Architecture Overview#
The NVIDIA AI-Q Blueprint is a multi-agent research system built on the NVIDIA NeMo Agent Toolkit. It uses a two-tier research architecture that keeps simple queries fast while reserving multi-phase deep research for complex topics.
System Flow#
The following diagram shows the full request lifecycle from user query to final response. Every query enters through the Intent Classifier, which decides whether to respond directly (meta), perform a quick tool-augmented lookup (shallow), or initiate a comprehensive multi-agent investigation (deep).
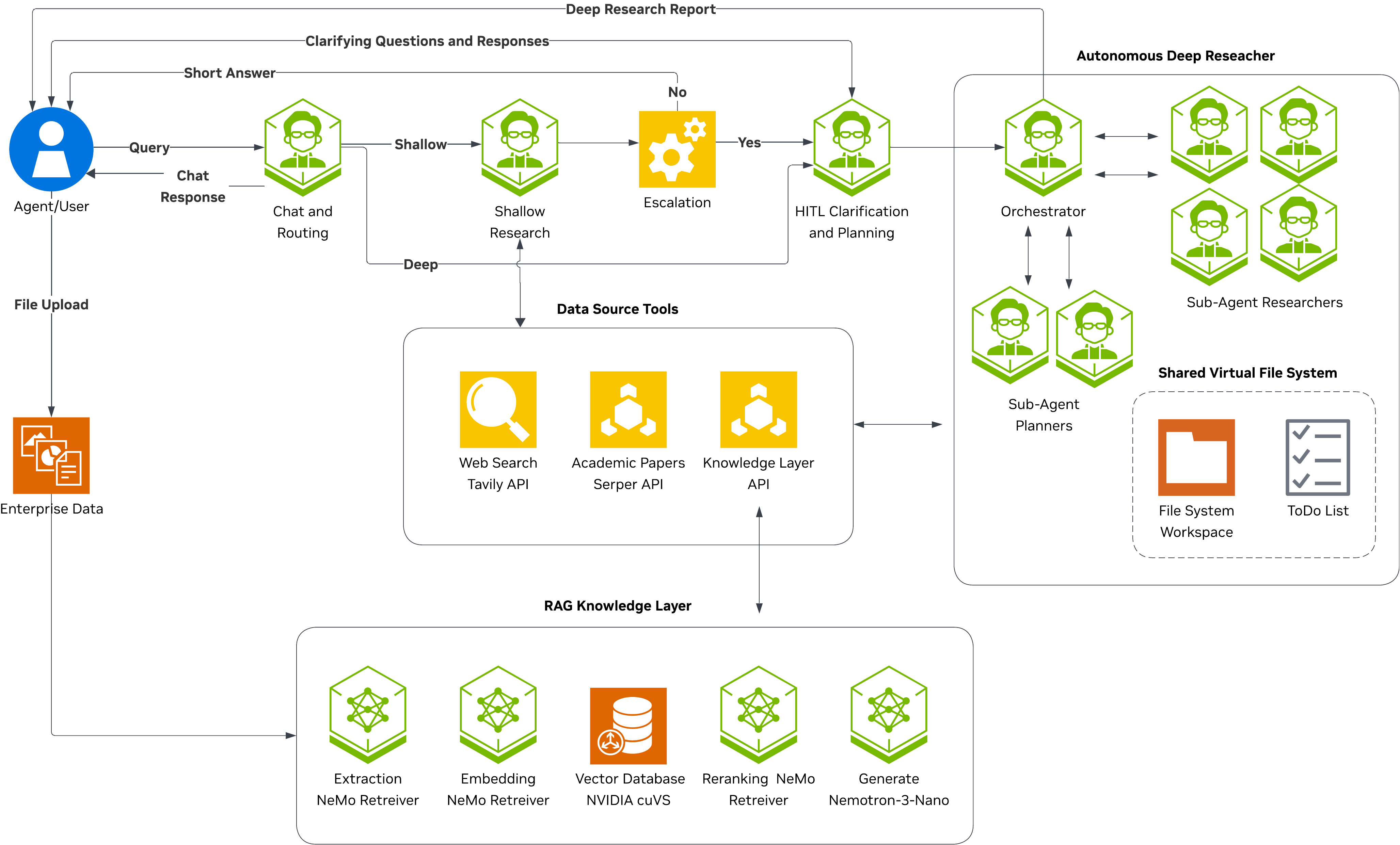
Core Components#
Component |
Role |
Location |
|---|---|---|
Single LLM call: classifies intent (meta/research) and depth (shallow/deep) |
|
|
HITL plan generation and approval before deep research |
|
|
Fast, bounded tool-augmented research |
|
|
Multi-phase research with planner and researcher subagents |
|
|
Chat Researcher Orchestrator |
LangGraph state machine coordinating all agents |
|
Orchestrator State Machine#
The ChatResearcherAgent builds a LangGraph StateGraph over ChatResearcherState with
four nodes and conditional edges:
Routing logic:
route_after_orchestration– After the intent classifier runs, the graph inspectsstate.user_intent.intent. Ifmeta, the response is already instate.messagesand the graph routes toEND. Ifresearch, it checksstate.depth_decision.decisionto chooseshallow_researchorclarifier.should_escalate– After shallow research completes, the graph evaluates whether the response warrants escalation to deep research. It checks for empty responses and escalation keywords (“unable to find”, “need more research”, “i don’t have enough information”) in the last 800 characters of the AI response. When escalation triggers, the graph routes to theclarifiernode (not directly todeep_research), so the user can review and approve a plan before deep research begins. Escalation is gated by theenable_escalationconfig flag.
ChatResearcherState#
The central state model carries data through the entire workflow:
Field |
Type |
Purpose |
|---|---|---|
|
|
Conversation history (LangGraph message reducer) |
|
|
Authenticated user information for personalization |
|
|
User-selected data source IDs for tool filtering. |
|
|
Classification result: |
|
|
Routing decision: |
|
|
Final report output from deep research |
|
|
Result from shallow research path |
|
|
Clarification log and approved plan context |
|
|
Preserved user query for deep research |
|
|
User-uploaded documents with summaries |
Design Decisions#
Two-tier routing: Keeps common queries fast (single tool-calling loop) while reserving multi-phase deep loops for complex cases. The intent classifier makes the routing decision in a single LLM call to minimize latency.
LangGraph state machine: Provides explicit, testable routing with conversation checkpointing using
InMemorySaveror persistent backends (SQLite, PostgreSQL).Subagent architecture: Deep research uses specialized subagents (planner, researcher) coordinated by an orchestrator, each with their own middleware stack and prompt templates.
Toolkit-independent agents: All agents receive dependencies through constructor injection for testability. NeMo Agent Toolkit registration is a thin layer in
register.pyfiles.Data source filtering: Tools are filtered per request based on
data_sources, allowing the same agent to operate over different knowledge backends without reconfiguration.Evaluation-driven defaults: Escalation thresholds and research loop counts are tuned through benchmarks (FreshQA, Deep Research Bench) and will evolve as evaluation scores improve.
Citation verification and auditability: Every research response passes through a deterministic post-processing pipeline that verifies citations against actually-retrieved sources, removes unverifiable or unsafe URLs, and produces an audit trail of all verification decisions. This is always enabled and applies to both shallow and deep research paths. See Deep Researcher – Citation Verification for details.
References#
Data Flow – request lifecycle, SSE events, async jobs