Stable Diffusion XL NIM
Important
NVIDIA NIM currently is in limited availability, sign up here to get notified when the latest NIMs are available to download.
Generate high-resolution realistic images based on text prompts. Stabilityai/stable-diffusion-xl-1.0 is a generative text-to-image model that can synthesize photorealistic images from a text prompt.
Use Stable Diffusion XL NIM to:
Generate high resolution images (1024x1024 pixels).
Use complex and diverse text inputs, such as multiple sentences, questions, or commands for generating images.
Create multiple image variations with different styles, colors, or perspectives.
Produce images that are relevant to the real world, such as objects, scenes, or faces.
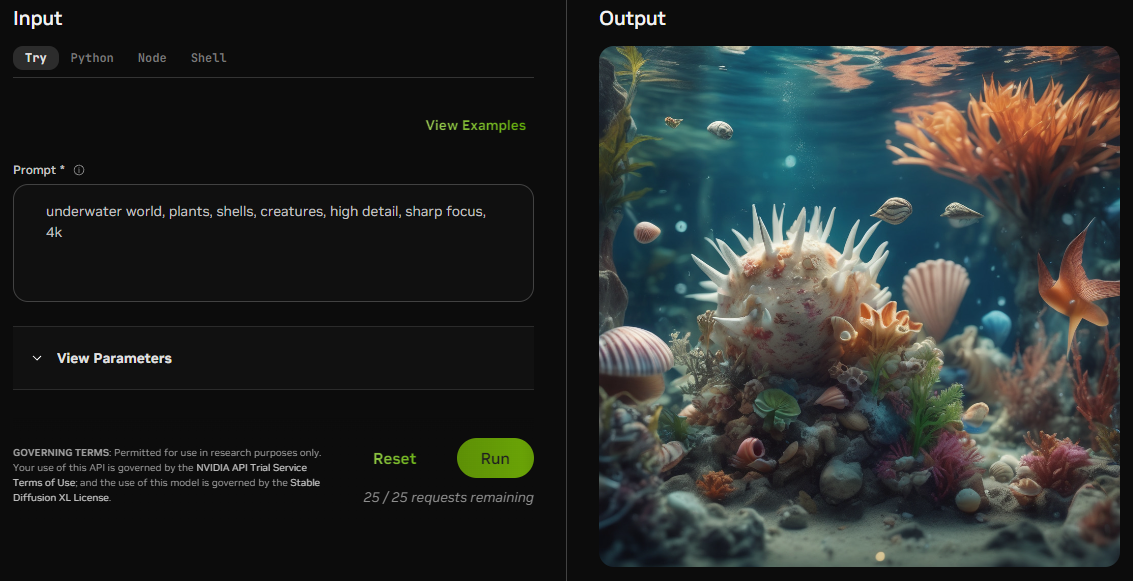
An example text prompt for an AI-generated image
Note
A more detailed description of the model can be found in the Model Card.
Model Specific Requirements
The following are specific requirements for Stable Diffusion XL NIM.
Important
Please refer to NVIDIA NIM documentation for necessary hardware, operating system, and software prerequisites if you have not done so already.
Hardware
Target GPUs: L40(S), A100 or H100 GPUs
Minimum available GPU Memory (VRAM): 24GB
Minimum available RAM: 48GB
Software
Minimum NVIDIA Driver Version: 535
Once the above requirements have been met, you will download the model and then use the Quickstart guide to pull the NIM container, build the TensorRT (TRT) engines and run the NIM.
Download the Model
For the commercial use of the model, you need to receive the license from stability.ai.
