Kubernetes & Omniverse Animation Pipeline Workflow#
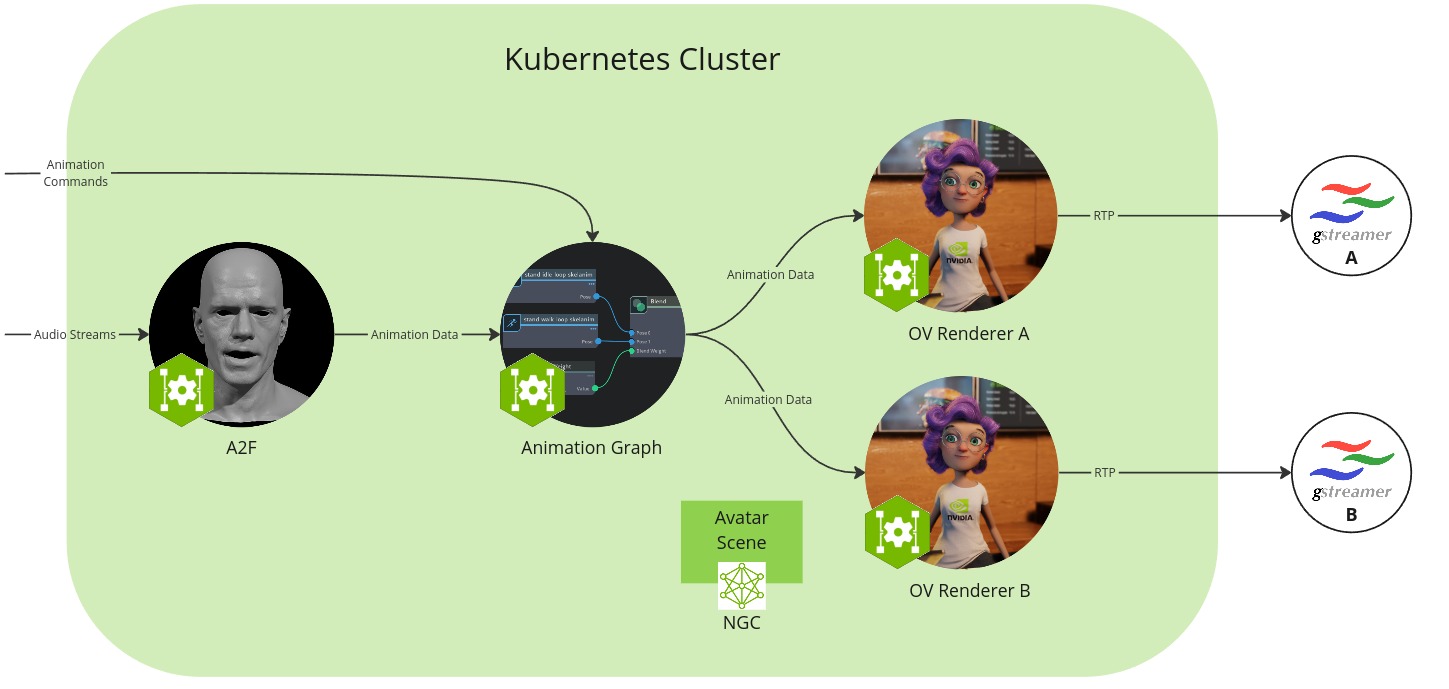
In this setup you will run the microservices in a Kubernetes cluster that supports two independent avatar animation stream instances.
The workflow configuration consists of the following components:
Audio2Face-3D microservice: converts speech audio into facial animation, including lip syncing.
Animation Graph microservice: manages and blends animation states.
Omniverse Renderer microservice: renderer that visualizes the animation data based on the loaded avatar scene.
Gstreamer client: captures and shows image and audio streaming data as user front end.
Avatar scene: Collection of 3D scene and avatar model data that is shared between the animation graph and Omniverse renderer microservices and pulled from the NGC resource.
Prerequisites#
Before you start make sure to have installed and checked all prerequisites in the Development Setup, in particular following the prerequisites of UCS Tools.
