In this section we compare VPI's performance with other well-known Computer Vision libraries. Performance numbers were collected following the method described in Benchmarking Method.
Benchmarking was done on NVIDIA® Jetson AGX Orin™ devices, with clock frequencies maxed out.
The numbers show that VPI provides a significant speed up in many use cases.
OpenCV
Comparison made with OpenCV 4.5.4 built with NVIDIA® CUDA® support enabled. This version matches the OpenCV version shipped with NVIDIA® JetPack™.
All plots use logarithmic scale due to the large difference between different algorithm performance numbers.
CPU Performance
Both OpenCV and VPI measurements are done using one dispatch thread. Many OpenCV algorithms once dispatched make use of multiple CPU cores during execution, but some others might not. This is a contrast with VPI, where all available CPU cores are always used.
The main implication is that the OpenCV algorithms that only use one core can have several instances running in parallel, up to the number of CPU cores, without affecting their performance. On the other hand, VPI CPU algorithm performance scales linearly with the number of parallel instances. The advantage for VPI in this case is that performance increases linearly with the number of additional cores added, whereas OpenCV's single-thread algorithms performance will be unchanged.
Jetson AGX Orin CPU with twelve.
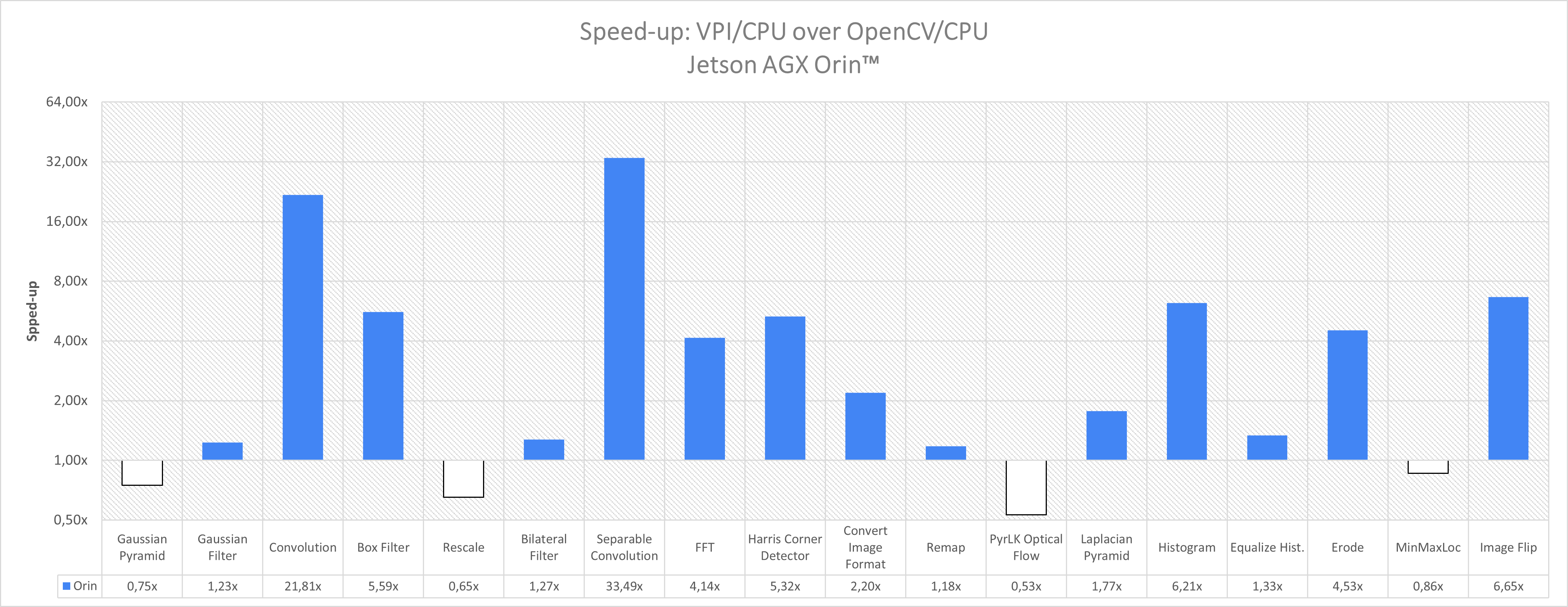
| Algorithm | Parameters | OpenCV 4.5.4 CPU | VPI 2.0 CPU | Speed-up |