Use the following commands to download (the size of the downloaded files is ~13.8GB):
Note
You can copy all the commands to your terminal at once
1mkdir -p sd-model-store sd-model-store/framework_model_dir sd-model-store/framework_model_dir/xl-1.0 2 3mkdir -p sd-model-store/framework_model_dir/xl-1.0/XL_BASE 4 5mkdir -p sd-model-store/framework_model_dir/xl-1.0/XL_BASE/scheduler 6curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/scheduler/scheduler_config.json --output sd-model-store/framework_model_dir/xl-1.0/XL_BASE/scheduler/scheduler_config.json 7 8mkdir -p sd-model-store/framework_model_dir/xl-1.0/XL_BASE/tokenizer 9curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/tokenizer/merges.txt --output sd-model-store/framework_model_dir/xl-1.0/XL_BASE/tokenizer/merges.txt 10curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/tokenizer/special_tokens_map.json --output sd-model-store/framework_model_dir/xl-1.0/XL_BASE/tokenizer/special_tokens_map.json 11curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/tokenizer/tokenizer_config.json --output sd-model-store/framework_model_dir/xl-1.0/XL_BASE/tokenizer/tokenizer_config.json 12curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/tokenizer/vocab.json --output sd-model-store/framework_model_dir/xl-1.0/XL_BASE/tokenizer/vocab.json 13 14mkdir -p sd-model-store/framework_model_dir/xl-1.0/XL_BASE/tokenizer_2 15curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/tokenizer_2/merges.txt --output sd-model-store/framework_model_dir/xl-1.0/XL_BASE/tokenizer_2/merges.txt 16curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/tokenizer_2/special_tokens_map.json --output sd-model-store/framework_model_dir/xl-1.0/XL_BASE/tokenizer_2/special_tokens_map.json 17curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/tokenizer_2/tokenizer_config.json --output sd-model-store/framework_model_dir/xl-1.0/XL_BASE/tokenizer_2/tokenizer_config.json 18curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/tokenizer_2/vocab.json --output sd-model-store/framework_model_dir/xl-1.0/XL_BASE/tokenizer_2/vocab.json 19 20mkdir -p sd-model-store/framework_model_dir/xl-1.0/XL_BASE/unet 21curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/unet/config.json --output sd-model-store/framework_model_dir/xl-1.0/XL_BASE/unet/config.json 22curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/unet/diffusion_pytorch_model.fp16.safetensors --output sd-model-store/framework_model_dir/xl-1.0/XL_BASE/unet/diffusion_pytorch_model.fp16.safetensors 23 24mkdir -p sd-model-store/framework_model_dir/xl-1.0/XL_REFINER 25 26mkdir -p sd-model-store/framework_model_dir/xl-1.0/XL_REFINER/scheduler 27curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/scheduler/scheduler_config.json --output sd-model-store/framework_model_dir/xl-1.0/XL_REFINER/scheduler/scheduler_config.json 28 29mkdir -p sd-model-store/framework_model_dir/xl-1.0/XL_REFINER/tokenizer_2 30curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/tokenizer_2/merges.txt --output sd-model-store/framework_model_dir/xl-1.0/XL_REFINER/tokenizer_2/merges.txt 31curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/tokenizer_2/special_tokens_map.json --output sd-model-store/framework_model_dir/xl-1.0/XL_REFINER/tokenizer_2/special_tokens_map.json 32curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/tokenizer_2/tokenizer_config.json --output sd-model-store/framework_model_dir/xl-1.0/XL_REFINER/tokenizer_2/tokenizer_config.json 33curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/tokenizer_2/vocab.json --output sd-model-store/framework_model_dir/xl-1.0/XL_REFINER/tokenizer_2/vocab.json 34 35mkdir -p sd-model-store/framework_model_dir/xl-1.0/XL_REFINER/vae 36curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/vae/config.json --output sd-model-store/framework_model_dir/xl-1.0/XL_REFINER/vae/config.json 37curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/vae/diffusion_pytorch_model.fp16.safetensors --output sd-model-store/framework_model_dir/xl-1.0/XL_REFINER/vae/diffusion_pytorch_model.fp16.safetensors 38 39### Download