DevOps Engineer#
Now that the Data Scientist has successfully exported the trained model to a format that Triton can use, the DevOps Engineer will deploy the model on the VM. This DevOps Engineer focuses on ensuring that the Triton Inference Server is up and running, ready for use by the end-user.
The following steps are outlined below and will be executed inside the VM:
Check Triton Inference Server health.
Validation
Check Triton Inference Server Health#
You will now need to start the Triton Inference Server on the VM using the command below.
sh ~/triton-startup.sh
Triton HTTP and gRPC service should be running on the Triton Inference Server VM. To check the server’s health, run the curl command in a different SSH session inside the VM.
curl -m 1 -L -s -o /dev/null -w %{http_code} http://localhost:8001/v2/health/ready
It should output 200 OK HTTP code.
Validation#
Getting the Triton Client Libraries and Examples#
To communicate with the Triton Inference Server, the software layer exposes client libraries. The gPRC and HTTP libraries are available as Python packages which can be installed using pip.
1pip install nvidia-pyindex
2pip install tritonclient[all]
Note
Pip install is only available on Linux. We are using all installs on the HTTP/REST and GRPC client libraries.
Using Triton gRPC client to run Inference#
Your Jupyer notebook container has the Triton server client libraries, so we will use the container to send inference request to the Trition Inference Server container.
python /workspace/bert/triton/run_squad_triton_client.py --triton_model_name=bert --triton_model_version=1 --vocab_file=/workspace/bert/data/download/finetuned_large_model_SQUAD1.1/vocab.txt --predict_batch_size=1 --max_seq_length=384 --doc_stride=128 --triton_server_url=localhost:8001 --context="A Complex password should atleaset be 20 characters long" --question="How long should a good password generally be?"
Note
The script points to a Triton Server running on localhost on port 8001 (the triton gRPC server). We specify context, i.e., a paragraph which the BERT will use to answer the question (in this case, It is a paragraph from IT help desk about the best practices to use while picking a password. Then you can ask a question to the BERT model in this case it is: What are the common substitutions for letters in password?”)
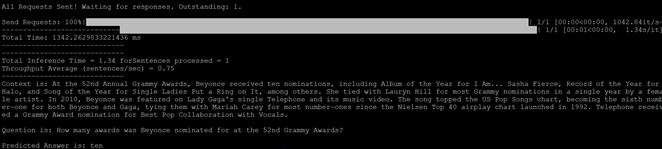
The console output shows that the predicted answer is @ for a, 1 for l.