----------------------------+---------------+-------------+
7| app-ID-02-01 | 24 | Project | | 2.0 | 0 | 21 | true | | | | false |
8+--------------+--------+---------------------------+-----------------------+--------------+----------+----------+-----------+--------+----------------------------+---------------+-------------+
9| app-ID-02-01 | 24 | Scan parquet | | 2.0 | 260 | 36 | true | 24 | | | false |
10+--------------+--------+---------------------------+-----------------------+--------------+----------+----------+-----------+--------+----------------------------+---------------+-------------+
11| app-ID-02-01 | 15 | Execute CreateViewCommand | | 1.0 | 0 | 0 | false | | | | false |
12+--------------+--------+---------------------------+-----------------------+--------------+----------+----------+-----------+--------+----------------------------+---------------+-------------+
13| app-ID-02-01 | 24 | Project | | 2.0 | 0 | 14 | true | | | | false |
14+--------------+--------+---------------------------+-----------------------+--------------+----------+----------+-----------+--------+----------------------------+---------------+-------------+
15| app-ID-02-01 | 24 | WholeStageCodegen (6) | WholeStageCodegen (6) | 2.8 | 272 | 2 | true | 30 | Project:BroadcastHashJoin: | 3:4:5 | false |
16| | | | | | | | | | HashAggregate | | |
17+--------------+--------+---------------------------+-----------------------+--------------+----------+----------+-----------+--------+----------------------------+---------------+-------------+