Jupyter Notebook Detailed Workflow
There are multiple notebooks that provide a glimpse of what each model offered by TAO is capable of.
The notebooks are grouped into the following domains:
classification - contains the workflows of classification models
object_detection - contains the workflows of object detection models
segmentation - contains the workflows of segmentation models
purpose_built_models - contains the workflows of models with a specific purpose (like action recognition, pose classification) and can’t be grouped into classification, object_detection, or segmentation
auto_labeling - contains the workflow of segmentation auto-labeling for a bounding box dataset
The following example uses the classification API notebook and goes through the different actions. The other notebooks follow a similar workflow.
Choosing a model.
Each notebook belonging to a domain, has multiple models supported by that domain by TAO. In this instance for classification notebook, there are two models, one is
classification_pytanother isclassification_tf2.Pick a model that suits your needs. The documentation links to each of the models are available as commented lines:

Enabling AutoML.
TAO provides a hyper-parameter optimization feature that performs a series of experiments and return the best set of hyper-parameters with a model file.
See the AutoML docs for more details.
The notebooks have AutoML disabled by default, you can toggle it on if you want.

Enter your cloud credentials.
TAO API services interacts with cloud service provides for storage (AWS and Azure are supported).
You can add your datasets to these cloud buckets and the experiment actions artifacts, for example training checkpoints is stored in the cloud storage details you provide.
All the credentials are encrypted and saved.
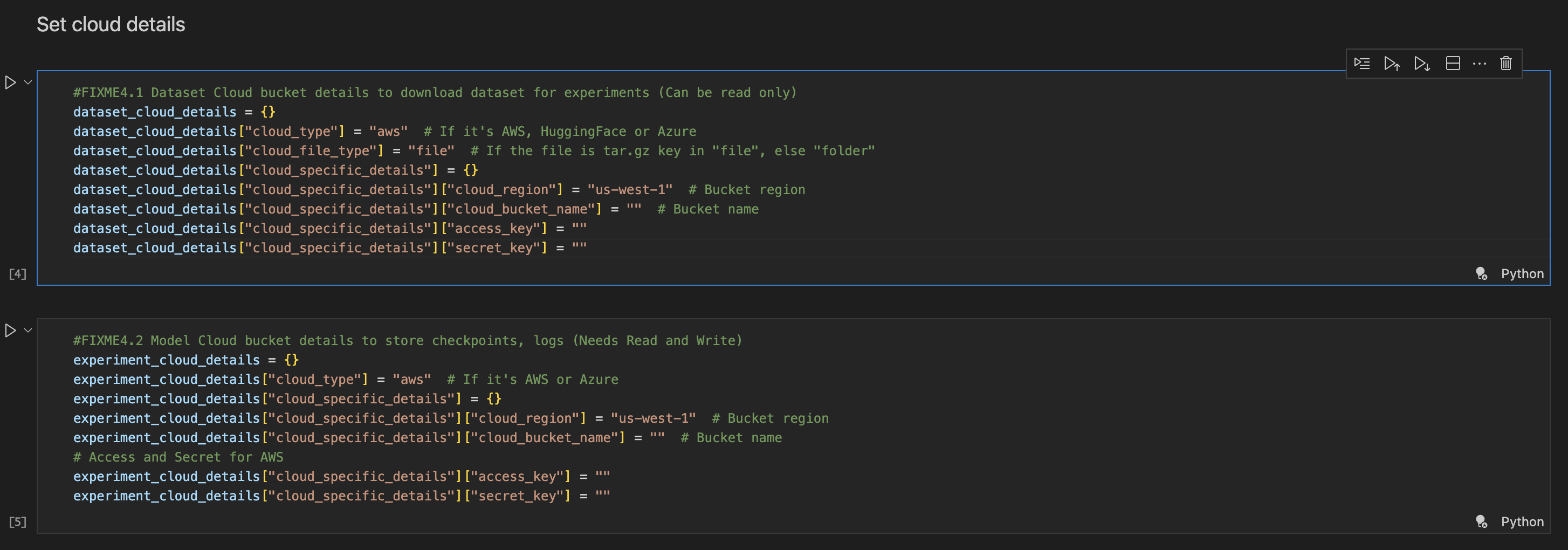
Set the dataset paths.
Each model requires a dataset for different purposes - train, eval, test.
Provide the absoulte path of the dataset relative to the cloud details provided.
If you don’t have the dataset already prepared, view the notebooks at dataset_prepare/ to create the datasets.

Set the NGC API key.
The TAO API requires an NGC API key for authentication and authorization purposes. Get your API key from NGC.

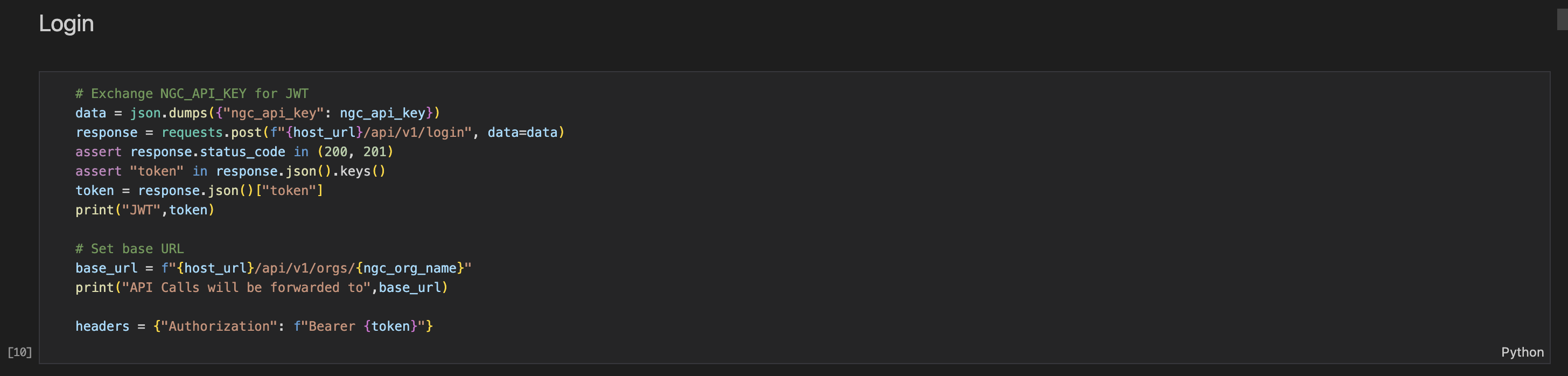
Login to the TAO API service.
It returns a Bearer token that is used for requests headers.
Create datasets.
This returns a dataset id - UUID.
For example, when creating the train dataset, the cloud details entered in previous steps are in an encrypted format.