|---|---|---|---|---|
| Gaussian Pyramid | 1920x1080 U8 scale=0.5, nlevels=5 | 0.299 ms | 0.399 ms | 0.75x |
| Gaussian Filter | 1920x1080 U8 3x3 | 0.251 ms | 0.204 ms | 1.23x |
| Convolution | 1920x1080 U8 3x3 | 6.871 ms | 0.315 ms | 21.81x |
| Box Filter | 1920x1080 U8 3x3 clamp | 1.520 ms | 0.272 ms | 5.59x |
| Rescale | 1280x720 to 1920x1080, RGBA8 linear interp. | 4.260 ms | 6.542 ms | 0.65x |
| Bilateral Filter | 1920x1080 U8 3x3 | 2.012 ms | 1.579 ms | 1.27x |
| Separable Convolution | 1920x1080 U8 11x11 | 18.250 ms | 0.545 ms | 33.49x |
| FFT | 626x626 Real->Complex | 81.060 ms | 19.560 ms | 4.14x |
| Harris Corner Detector | 1920x1080 U8 grad=3x3, win=3x3 | 39.400 ms | 7.410 ms | 5.32x |
| Convert Image Format | 1920x1080 NV12_ER to RGBA8 | 1.866 ms | 0.850 ms | 2.20x |
| Remap | 1920x1080 RGBA8 dense, linear interp. | 6.280 ms | 5.320 ms | 1.18x |
| Pyramidal LK Optical Flow | 1920x1080 U8 3x3, 3 levels, win=11x11 | 1.610 ms | 3.030 ms | 0.53x |
| Laplacian Pyramid | 1920x1080 U8 -> S16, scale=0.5, 5 levels | 5.100 ms | 2.880 ms | 1.77x |
| Histogram | 1920x1080 U8, [0,256) range, 256 bins | 1.35 ms | 3.3 ms | 0.4x |
| Equalize Histogram | 1920x1080 U8 | 0.452 ms | 0.339 ms | 1.33x |
| Erode | 1920x1080 U8 3x3 | 0.530 ms | 0.117 ms | 4.54x |
| Min/Max Location | 1920x1080 U8 2 locations, min+max | 0.241 ms | 0.280 ms | 0.86x |
| Image Flip | 1920x1080 RGBA8 both | 1.630 ms | 0.245 ms | 6.65x |
CUDA Performance
