Building a Bot using NVIDIA RAG Examples#
In this section, let’s build a bot that uses NVIDIA RAG Examples pipeline to answer questions.
Similar to the tutorial for LangChain-based Bots, we will use a Plugin to interact with the RAG server. However, in this tutorial we will use a pre-built Plugin that works out of the box. This plugin can be connected to the Chat Controller or the Chat Engine. Refer to the plugin server architecture section for more information.
The minimal file structure of the RAG bot looks like this:
my_bots └── rag_bot └── plugin_config.yaml └── speech_config.yaml └── model_config.yaml
Connecting Chat Controller to the RAG Plugin#
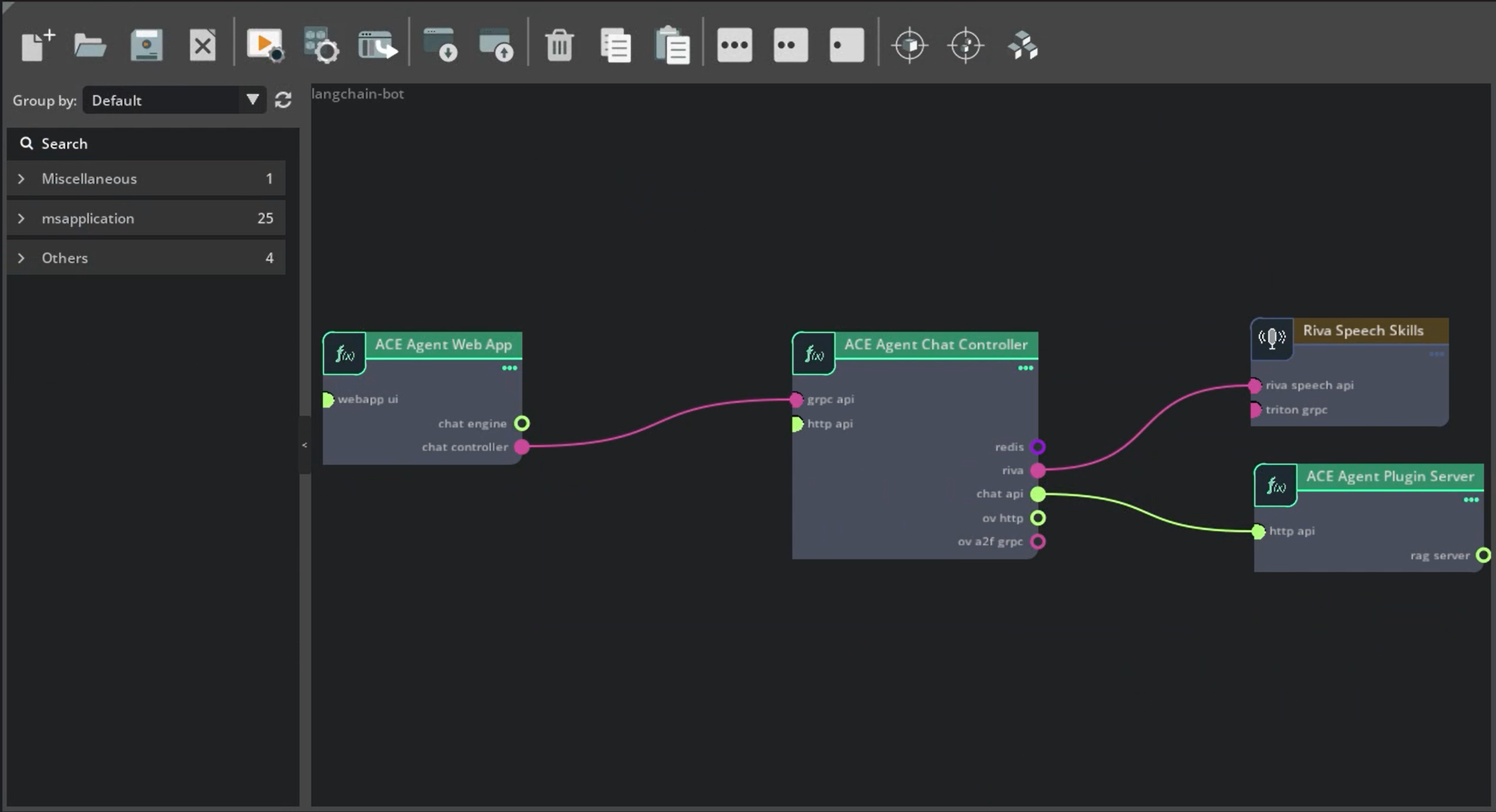
Deploy the RAG examples by following the instructions in the sample RAG bot. You can also deploy RAG Server in Kubernetes using NVIDIA Enterprise RAG LLM Operator.