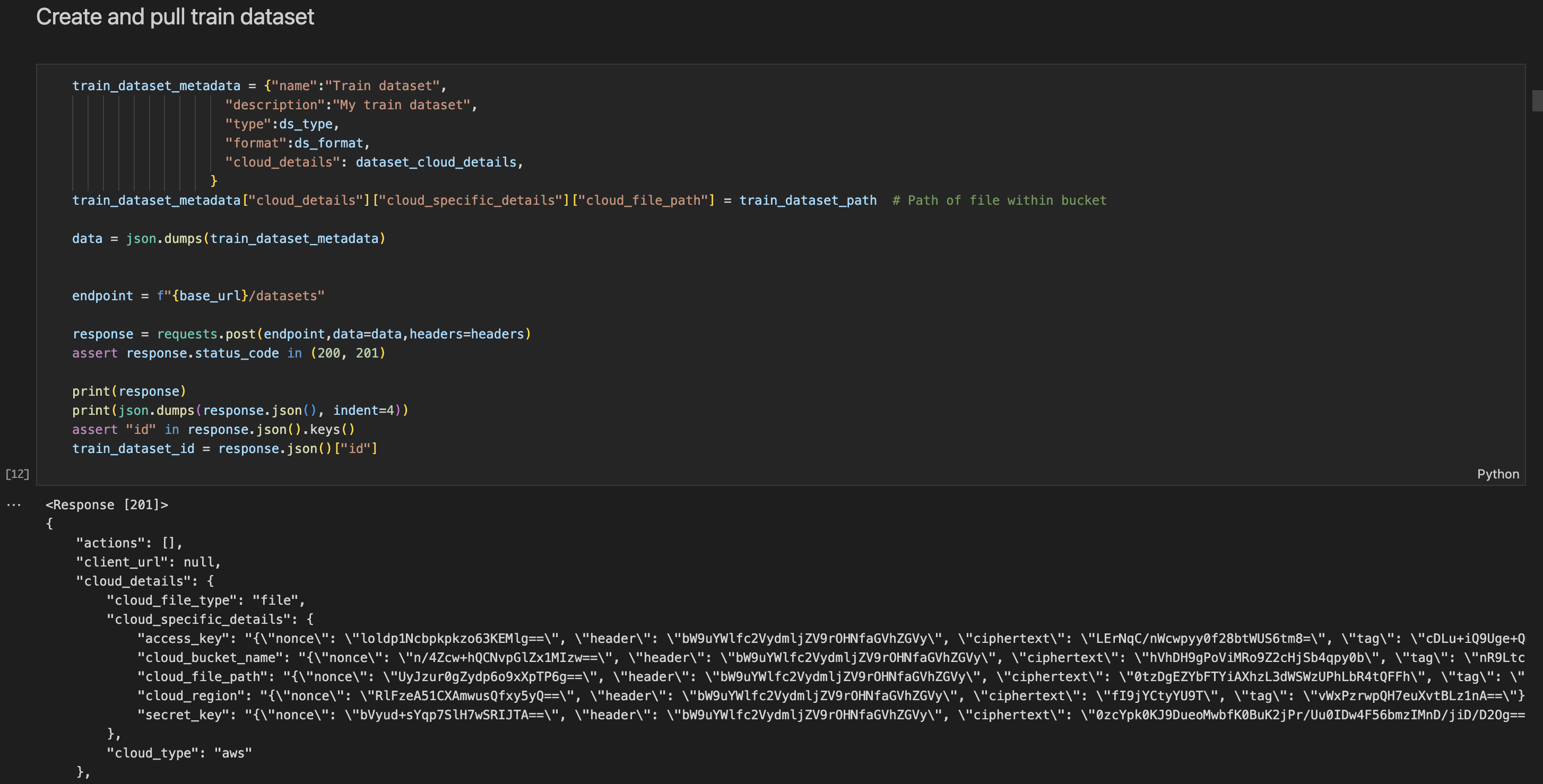
The dataset has other metadata for identification purposes, including name and description. The dataset type and format varies by model and is preset for you in all notebooks.
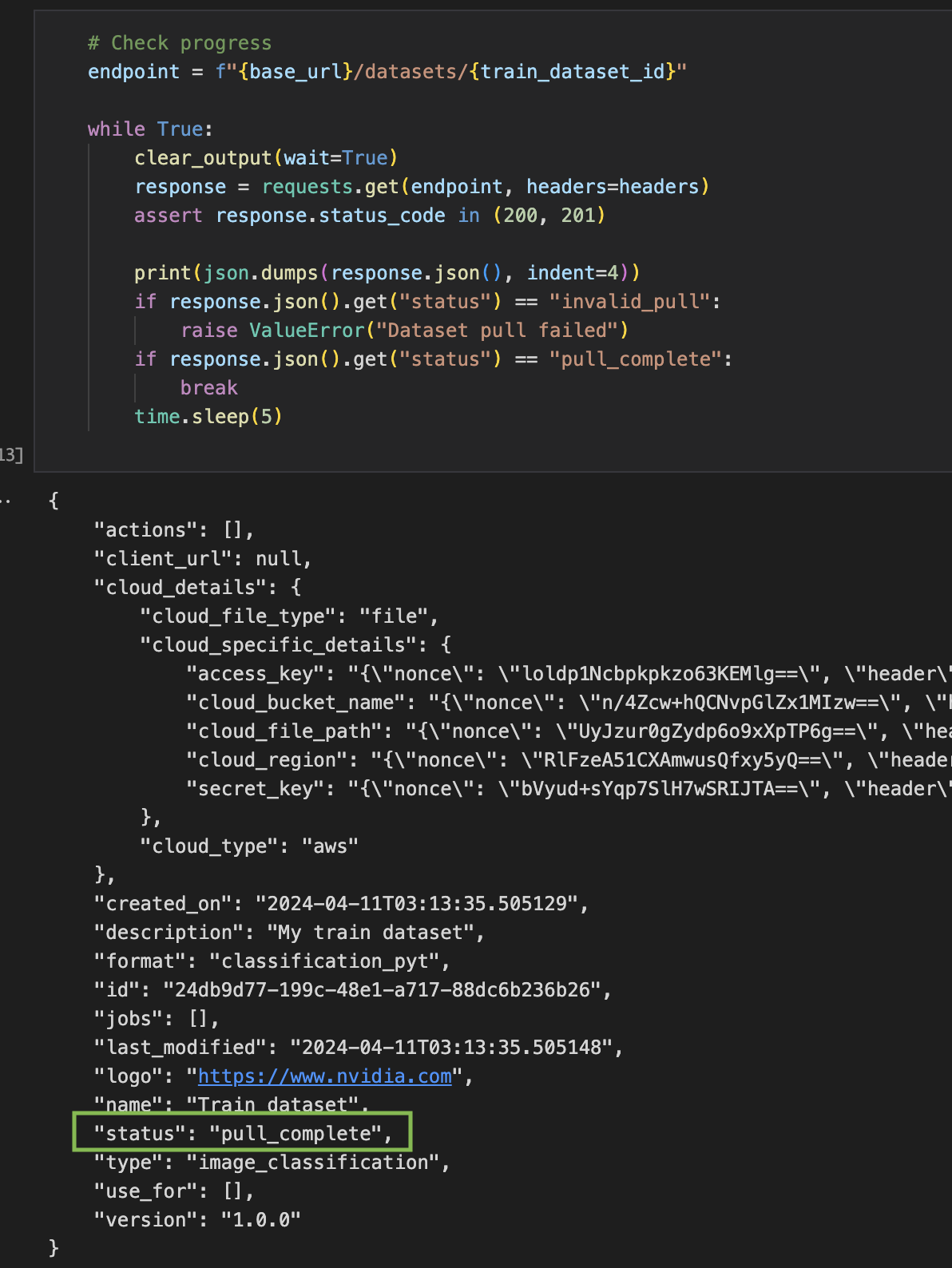
Monitor the status of a dataset.