Optimized ONNX files 40mkdir -p sd-model-store/onnx sd-model-store/onnx/xl-1.0 41 42mkdir -p sd-model-store/onnx/xl-1.0/XL_BASE 43 44mkdir -p sd-model-store/onnx/xl-1.0/XL_BASE/clip.opt 45curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-1.0-tensorrt/resolve/main/sdxl-1.0-base/clip.opt/model.onnx --output sd-model-store/onnx/xl-1.0/XL_BASE/clip.opt/model.onnx 46 47mkdir -p sd-model-store/onnx/xl-1.0/XL_BASE/clip2.opt 48curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-1.0-tensorrt/resolve/main/sdxl-1.0-base/clip2.opt/model.onnx --output sd-model-store/onnx/xl-1.0/XL_BASE/clip2.opt/model.onnx 49 50mkdir -p sd-model-store/onnx/xl-1.0/XL_REFINER 51 52mkdir -p sd-model-store/onnx/xl-1.0/XL_REFINER/clip2.opt 53curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-1.0-tensorrt/resolve/main/sdxl-1.0-refiner/clip2.opt/model.onnx --output sd-model-store/onnx/xl-1.0/XL_REFINER/clip2.opt/model.onnx 54 55mkdir -p sd-model-store/onnx/xl-1.0/XL_REFINER/unetxl.opt 56curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-1.0-tensorrt/resolve/main/sdxl-1.0-refiner/unetxl.opt/model.onnx --output sd-model-store/onnx/xl-1.0/XL_REFINER/unetxl.opt/model.onnx 57curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-1.0-tensorrt/resolve/main/sdxl-1.0-refiner/unetxl.opt/6e186582-2d74-11ee-8aa7-0242c0a80102 --output sd-model-store/onnx/xl-1.0/XL_REFINER/unetxl.opt/6e186582-2d74-11ee-8aa7-0242c0a80102 58curl -L https://huggingface.co/stabilityai/stable-diffusion-xl-1.0-tensorrt/resolve/main/sdxl-1.0-refiner/unetxl.opt/6ed855ee-2d70-11ee-af8e-0242c0a80101 --output sd-model-store/onnx/xl-1.0/XL_REFINER/unetxl.opt/6ed855ee-2d70-11ee-af8e-0242c0a80101
To filter possible inappropriate and harmful images, please download the Safety Checker (the size of the downloaded files is ~1.2GB):
Note
You can copy all the commands to your terminal at once
1mkdir -p sd-model-store sd-model-store/framework_model_dir sd-model-store/framework_model_dir/safety_checker 2curl -L https://huggingface.co/CompVis/stable-diffusion-safety-checker/resolve/main/config.json --output sd-model-store/framework_model_dir/safety_checker/config.json 3curl -L https://huggingface.co/CompVis/stable-diffusion-safety-checker/resolve/main/pytorch_model.bin --output sd-model-store/framework_model_dir/safety_checker/pytorch_model.bin
Quickstart Guide
The following Quickstart guide is provided to quickly get Stable Diffusion XL NIM up and running. Please refer to the detailed instruction section for additional information if needed.
Note
This page assumes Prerequisite Software (Docker, NGC CLI, NGC registry access) is installed and set up.
Pull the NIM container.
docker pull nvcr.io/nvidia/nim/genai_sd_nim:24.03
Build the TRT engines (it takes up to 25 min). They would be stored in $(pwd)/sd-model-store/trt_engines/xl-1.0.
1docker run --rm -it --gpus=1 \ 2 -v $(pwd)/sd-model-store:/sd-model-store \ 3 nvcr.io/nvidia/nim/genai_sd_nim:24.03 \ 4 bash -c "python3 build.py --model=sdxl"
Run NIM.
1docker run --rm -it --name sdxl-server \ 2 --runtime=nvidia --gpus=1 \ 3 -p 8000:8000 -p 8001:8001 -p 8002:8002 -p 8003:8003 \ 4 -v $(pwd)/sd-model-store/trt_engines:/model-store/ \ 5 -v $(pwd)/sd-model-store/framework_model_dir:/model-store/framework_model_dir \ 6 -e MODEL_NAME=sdxl \ 7 nvcr.io/nvidia/nim/genai_sd_nim:24.03
Wait until the health check returns 200 before proceeding.
curl -i -m 1 -L -s -o /dev/null -w %{http_code} localhost:8000/v2/health/ready
Request Inference from the local NIM instance.
1python3 -c " 2import json 3import base64 4import requests 5 6payload = json.dumps({ 7\"text_prompts\": [ 8 { 9 \"text\": \"a photo of an astronaut riding a horse on mars\" 10 } 11] 12}) 13 14response = requests.post(\"http://localhost:8003/infer\", data=payload) 15 16response.raise_for_status() 17 18data = response.json() 19 20img_base64 = data[\"artifacts\"][0][\"base64\"] 21 22img_bytes = base64.b64decode(img_base64) 23 24with open(\"output.jpg\", \"wb\") as f: 25 f.write(img_bytes) 26"
Detailed Instructions
This section provides additional details outside of the scope of the Quickstart Guide.