Update
plugin_config.yamlwith the pre-built RAG Plugin. If the RAG server was deployed at a URL other than the default, update theparameterssection of the plugin config file.config: workers: 1 timeout: 30 plugins: - name: rag parameters: RAG_SERVER_URL: "http://localhost:8081"
If you want to review the RAG plugin, refer to the
./samples/rag_botsample bot directory.Copy the
model_config.yamlandspeech_config.yamlfiles fromsamples/chitchat_bot. They represent the common settings for a speech pipeline.Update the server URL in the
dialog_managercomponent to point to the pre-built RAG Plugin we defined in the previous step.dialog_manager: DialogManager: server: "http://localhost:9002/rag" use_streaming: true
With this change, the Chat Controller will directly call the
/chatand/eventendpoints of the Plugin server.Deploy the bot.
Set the environment variables required for the
docker-compose.ymlfile.export BOT_PATH=./my_bots/rag_bot/ source deploy/docker/docker_init.sh
Deploy the Riva ASR and TTS speech models.
docker compose -f deploy/docker/docker-compose.yml up model-utils-speech
Deploy the Plugin server with RAG plugin.
docker compose -f deploy/docker/docker-compose.yml up --build plugin-server -d
Deploy the Chat Controller microservice with the gRPC interface.
docker compose -f deploy/docker/docker-compose.yml up chat-controller -d