Pull the dataset to verify that it matches the directory structure required for the chosen model.
The status can be:
starting - when the dataset is just created.
in_progress - the dataset is being downloaded from cloud.
pull_complete - the dataset satisfies the model requirements.
invalid_pull - the dataset folder structure fails the model requirements.
Remove any corrupted images.
You can uncomment this cell that scans through the images in your dataset and removes any corrupted images.

Creating the validation and inference datasets.
Perform the same workflow as you did for the train dataset: Create, monitor, and remove corrupted images to create the validation and test datasets.

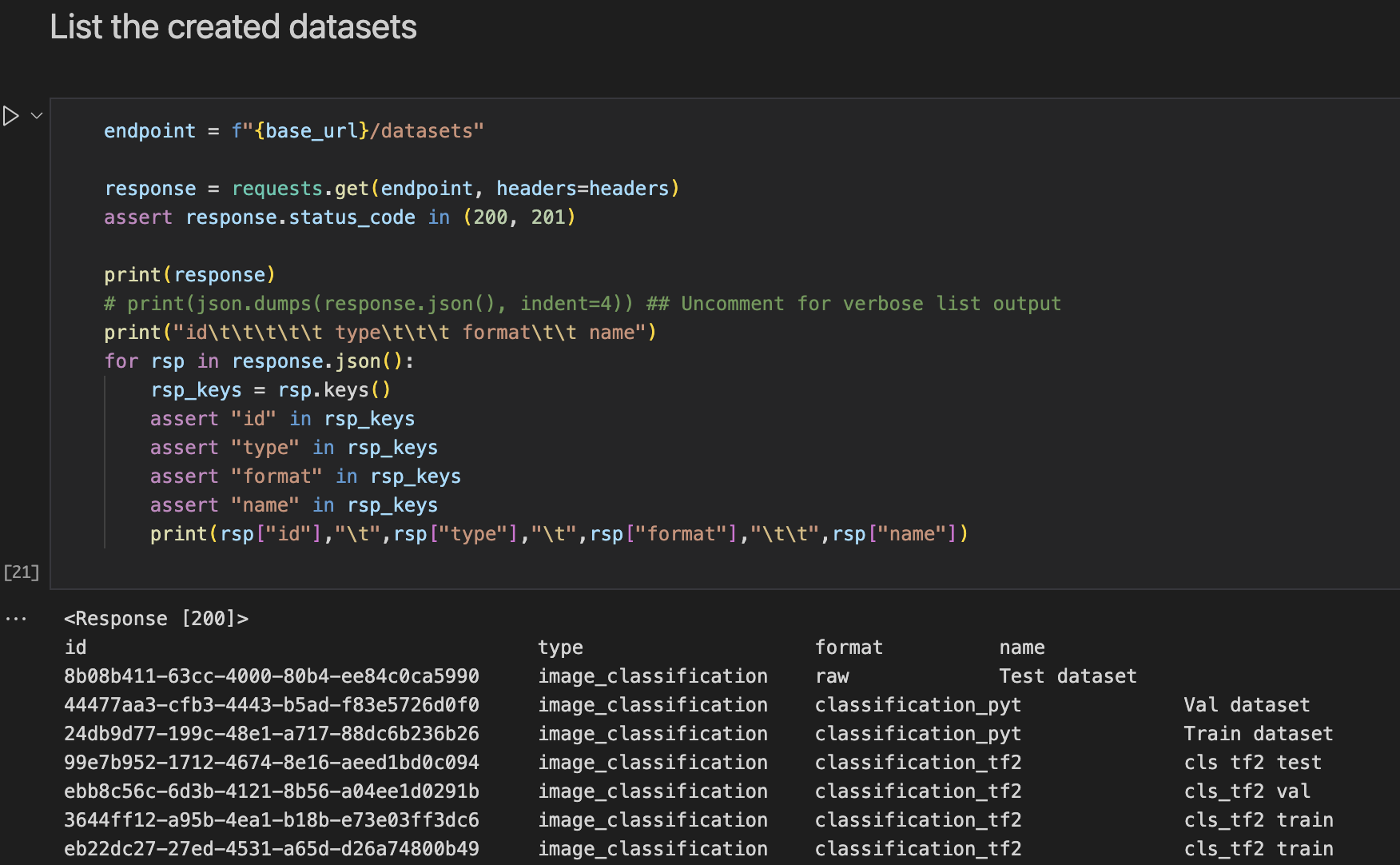
List your datasets.
This cell lists the datasets that you have created with the TAO API service.
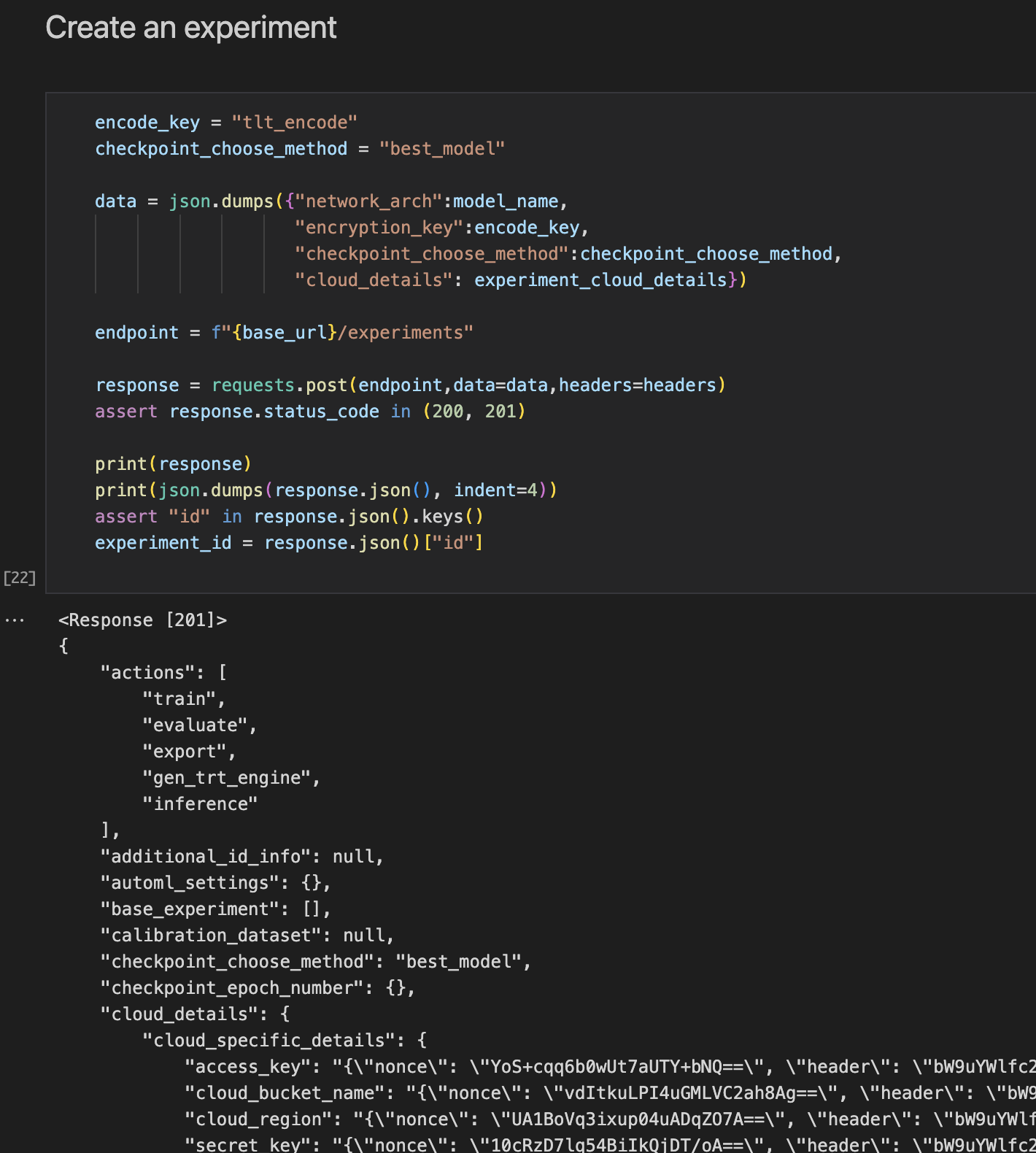
Creating an experiment.