Pull Container Image
Container image tags follow the versioning of YY.MM, similar to other container images on NGC. You may see different values under “Tags:”. These docs were written based on the latest available at the time.
ngc registry image info nvcr.io/nvidia/nim/genai_sd_nim
1Image Repository Information 2 Name: genai_sd_nim 3 Display Name: genai_sd_nim 4 Short Description: GenAI SD NIM 5 Built By: NVIDIA 6 Publisher: 7 Multinode Support: False 8 Multi-Arch Support: False 9 Logo: 10 Labels: NVIDIA AI Enterprise Supported, NVIDIA NIM 11 Public: No 12 Last Updated: Mar 16, 2024 13 Latest Image Size: 11.15 GB 14 Latest Tag: 24.03 15 Tags: 16 24.03
Pull the container image
docker pull nvcr.io/nvidia/nim/genai_sd_nim:24.03
ngc registry image pull nvcr.io/nvidia/nim/genai_sd_nim:24.03
Build TRT Engines
The build script converts the PyTorch checkpoints into missing optimized ONNX files, builds TRT engines and measures a single e2e run performance. If some engines *.plan files are already located in the output directory the script will not rebuild them.
Note
If you run the engine’s build script on GPU with 24GB memory please add --no-perf-measurements flag. Once the engines are built you can run the build command without this flag to get performance measurements.
Note
If you’d like to try one option after another please add --force-rebuild flag. It will remove all the generated files from the previous build and enforce a new engine’s build.
Option 1 - FP16 Engines
Important
The build process takes up to 30 minutes.
1docker run --rm -it --gpus=1 \
2-v $(pwd)/sd-model-store:/sd-model-store \
3nvcr.io/nvidia/nim/genai_sd_nim:24.03 \
4bash -c "python3 build.py --model=sdxl"
Option 2 - FP16 Engines with int8 Quantization
Important
The build process takes up to 2.5 hours. It leverages AMMO (AlgorithMic Model Optimization) toolkit and achieves better performance than the first option (20%-40% speed up). To enable it simply add --int8.
1docker run --rm -it --gpus=1 \
2-v $(pwd)/sd-model-store:/sd-model-store \
3nvcr.io/nvidia/nim/genai_sd_nim:24.03 \
4bash -c "python3 build.py --model=sdxl --int8"
TRT engines would be stored in $(pwd)/sd-model-store/trt_engines/xl-1.0
Launch Microservice
Launch the container. Start-up may take a couple of minutes but the logs will read out Application startup complete. when the service is available.
1docker run --rm -it --name sdxl-server \
2--runtime=nvidia --gpus=1 \
3-p 8000:8000 -p 8001:8001 -p 8002:8002 -p 8003:8003 \
4-v $(pwd)/sd-model-store/trt_engines:/model-store/ \
5-v $(pwd)/sd-model-store/framework_model_dir:/model-store/framework_model_dir \
6-e MODEL_NAME=sdxl \
7nvcr.io/nvidia/nim/genai_sd_nim:24.03
Health and Liveness Checks
The container exposes health and liveness endpoints for integration into existing systems such as Kubernetes at /v2/health/ready and /v2/health/live. These endpoints only return an HTTP 200 OK status code if the service is ready or live, respectively. Run these in a new terminal.
curl -i -m 1 -L -s -o /dev/null -w %{http_code} localhost:8000/v2/health/ready
curl -i -m 1 -L -s -o /dev/null -w %{http_code} localhost:8000/v2/health/live
Run Inference
Here is an example API call (see API reference for details)
1import json
2import base64
3import requests
4
5payload = json.dumps({
6 "text_prompts": [
7 {
8 "text": "a photo of an astronaut riding a horse on mars"
9 }
10 ]
11})
12
13response = requests.post("http://localhost:8003/infer", data=payload)
14
15response.raise_for_status()
16
17data = response.json()
18
19img_base64 = data['artifacts'][0]["base64"]
20
21img_bytes = base64.b64decode(img_base64)
22
23with open("output.jpg", "wb") as f:
24 f.write(img_bytes)
Here is the sample output for the above snippet:

Note
Your output may be different since the seed parameter is not set.
Stopping the Container
When you’re done testing the endpoint, you can bring down the container by running docker stop sdxl-server in a new terminal.