Additionally, this section assumes that the following prerequisites are met:
You have a Kubernetes cluster available
You have installed Kubectl
You have installed Helm
You have access to NVAIE, which is required to download the relevant microservices
Note
Note that driver issues have been reported with
minikubeandmicrok8sversions1.29and1.30. If you encounter the errorCuda failure: CUDA driver version is insufficient for CUDA runtime version, consider switching tomicrok8s 1.24, which has been verified to work.
Finally, you need access access to the public NGC catalog, which is required to download the Avatar Configurator.
Hardware Requirements#
This guide assumes you have access to enough GPU resources. A single renderer will consume up to 8 GB of GPU memory (avatar scene dependent). To run two renderers, as shown in the pipeline, we recommend to use two GPUs. Alternatively, you can configure the setup to run only one renderer on a single GPU (see Adapt UCS App for Single Renderer & GPU).
Each component has its own hardware requirements. The requirements of the workflow are the sum of its components.
Audio2Face-3D microservice
Animation Graph microservice
Omniverse Renderer microservice
The actual hardware requirements depend on the specific use case and the complexity of the avatar scene. Also the numbers vary on the actuall hardware used. The following table gives some guidance.
Component |
Minimum CPU |
Recommended CPU |
Minimum RAM |
Recommended RAM |
Recommended GPU |
Minimum GPU RAM |
Recommended GPU RAM |
Recommended Storage |
|---|---|---|---|---|---|---|---|---|
Audio2Face-3D |
4 cores |
8 cores |
4 GB |
8 GB |
Any NVIDIA GPU with compute capability |
10 GB |
12 GB |
10 GB |
Animation Graph |
< 1 core |
1 core |
1 GB |
4 GB |
< 1 NVIDIA RTX-compatible GPU |
1 GB |
1 GB |
5 GB |
Omniverse Renderer |
2 cores |
6 cores |
24 GB |
32 GB |
1 NVIDIA RTX-compatible GPU |
8 GB |
12 GB |
7 GB |
Total |
4 cores |
15 cores |
29 GB |
44 GB |
1-2 NVIDIA RTX-compatible GPU |
19 GB |
25 GB |
22 GB |
Download UCS App Files#
Download the following files and place them in an empty ucs_apps directory:
Update the animation_pipeline_params.yaml file’s avatar-renderer-a.livestream.host property to use your own IP address (hostname -I will show you your IP address). Do the same for avatar-renderer-b.
Note
The above configuration assumes you have access to two GPUs, and it deploys one renderer per GPU.
Adapt UCS App for Single Renderer & GPU#
To reduce the required GPU resources, you can adapt the UCS app configuration to run one renderer on a single GPU by commenting out all sections and lines that contain avatar-renderer-b:
animation_pipeline.yaml: (lines: 49-53, 69-70)
animation_pipeline_values.yaml: (lines: 38-56)
animation_pipeline_params.yaml: (lines: 62-73)
Configure the Resource Downloader#
Both the Animation Graph microservice and the Omniverse Renderer microservice use a USD scene configuration. By default, the UCS app configures the microservices to download the avatar scene from NGC. However, there are also alternative methods to download resources, and you can also create your own resource downloader init container, as described in the Resource Downloader section.
Build UCS App#
rm -rf _build/animation_pipeline*
ucf_app_builder_cli app build animation_pipeline.yaml animation_pipeline_params.yaml -o _build/animation_pipeline
Deploy UCS App#
name=animation-pipeline
namespace=$name
kubectl create namespace $namespace
kubectl create secret docker-registry ngc-docker-reg-secret --docker-server=nvcr.io --docker-username='$oauthtoken' --docker-password=$NGC_CLI_API_KEY -n $namespace
kubectl create secret generic ngc-api-key-secret --from-literal=NGC_CLI_API_KEY=$NGC_CLI_API_KEY -n $namespace
Then, start the deployment:
helm upgrade --install --cleanup-on-fail --namespace $namespace $name _build/animation_pipeline/ -f _build/animation_pipeline/values.yaml -f animation_pipeline_values.yaml
Check the pod states:
watch kubectl get pods -n $namespace
Starting all the pods will take up to 30 min. You need to wait until they are all indicated as ready. If the pods fail to start up, check the troubleshooting section.