After datasets are created, different workflows can be carried out under an experiment.
This returns a experiment id - UUID.
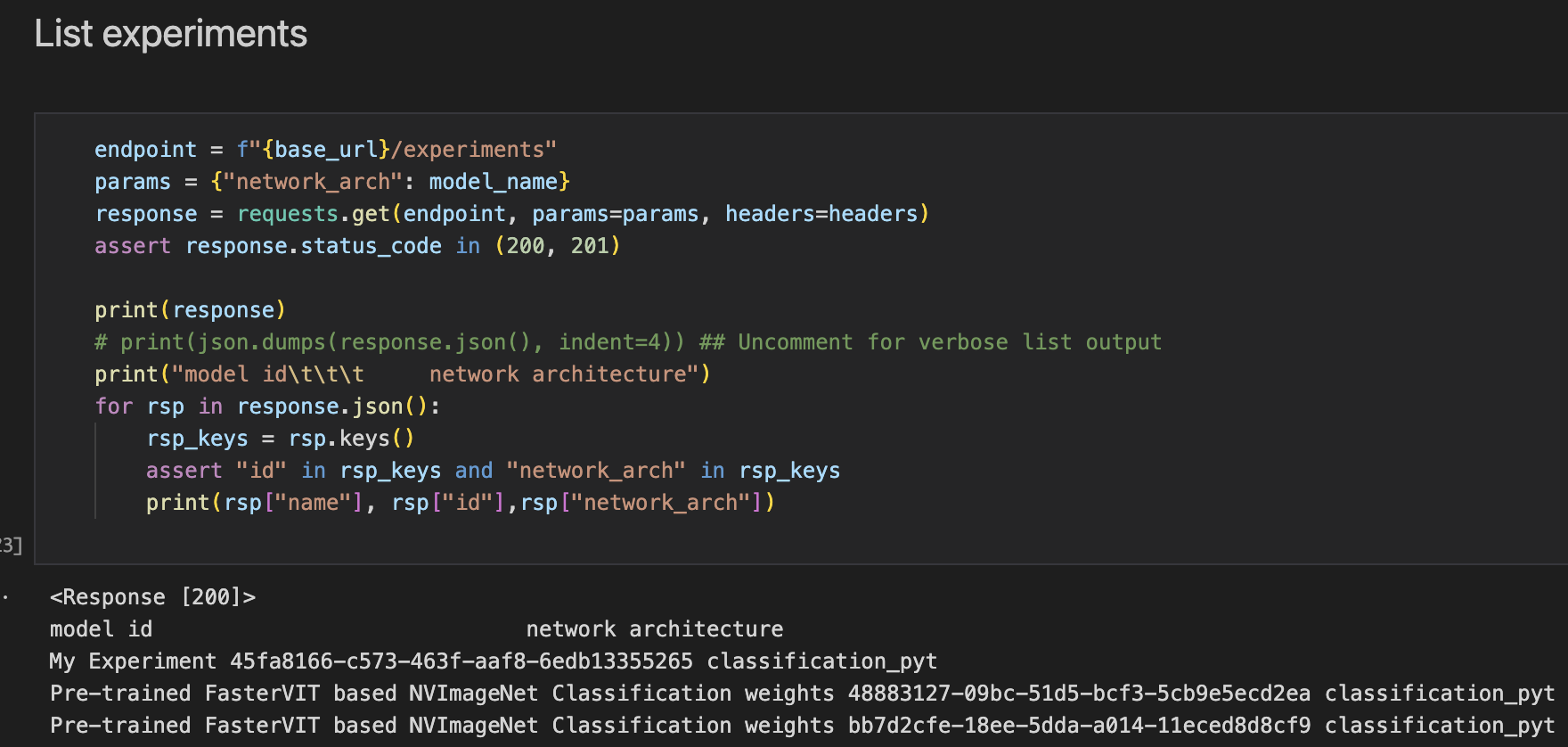
List available experiments.
This cell lists the experiments you have created with the TAO API service.
Assign the dataset to the experiment.
You must assign the datasets created earlier to your experiment for the workflows to be able to access them.
List the base experiments available.
TAO provides a large catalogue of pre-trained models to intialize the training actions with. This cell returns the base-experiments that are available for the model chosen.
Change the default base experiment.
Each model has a default base-experiment set, you can change it to a different string from one of the options from the previos step.

Assign the base experiment to experiment.
After changing the base-experiment, you must patch the experiment with the base-experiment ID.
View AutoML parameters enabled.
This cell lists the hyper-parameters that are enabled for the AutoML experiments by default.

Change AutoML algorithm parameters.
In this cell, you can change the AutoML algorithm specific parameters that control the length of the AutoML training.
See the AutoML docs for more details about the algorithm parameters.
Also, you can add or remove hyper-parameters to the search space.
Get the default config.
For each action, you can get the default configuration setting. This setting is populated based on the model_name and the base-experiment you chose.