Interact with the bot using the Speech sample frontend application.
docker compose -f deploy/docker/docker-compose.yml up frontend-speech
Notice that we are not deploying the Chat Engine container at all.
You can interact with the bot using your browser at
http://<YOUR_IP_ADDRESS>:9001.
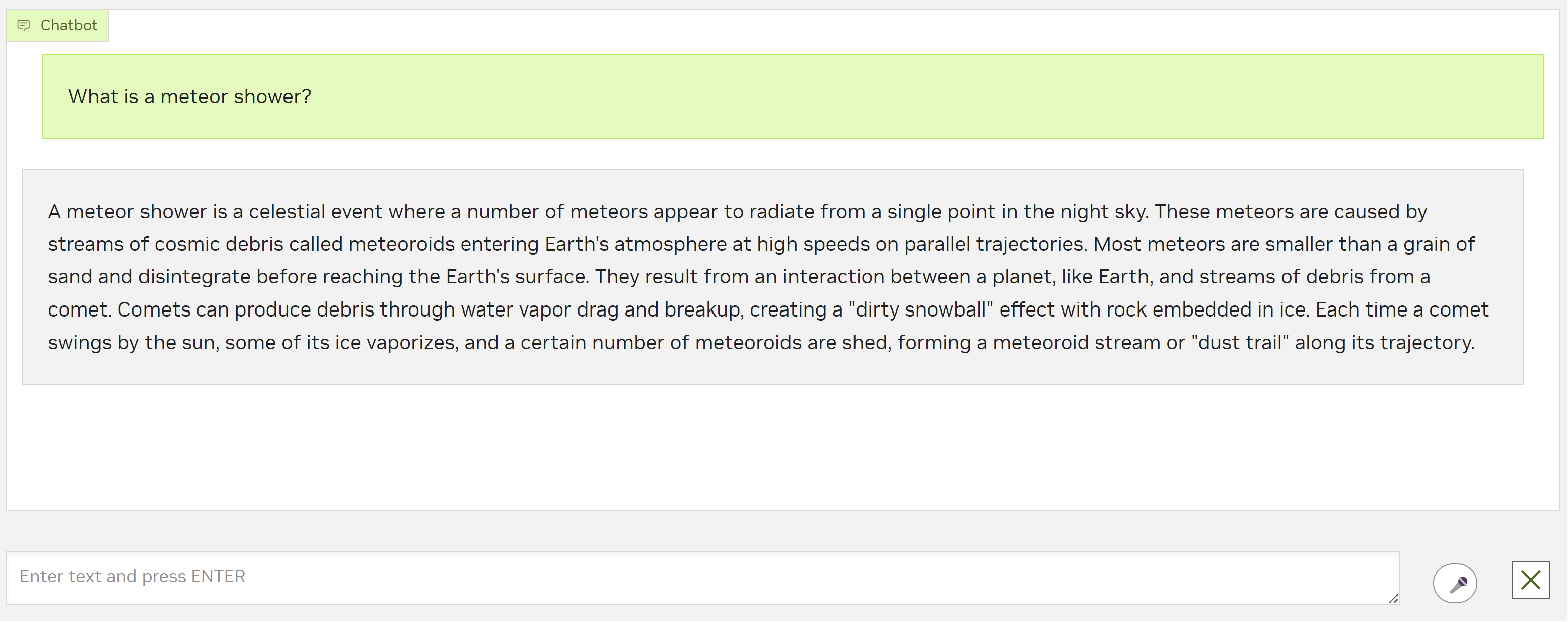
Here’s an example snippet:
Connecting the Plugin to the Chat Engine#
You can add guardrails to the bot or add any custom logic in Colang by creating the configurations needed for the Chat Engine and connecting the Plugin server to the Chat Engine using the Chat Engine Server Architecture.
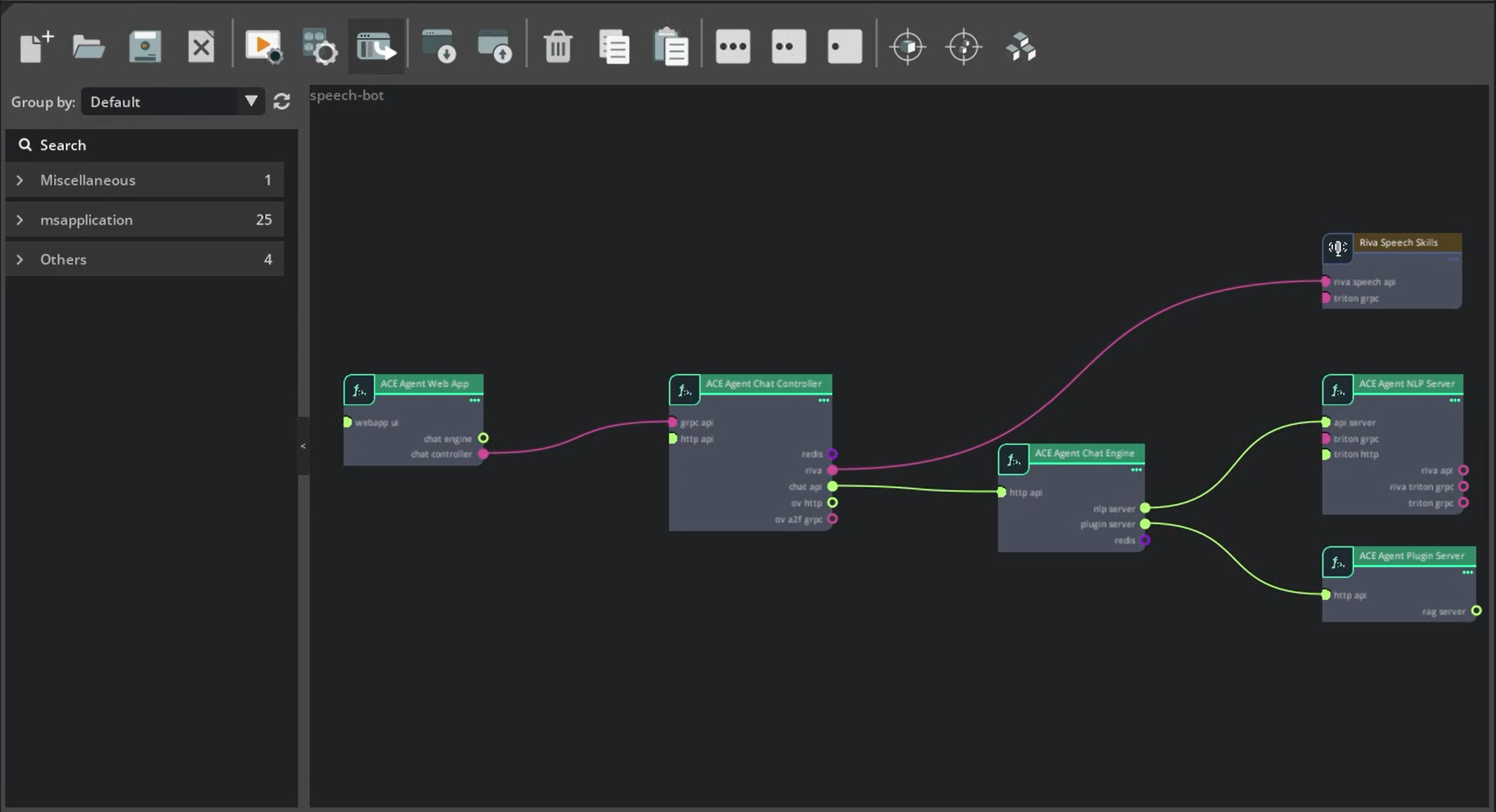
Creating the Bot and Colang Configurations#
bot_config.yaml is the configuration entry point for any bot. Let’s create this file and add a few important configuration parameters.
Give the bot a name. In
bot_config.yaml, you need to add a unique name for the bot. Let’s name the botnvidia_rag_bot.bot: nvidia_rag_bot
All the intelligence in our bot will be present in the RAG server. Since our Colang configs are only meant to route the queries to the plugin, let’s keep the model section empty.
models: []
Create a Colang file called
flows.co, which will contain all the Colang logic. Let’s updateflows.coto route all queries to the RAG plugin.define flow user ... $answer = execute chat_plugin(\ endpoint="rag/chat",\ ) bot respond define bot respond "{{$answer}}"