Prepare Communication to Pods#
We’re not installing curl or wget anymore in the images. Therefore you can’t use kubectl exec ... anymore to call the API endpoints.
To talk with the API, you now need to use kubectl port-forward.
As the kubectl port-forward command doesn’t exit until it is shut down, you either need to run it in separate shells or run them in the background.
In this example, we are running them in separate shells.
kubectl port-forward -n $namespace ia-animation-graph-microservice-deployment-0 8020:8020
# if you have only a single renderer running
kubectl port-forward -n $namespace ia-omniverse-renderer-microservice-deployment-0 8021:8021
# or two renderers
kubectl port-forward -n $namespace avatar-renderer-a-deployment-0 8021:8021
kubectl port-forward -n $namespace avatar-renderer-b-deployment-0 8022:8021
Prepare Streaming#
We will create two independent avatar stream instances.
Add two different stream ids for Animation Graph microservice:
stream_id_1=$(uuidgen)
curl -X POST -s http://localhost:8020/streams/$stream_id_1
# If using two renderers:
stream_id_2=$(uuidgen)
curl -X POST -s http://localhost:8020/streams/$stream_id_2
Verify logs that “Sending Animation Data to output for stream_id <stream_id_#>” is present:
kubectl logs -n $namespace -c ms ia-animation-graph-microservice-deployment-0
Add stream ids to Omniverse Renderer microservices:
curl -X POST -s http://localhost:8021/streams/$stream_id_1
# If using two renderers:
curl -X POST -s http://localhost:8022/streams/$stream_id_2
Verify that logs “Rendering animation data” are present in both renderer microservices:
kubectl logs -n $namespace -c ms avatar-renderer-a-deployment-0
# If using two renderers:
kubectl logs -n $namespace -c ms avatar-renderer-b-deployment-0
Setup and Start Gstreamer#
We will use Gstreamer to catch the image and audio output streams to visualize the two avatar scenes.
Install Gstreamer plugin:
sudo apt-get install gstreamer1.0-plugins-bad gstreamer1.0-libav
Use the ports specified in ucs_apps/animation_pipeline_params.yaml. Default ports are 9020/9030 for video and 9021/9031 for audio.
Run each of the following commands in their own terminal (if you changed the livestream.audioSampleRate, make sure to set the clock-rate to the same value):
# Avatar stream 1
gst-launch-1.0 -v udpsrc port=9020 caps="application/x-rtp" ! rtpjitterbuffer drop-on-latency=true latency=20 ! rtph264depay ! h264parse ! avdec_h264 ! videoconvert ! fpsdisplaysink text-overlay=0 video-sink=autovideosink
gst-launch-1.0 -v udpsrc port=9021 caps="application/x-rtp,clock-rate=16000" ! rtpjitterbuffer ! rtpL16depay ! audioconvert ! autoaudiosink sync=false
# Avatar stream 2 (if using two renderers)
gst-launch-1.0 -v udpsrc port=9030 caps="application/x-rtp" ! rtpjitterbuffer drop-on-latency=true latency=20 ! rtph264depay ! h264parse ! avdec_h264 ! videoconvert ! fpsdisplaysink text-overlay=0 video-sink=autovideosink
gst-launch-1.0 -v udpsrc port=9031 caps="application/x-rtp,clock-rate=16000" ! rtpjitterbuffer ! rtpL16depay ! audioconvert ! autoaudiosink sync=false
Alternatively, you can also record the audio and video streams together to a file (if you changed the livestream.audioSampleRate, make sure to set the clock-rate to the same value):
# Avatar stream 1
gst-launch-1.0 -e -v udpsrc port=9021 caps="application/x-rtp,clock-rate=16000" ! rtpjitterbuffer ! rtpL16depay ! audioconvert ! matroskamux name=mux ! filesink location="stream_id_1.mkv" udpsrc port=9020 caps="application/x-rtp" ! rtpjitterbuffer drop-on-latency=true latency=20 ! rtph264depay ! h264parse ! mux.