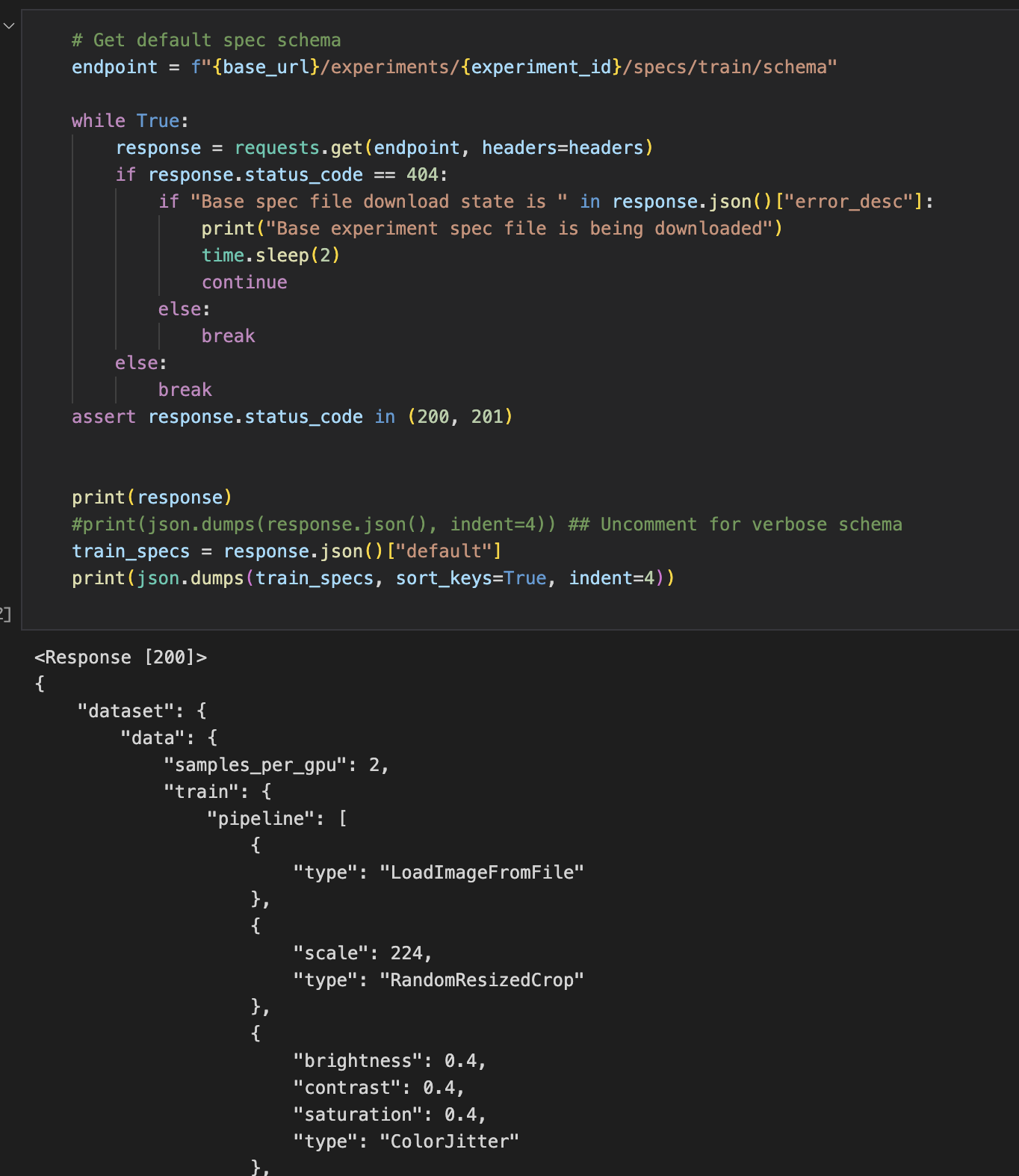
Modify the config.
You can modify the default spec if necessary.

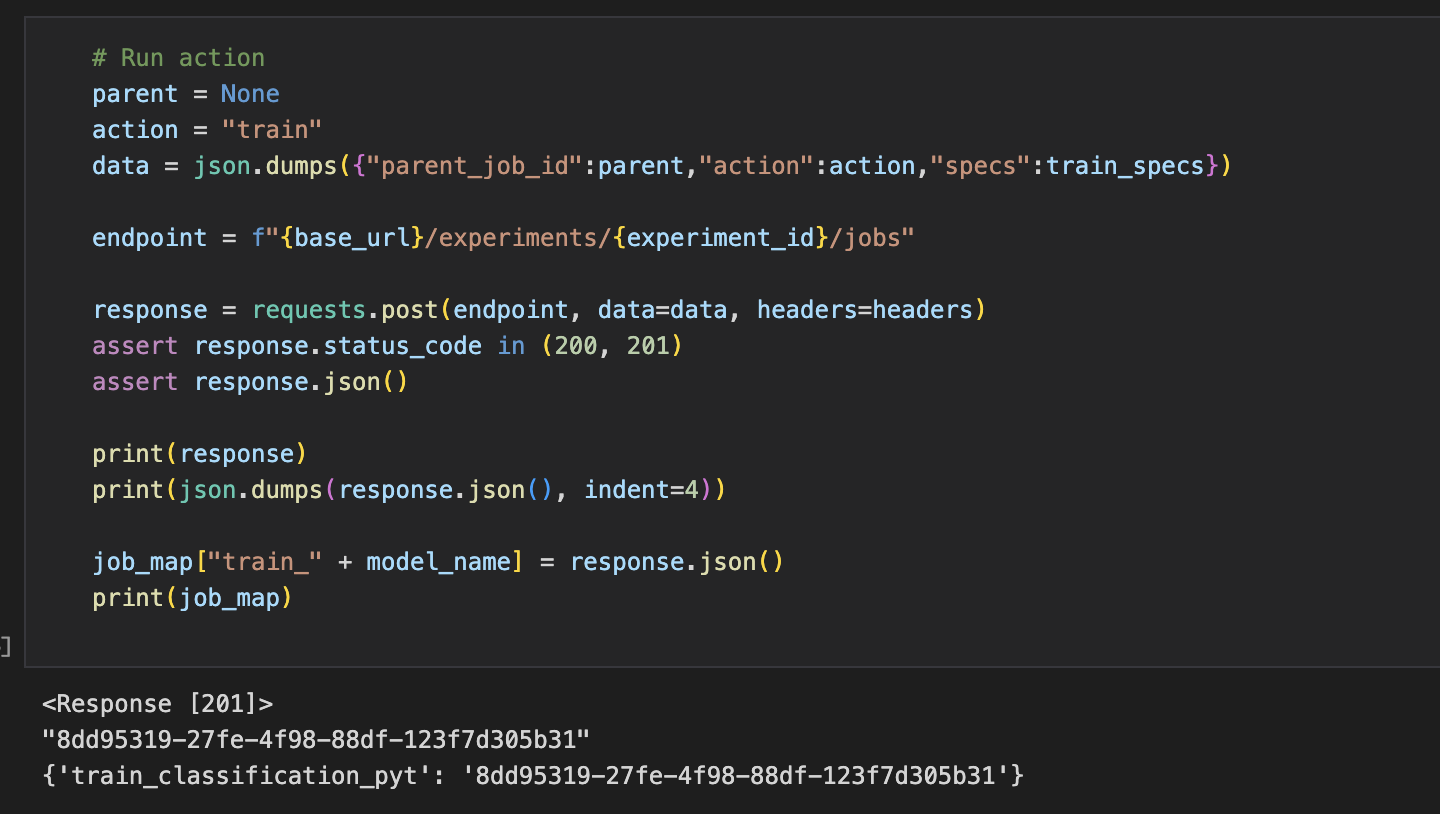
Run the action.
