Tokkio Architecture
Overview
The Tokkio end-to-end pipeline is an integration of multiple microservices. The diagram below depicts an overview of the interconnections between various microservices within Tokkio for a cloud deployment. Each component within Tokkio is modeled as a microservice, giving it the flexibility for changes or customizations as suited.
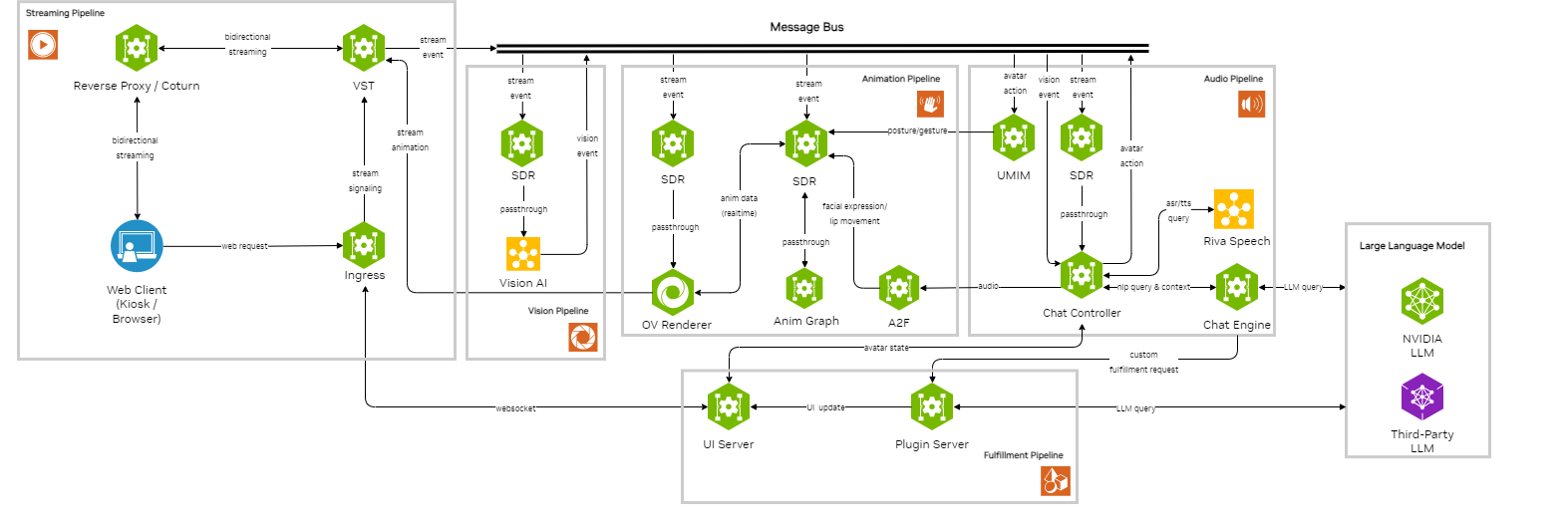
The Entire Tokkio pipeline can be roughly divided into five major pipelines: Streaming, Animation, Vision, Audio, and Fulfillment.
The streaming pipeline is initiated through a web client (Google Chrome supported) with Tokkio UI rendered and permissions granted for Camera and Microphone. The video and audio data is transmitted back and forth from and to VST (Video Storage Toolkit) via WebRTC protocol once the initial signaling procedure has been performed through REST API at the ingress gateway. The transmission of data is facilitated through a reverse proxy or a TURN server to bypass any security measures that prevent a direct connection.
The vision pipeline takes in a RTSP stream provisioned through VST for inference, and outputs realtime metadata on each frame, such as face tracking, expression & gesture detection, and attention detection. Vision events are generated in the process and notify the rest of the system on notable changes within the field of view, such as a person enters or leaves the scene.
The audio pipeline is mainly responsible for driving the conversation with the end-user. It centralizes and correlates all the metadata associated with the transaction contexts. The pipeline interprets the user’s intention by leveraging the Riva speech ASR technology. The user intentions are then compiled into explicit postures and gestures and fed into the animation pipeline. Optionally, user intentions can also be fed into the fulfillment pipeline for any custom business logic, such as a QSR (quick service restaurant) use case. All the natural language queries and contexts are passed into a large language model to generate human-like responses. The transcripts are then compiled into audio chunks by again leveraging the RIVA speech TTS technology and fed into animation pipeline for further processing.
The animation pipeline enable users to puppeteer avatars using voice commands and gestures in video streaming contexts. Audio2Face to animate facial expressions and lip movements, and offers a collection of APIs to control body motion and position based on the Animation Graph technology to produce immersive avatar visuals. The end product is then piped into VST and eventually lands on user’s web client.