# Avatar stream 2 (if using two renderers)
gst-launch-1.0 -e -v udpsrc port=9031 caps="application/x-rtp,clock-rate=16000" ! rtpjitterbuffer ! rtpL16depay ! audioconvert ! matroskamux name=mux ! filesink location="stream_id_2.mkv" udpsrc port=9030 caps="application/x-rtp" ! rtpjitterbuffer drop-on-latency=true latency=20 ! rtph264depay ! h264parse ! mux.
Test Animation Graph Interface#
Back in your main terminal, let’s set a new posture for avatar 1:
curl -X PUT -s http://localhost:8020/streams/$stream_id_1/animation_graphs/avatar/variables/posture_state/Talking
or change the avatar’s position:
curl -X PUT -s http://localhost:8020/streams/$stream_id_1/animation_graphs/avatar/variables/position_state/Left
or start a gesture:
curl -X PUT -s http://localhost:8020/streams/$stream_id_1/animation_graphs/avatar/variables/gesture_state/Pulling_Mime
or trigger a facial gesture:
curl -X PUT -s http://localhost:8020/streams/$stream_id_1/animation_graphs/avatar/variables/facial_gesture_state/Smile
You can explore the OpenAPI interface of the Animation Graph microservice (http://localhost:8020/docs) or Omniverse Renderer microservice (http://localhost:8021/docs).
You can find all valid variable values here: Default Animation Graph.
Test Audio2Face-3D#
In separate tabs, activate port-forwarding:
kubectl port-forward -n $namespace a2f-with-emotion-a2f-deployment-XXX 50010:50010
kubectl port-forward -n $namespace ia-animation-graph-microservice-deployment-0 8020:8020
Note that the Audio2Face-3D pod has a random suffix, which must be adapted in the above command.
Let’s now take a sample audio file to feed into Audio2Face-3D to drive the facial speaking animation.
Normally, you would send audio to Audio2Face-3D through its gRPC API. For convenience, a python script allows you to do this through the command line. Follow the steps to setup the script.
The script comes with a sample audio file that is compatible with Audio2Face-3D. Run the following command to send the sample audio file to Audio2Face-3D:
Follow this Audio2Face-3D link to get more information.
Note
The audio formats in the Audio2Face-3D microservice, Animation Graph microservice, and Omniverse Renderer microservice need to be configured in the same way.
python3 validate.py -u 127.0.0.1:50010 -i $stream_id_1 Mark_joy.wav
You can interrupt the request while the avatar is speaking with the HTTP API interruption endpoint.
For simplicity, you can replace the randomly generated request-id in the validate.py on line 46 by a hardcoded one (e.g. request_id="123") and use it in the following request:
curl -X DELETE -s http://localhost:8020/streams/$stream_id/requests/<request-id>
Extract Crash Dumps#
List the directory, where the crash dumps are saved:
kubectl exec -n $namespace -c ms avatar-renderer-a-deployment-0 -- ls -alh /home/interactive-avatar/asset
Copy the crash dumps (<uuid>.zip) to the local filesystem:
kubectl cp -n $namespace avatar-renderer-a-deployment-0:/home/interactive-avatar/asset/<uuid>.dmp.zip -c ms <uuid>.dmp.zip
Copy to a different machine if needed:
scp.exe -r <username>@<hostname>:<folder_path>/*.zip .\Downloads\
Change Avatar Scene#
To modify or switch out the default avatar scene, you can use the Avatar Configurator.
Download and unpack it and start it by running ./run_avatar_configurator.sh.
Once it has successfully started (the first time it takes longer to compile shaders), you can create your custom new scene and save it.
Now, you need to upload the new scene to NGC (see Uploading a Version to the NGC Resource) and adapt the related links in the UCS application configuration and redeploy it.
Clean up: Remove Streams#
You can clean up the streams using the following commands:
curl -X DELETE -s http://localhost:8021/streams/$stream_id_1
curl -X DELETE -s http://localhost:8020/streams/$stream_id_1
# If using two renderers:
curl -X DELETE -s http://localhost:8021/streams/$stream_id_2
curl -X DELETE -s http://localhost:8020/streams/$stream_id_2
Afterwards, you can shut down the kubectl port-forward commands from Prepare Communication to Pods.