After the specs are ready, you can run the train action. The request body parameters are:
parent_job_id: if you want any other job to be a dependency to this job. For example, for the evaluate process, if you set parent_job_id as train action’s job_id, then only after the execution of train is complete, evaluate begins it’s execution.
action: name of the action.
specs: configuration setting for this action.
This returns a job id - UUID.
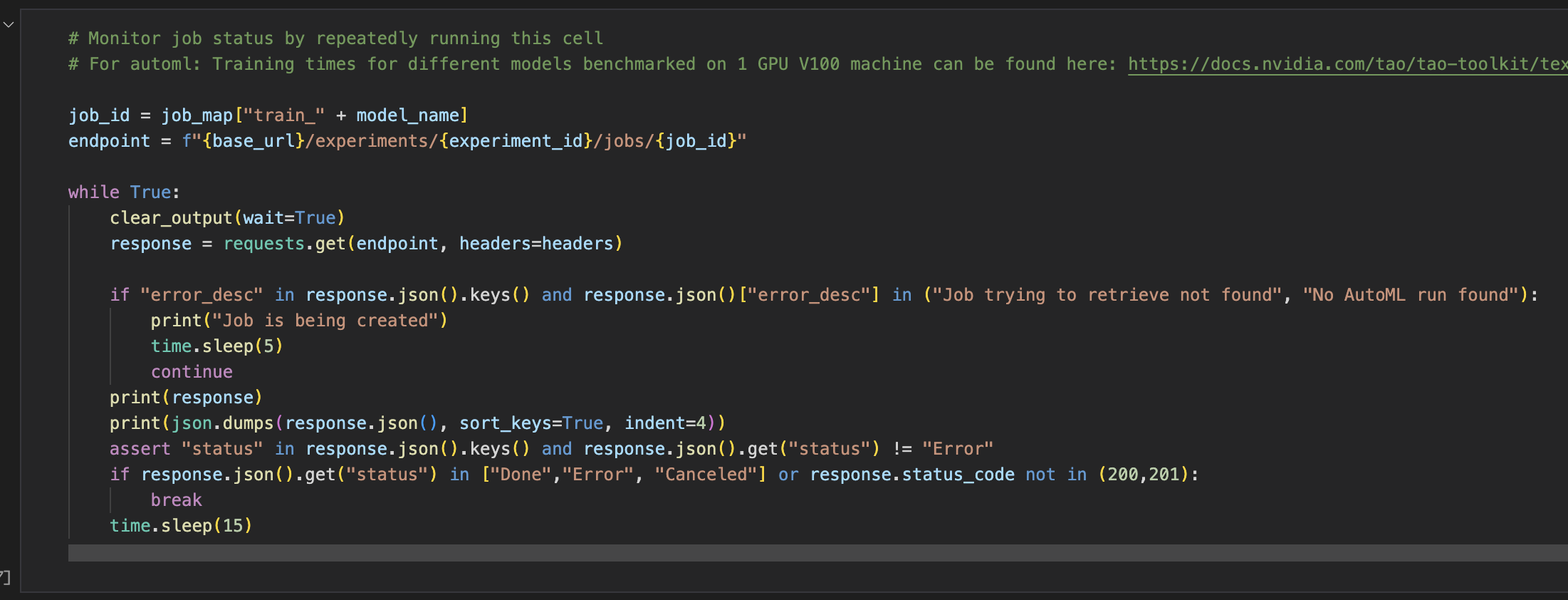
Monitor a job.
Based on the job id returned in the previous step, we continuously poll the job status until it’s in one of the terminal states of Done or Error.
It also prints out other details, like ETA, latest status message of the training job, etc. For AutoML, it prints out stats like current experiment number, remaining epochs, etc.
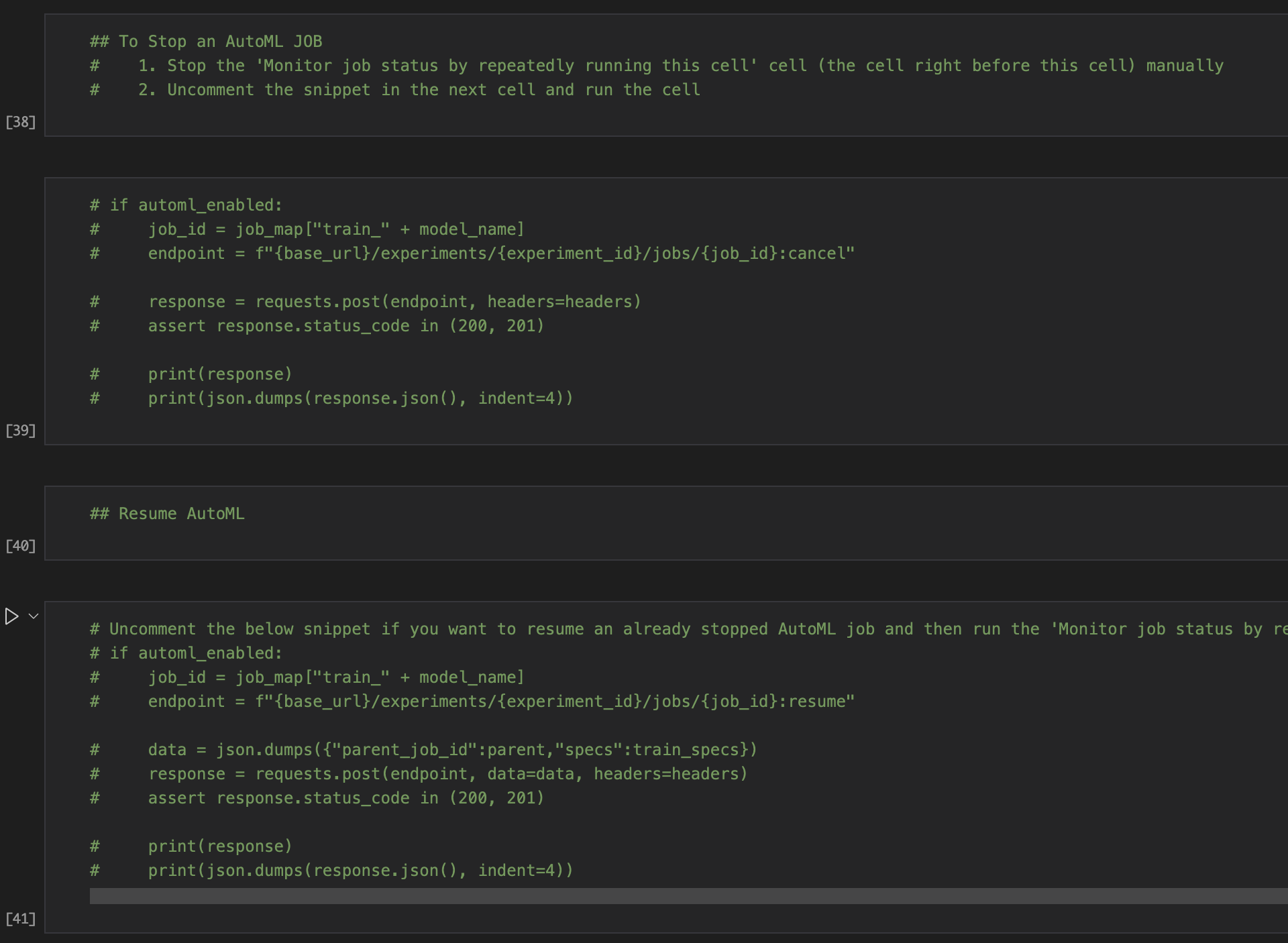
Pause and resume the train job.