The fulfillment pipeline is a part of the Tokkio QSR (Quick Service Restaurant) reference implementation and are specifically designed to a render application-specific implementation. The user directly interacts with fulfillment pipeline through a client. Any user input from the UI will be transmitted to the backend by going through the ingress gateway, which performs the necessary authentication and capacity check. This pipeline can be customized or completely swapped out depending on the use cases.
You may find more details about the components below:
Deployment & Scaling
Tokkio is an event-based system modeled as a cluster of microservices and deployed at scale on a K8s platform (on-premise or CSP).
Types of Microservices
Every microservice is categorized into stateful vs stateless depending on its processing pattern. Stateful microservices are the ones that do continuous real-time processing on video or audio streams such as Bot Controller, Anim A2F, VisionAI, and etc, therefore having to maintain its intrinsic states within the memory to avoid long latency and inconsistency. A stateful microservice is modeled as a StatefulSet resource in Kubernetes.
Stateless microservices are generally the ones that are more permissive in terms of latency and mainly serve memoryless REST requests, therefore it persists its state externally either in a cache or a disk-based database. Stateless microservices include: Fulfillment, Cart Manager, Menu API, etc. A stateless microservice is modeled as a Deployment resource in Kubernetes
The difference needs to be drawn here between the two types of microservice as their scaling patterns are drastically different.
Communicate Pattern & Message Bus
Tokkio deploys a single REDIS message bus for all microservices. A source event is generated when a client connects or disconnects a WebRTC stream from the VST server. All subscribers of the message bus react accordingly when a source event occurs. For example, DeepStream Vision AI service subscribes to the VST source event, from which it retrieves the RTSP stream URL and spawn a worker process to handle the stream.
Scaling and Dynamic Routing
As mentioned in the previous section, microservices can be categorized into stateful and stateless. Scaling a stateless is as simple as increasing the replicas to its deployment resource, meanwhile keeping all replicas of the same microservice within the same message bus consumer group in order to dish out a subnet of messages to all the clients.
However, things can get a little bit tricky when we start scaling stateful microservices. As a stateful microservice maintains its state internally for the duration of a session. A state generated by a specific user session shares the same lifecycle with the stateful microservice. In the event of having more than one replica of the same microservice running, the source event will be picked up by one of the replicas, and the traffic needs to be correctly routed to the same replica for the lifetime of the user session.
As a result, we need information about the relation between a workload object and its processing worker, in another word: a map between a specific stream id to the statefulset replica index, e.g., Bot controller pod 0 is currently processing stream id xxx. We need this information as we need to make dynamic routing decision on incoming requests so that they land on the correct replica where the workload is currently being processed.
Both the workload distribution and traffic routing is handled by NVIDIA SDR (Stream Distribution and Routing), which hides the complexity of scaling from developers. To scale a stateful microservice, developers only have to integrate with SDR. Details provided in the SDR documentation (Stream Distribution & Routing).
Deployment
Tokkio application now is capable of running up to 3 concurrent workflows on a single node with at least up to 4 GPUs. This means you now can launch up to 3 separate sessions targeting the same backend endpoint. Each interaction with the Avatar is completely independent from the other, and one user’s access will not lock out others given that the capacity is not fully occupied.
We now support All the following types of GPUs: T4, A10, L4. Please refer to the CSP setup guides section on more information about specific setups unique to each cloud platform: AWS, Azure, GCP
The capacity check happens at the ingress microservice that queries the media service for the number of active WebRTC connections when a streaming request is received. It rejects the request if the occupancy reaches capacity.
To configure the max capacity of the system, you can specify the following section in the UCS app parameter manifest:
tokkio-ingress-mgr:
maxNumSession: "3"
avatar-renderer:
ucfVisibleGpus: [1,2,3]
replicas: 3
renderer-sdr:
sdrMaxReplicas: "3"
By default, the reference Tokkio app assumes a 4-GPU system as its deployment platform, so the capacity cannot go above 3 concurrent streams.
If a node has more than 4 GPUs, a user is able to run the app with more concurrent streams. The rule of thumb is that the max number of concurrent streams should always equal to the number of GPU available minus 1. For example, 8 GPUs can run up to 7 concurrent streams on a single node.
The UCS app parameter manifest will look something like this:
tokkio-ingress-mgr:
maxNumSession: "7"
avatar-renderer:
ucfVisibleGpus: [1,2,3,4,5,6,7]
replicas: 7
renderer-sdr:
sdrMaxReplicas: "7"
animation-graph:
maxStreamCapacity: 7
vms:
configs:
vst_config.json:
network:
max_webrtc_in_connections: 7
Limitation
GPU allocation is hardcoded within the Tokkio application parameters at the moment given the assumption that all deployments will happen with a controlled on-premises environment or pre-configured CSP platforms. We will be providing additional features in the upcoming release to address this limitation and give more flexibility in terms of deployment pattern and hardware options.