The above flow routes all user utterances to a POST endpoint called
/generatein a plugin calledrag. It passes the user’s question as well as asession_idto the endpoint as request parameters.Note
If you want to add more complicated logic in Colang, you must update
flows.coand possibly the bot config file according to your use case. Refer to Using Colang for more information.Change the
serverURL for thedialog_managercomponent to the Chat Engine component inspeech_config.yaml.dialog_manager: DialogManager: server: "http://localhost:9000" use_streaming: true
Testing the Bot#
Run the bot in gRPC Interface using the Docker Environment.
Set the environment variables required for the
docker-compose.ymlfile.export BOT_PATH=./my_bots/rag_bot/ source deploy/docker/docker_init.sh
Deploy the Riva ASR and TTS speech models.
docker compose -f deploy/docker/docker-compose.yml up model-utils-speech
Deploy the ACE Agent microservices. Deploy the Chat Controller, Chat Engine, Plugin server, and NLP server microservices. The NLP server will not have any models deployed for this bot.
docker compose -f deploy/docker/docker-compose.yml up --build speech-bot -d
Interact with the bot using the Speech sample frontend application.
docker compose -f deploy/docker/docker-compose.yml up frontend-speech
You can interact with the bot using your browser at
http://<YOUR_IP_ADDRESS>:9001.