TAO API provides an option where you can pause a training job or AutoML job and resume it later from the epoch where the training was stopped.
Get info about the latest and best checkpoints.
After training is complete, review the checkpoint number that corresponds to the latest and the best model. Best model is the one that achieves the highest accuracy during the training.
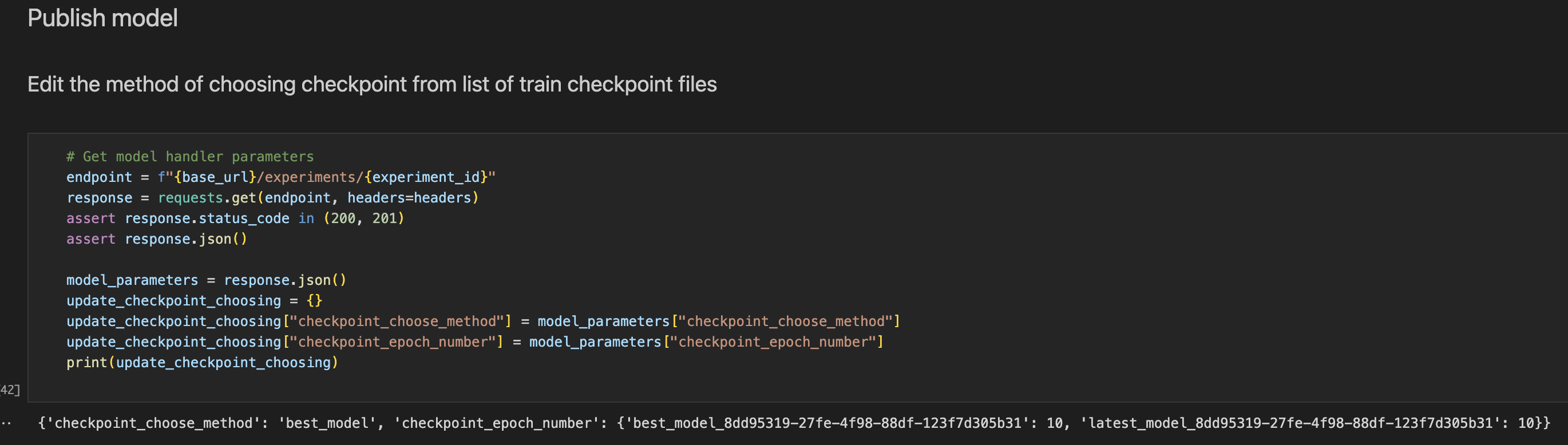
Change the checkpoint choosing technique.
For subsequent actions that depend on training job files, you can choose the file that needs to be used based on the following methods:
latest_model - picks the checkpoint that has the highest epoch number.
best_model - picks the checkpoint that corresponds to the best accuracy.
from_epoch_number - picks the checkpoint that to a particular epoch number.
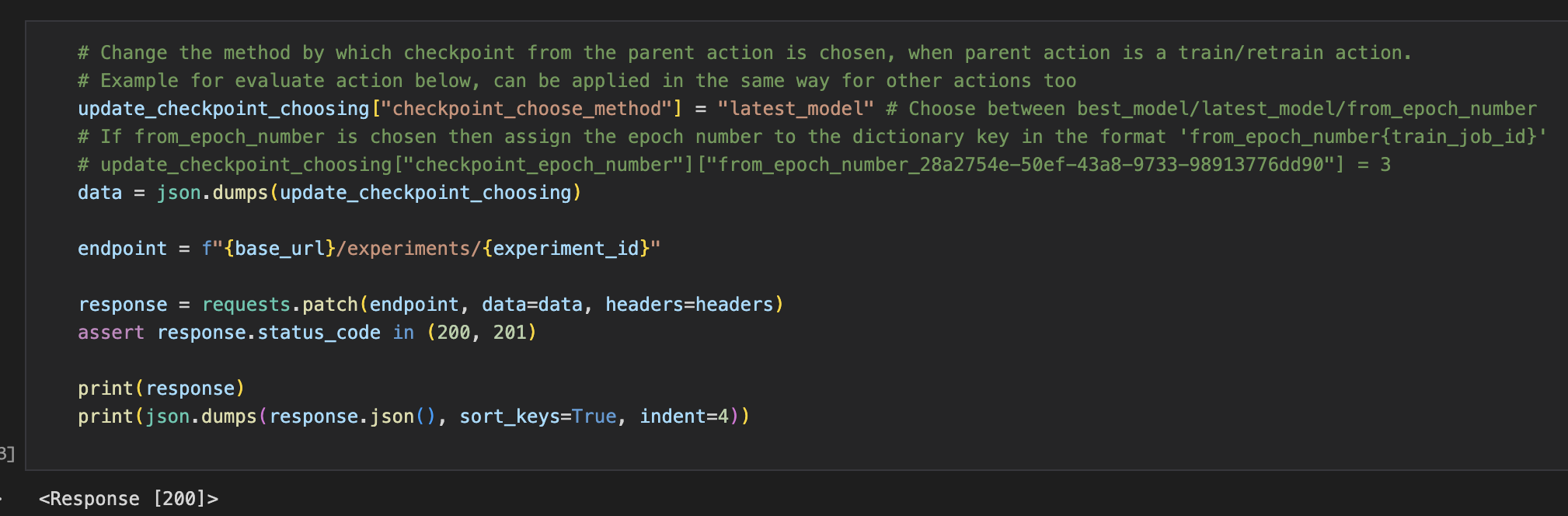
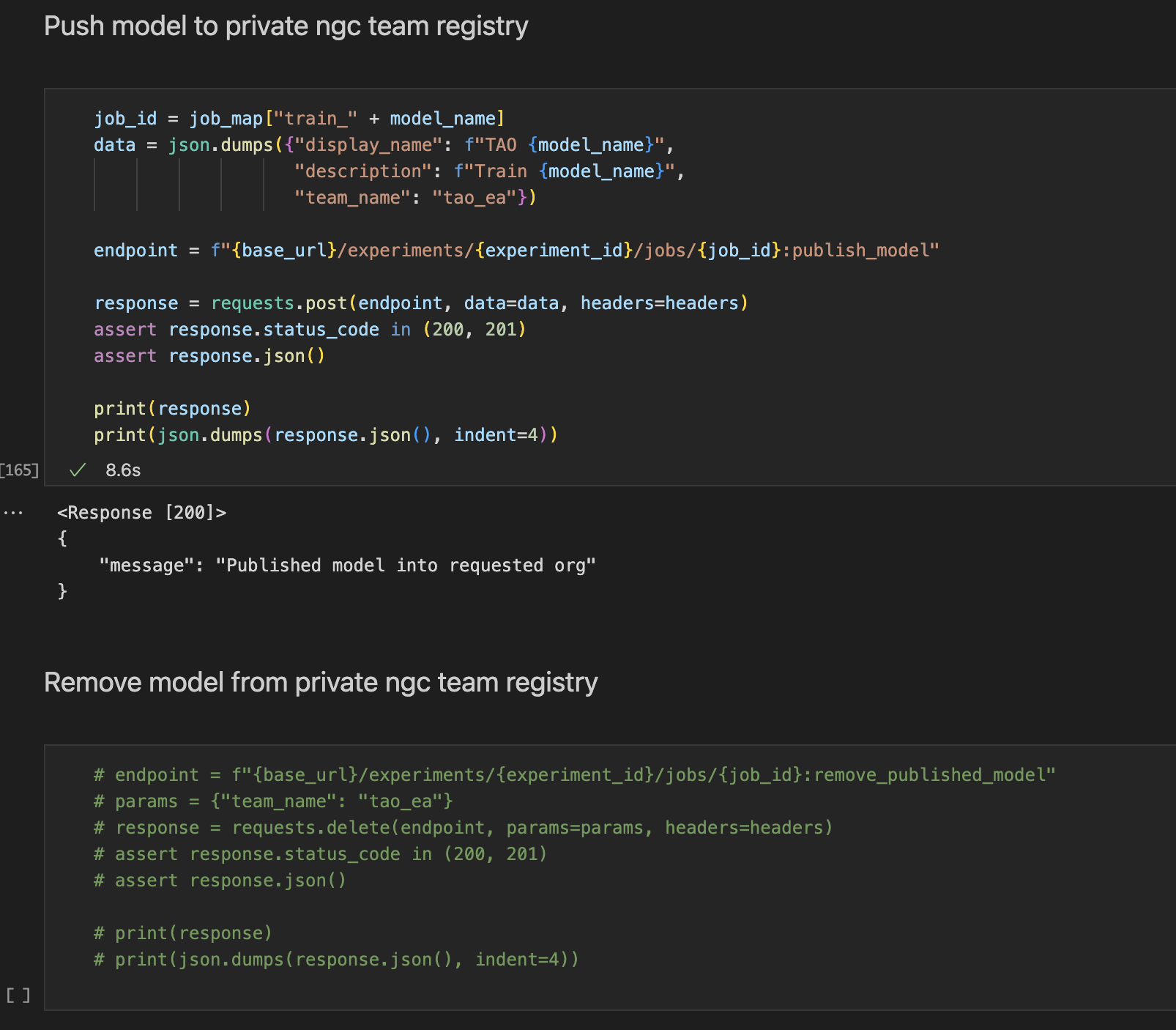
Publish the model to the NGC private registry.
This cell pushes the model file from train job to the NGC model registry based on the org and team name chosen.