Both OpenCV and VPI benchmarking use one stream for algorithm execution.
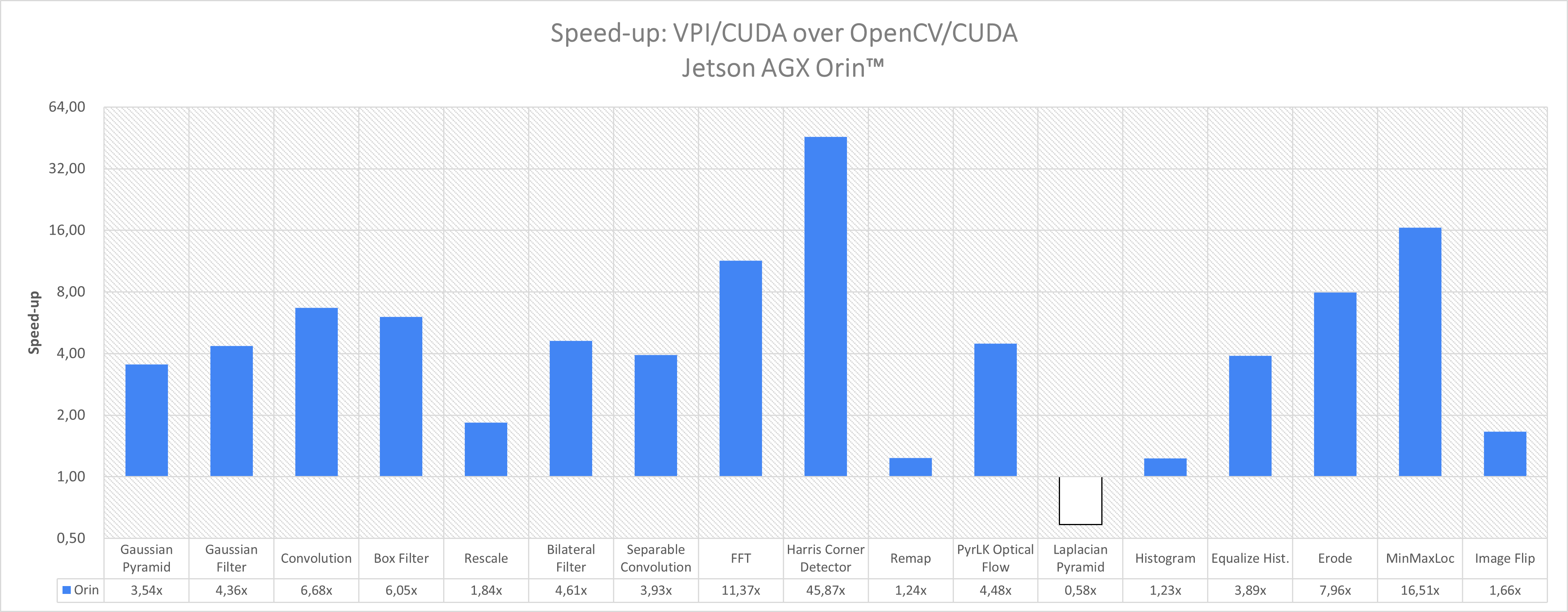
| Algorithm | Parameters | OpenCV 4.5.4 CUDA | VPI 2.0 CUDA | Speed-up |
|---|---|---|---|---|
| Gaussian Pyramid | 1920x1080 U8 scale=0.5, 5 levels | 0.143 ms | 0.040 ms | 3.54x |
| Gaussian Filter | 1920x1080 U8 3x3 | 0.141 ms | 0.035 ms | 4.36x |
| Convolution | 1920x1080 U8 3x3 | 0.228 ms | 0.034 ms | 6.68x |
| Box Filter | 1920x1080 U8 3x3 clamp | 0.205 ms | 0.045 ms | 6.06x |
| Rescale | 1280x720 -> 1920x1080 RGBA8, linear interp. | 0.114 ms | 0.078 ms | 1.84x |
| Bilateral Filter | 1920x1080 U8 3x3 | 0.295 ms | 0.064 ms | 4.61x |
| Separable Convolution | 1920x1080 U8 11x11 | 0.220 ms | 0.056 ms | 3.93x |
| FFT | 626x626 Real->Complex | 2.162 ms | 0.190 ms | 11.37x |
| Harris Corner Detection | 1920x1080 U8 grad=3x3, win=3x3 | 19.480 ms | 0.425 ms | 45.87x |
| Remap | 1920x1080 RGBA8, dense, linear interp. | 0.246 ms | 0.199 ms | 1.24x |
| Pyramidal LK Optical Flow | 1920x1080 RGBA8 dense, linear interp. | 0.949 ms | 0.212 ms | 4.48x |
| Laplacian Pyramid | 1920x1080 U8 -> S16, scale=0.5, 5 levels | 0.355 ms | 0.608 ms | 0.58x |
| Histogram | 1920x1080 U8, [0,256) range, 256 bins | 0.041 ms | 0.033 ms | 1.23x |
| Equalize Histogram | 1920x1080 U8 | 0.350 ms | 0.090 ms | 3.89x |
| Erode | 1920x1080 U8 3x3 | 0.246 ms | 0.031 ms | 7.96x |
| Min/Max Location | 1920x1080 U8 2 locations, min+max | 0.700 ms | 0.042 ms | 16.51x |
| Image Flip | 1920x1080 RGBA8 both | 0.155 ms | 0.093 ms | 1.66x |