Other actions.
The previous set of options (get spec - modify spec - run action - monitor) for the train job can be extended to other jobs:
evaluate
prune-retrain
export
trt engine generation
tao inference
trt inference

Delete the experiment.
After you have tried multiple workflows and actions with an experiment, you can wipe it’s existence from the API service.

Delete the datasets.
After you have tried multiple workflows and actions with an experiment, you can remove the datasets existence associated with the experiment from the API service.
TAO-CLI example
The above workflow for API notebooks is applicable for the tao-client notebooks also.
Instead of Python requests to carry out the intended actions, you use a command line interface to achieve the same results.

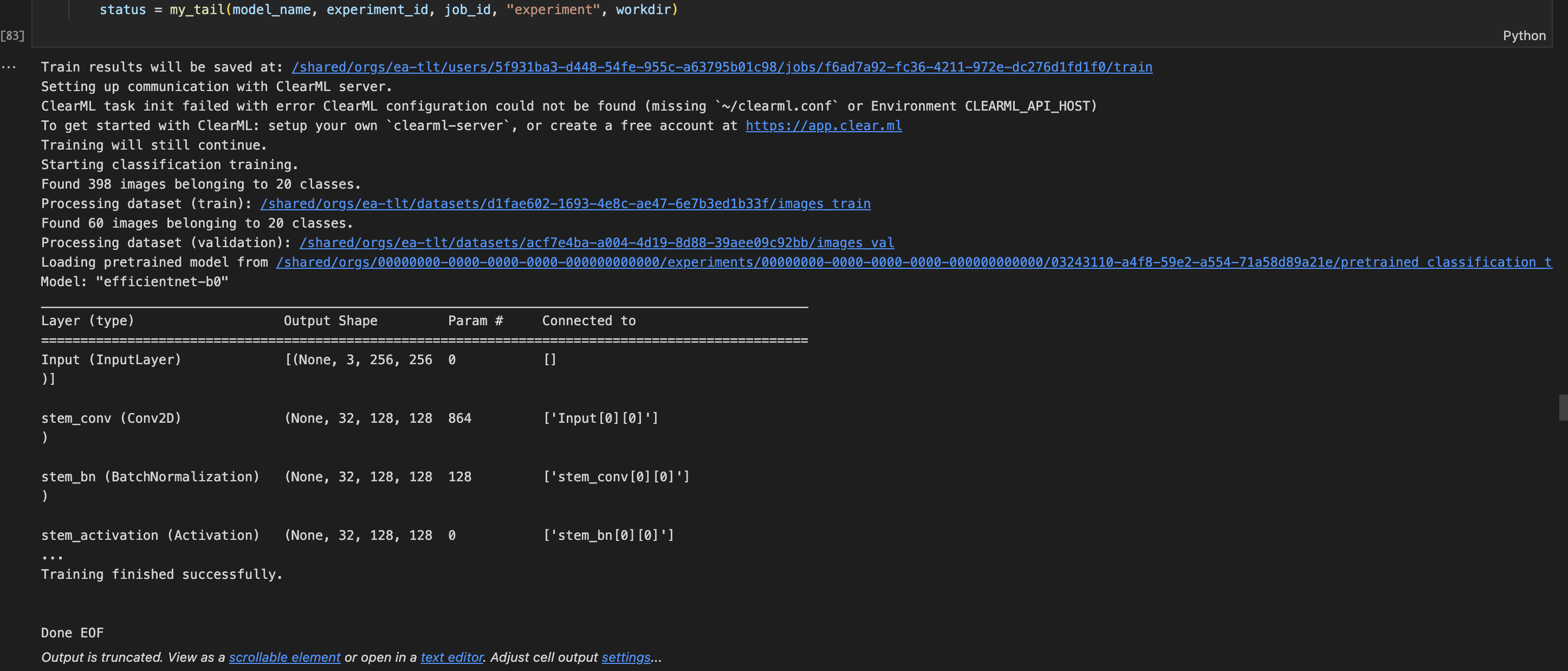
TAO job monitor outcome.
One other difference between tao-client and API notebooks is the job monitor cell. In client notebooks, you can see the logs of the jobs, wheras in API notebooks you see the JSON response from the request endpoint.